TDD: Use red-green refactoring to force AI to take small steps
Matt Pocock calls himself "the most stable way to improve the quality of agent output." An in-depth breakdown of why his TDD skill insists on vertical rather than horizontal red-green refactoring, how to avoid coupling between testing and implementation, and the new meaning of TDD in the AI era
The rate of feedback is your speed limit. Don't outrun your headlights.
Failure mode: "AI does the right thing, but it can't run"
The third failure mode in Matt's talk: The direction is right, but it doesn't work.
The most direct fix is to install feedback infrastructure for AI:
- TypeScript (no static typing is crazy)
- Allow LLM to access the browser and view the page by itself
- Automated testing
But Matt observed one thing: Even with this feedback installed, LLM doesn't work well. It tends to write 500 lines at a time and then think "oh I should type check that". This is what the Pragmatic Programmer calls outrunning your headlights - drive faster than the headlights can illuminate, and it's only a matter of time before you hit the wall.
"The rate of feedback is your speed limit, which means you should be testing as you go, taking small deliberate steps. And the AI by default is really not very good at that."
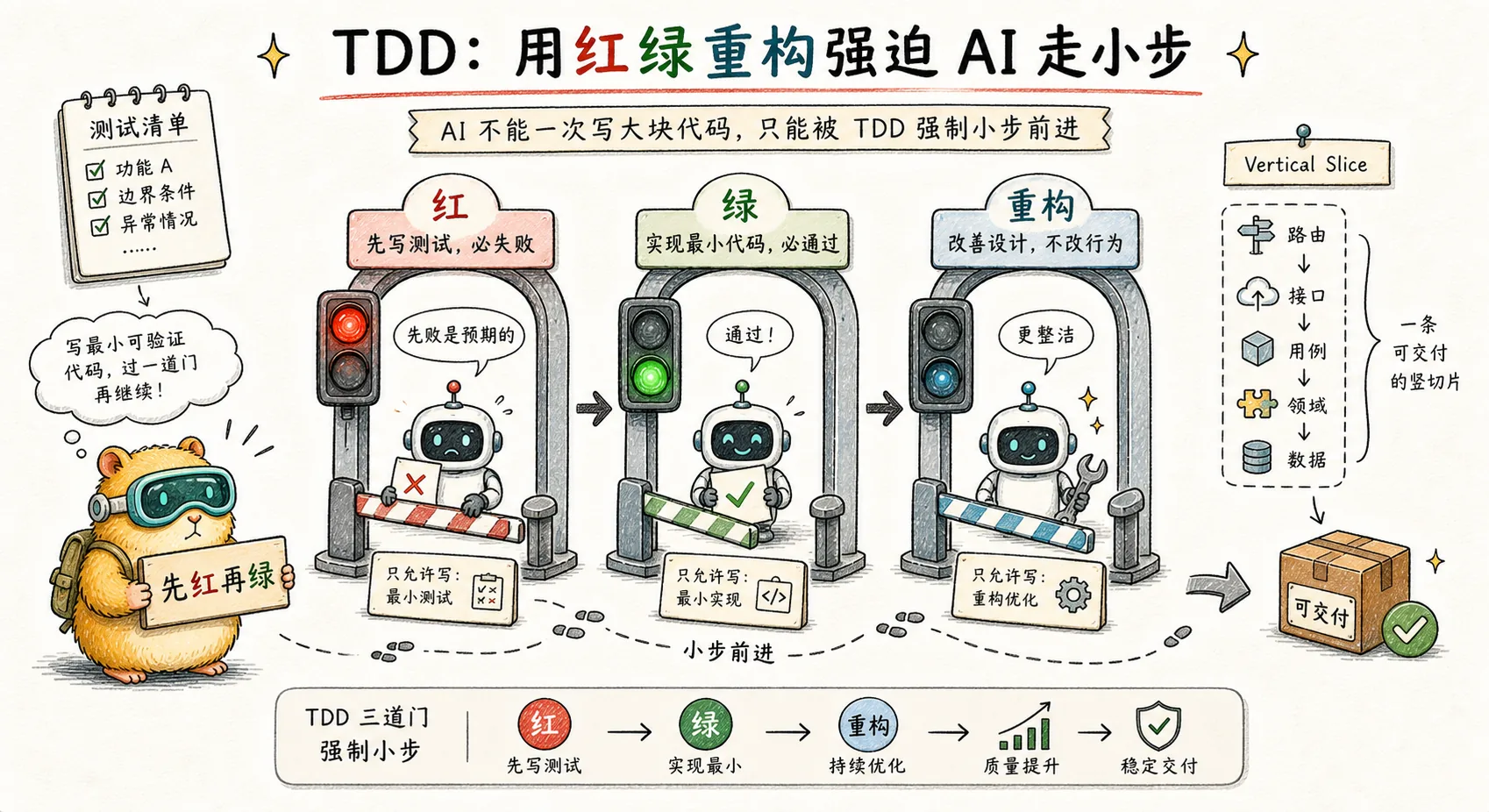
To fix this problem, you need to force the AI to stop step by step at the tool level. Matt's answer is TDD - Testing first can force checkpoints.
Classic Theory: Kent Beck’s Red-Green Reconstruction
The standard rhythm of TDD is defined by Kent Beck in his 2003 book "Test-Driven Development: By Example":
- RED: Write a failing test (describe what to do)
- GREEN: Write the smallest enough code to make the test pass
- REFACTOR: Improve code structure under test protection
Each loop is extremely short - on the order of minutes. There are automated checks (test pass/fail) at every step.
Matt directly follows this rhythm, but his SKILL.md spends a lot of time talking about an anti-pattern - this is the core.
Key anti-pattern: horizontally sliced red and green
Many people think that TDD means "write all the tests first, then write all the implementations." Matt directly says this is wrong in SKILL.md:
WRONG (horizontal slicing):
RED: test1, test2, test3, test4, test5
GREEN: impl1, impl2, impl3, impl4, impl5
RIGHT (vertical slicing via tracer bullets):
RED→GREEN: test1→impl1
RED→GREEN: test2→impl2
RED→GREEN: test3→impl3
...Why is horizontal wrong? SKILL.md gave three reasons:
- Tests written in bulk test imagined behavior, not actual behavior
- You end up testing the shape of things (data structures, function signatures) rather than user-facing behavior
- Tests become insensitive to real changes - they pass when behavior breaks, fail when behavior is fine
Human saying: Writing all the tests in one go is testing what's in your head, not the real code. When you write impl3, you realize that the design of test1 is wrong - but at this time, test2/test3/test4 are all coupled to the wrong design. Go back and make changes.
The correct approach is to test one implementation and then open the next pair after writing one pair. After each pair is completed and you have learned something from this implementation, the next pair of tests can be designed based on real experience - not imagination.
Skill full text structure
engineering/tdd/SKILL.md is one of the longest skills Matt has written because TDD itself has a lot of nuance. The core structure is as follows:
Philosophy
Core principle: Tests should verify behavior through public interfaces, not implementation details. Code can change entirely; tests shouldn't.
Good tests are integration-style: they exercise real code paths through public APIs. They describe what the system does, not how it does it. A good test reads like a specification.
Bad tests are coupled to implementation. They mock internal collaborators, test private methods, or verify through external means (like querying a database directly). The warning sign: your test breaks when you refactor, but behavior hasn't changed.
Remember a diagnosis: If you rename an internal function, the test will kneel down - then this test is testing the implementation rather than the behavior, which is a bad test.
Workflow (with checklist)
1. Planning
Align with users before writing code:
[ ] Confirm with user what interface changes are needed
[ ] Confirm with user which behaviors to test (prioritize)
[ ] Identify opportunities for deep modules (small interface, deep impl)
[ ] Design interfaces for testability
[ ] List the behaviors to test (not implementation steps)
[ ] Get user approval on the planKey question: "What should the public interface look like? Which behaviors are most important to test?"
"You can't test everything. Confirm with the user exactly which behaviors matter most. Focus testing effort on critical paths and complex logic, not every possible edge case."
This one is very counter-intuitive. By default, AI will want to exhaust all edge cases, but Matt emphasizes priority - not all behaviors are worth measuring, and focus firepower on the core path.
2. Tracer Bullet
Write a test that verifies one thing:
RED: Write test for first behavior → test fails
GREEN: Write minimal code to pass → test passesThis is a "tracer bullet" - shoot it first and check the sight. Matt emphasized that this work should be end-to-end - not to write the schema first, then write the API and then write the UI, but to cut the thinnest path that runs through the entire stack.
3. Incremental Loop
Repeat for each subsequent behavior RED→GREEN:
RED: Write next test → fails
GREEN: Minimal code to pass → passesRules:
- One test at a time
- Write only enough code to pass the current test
- Don’t predict future tests
- Testing focuses on observable behavior
"Don't predict" is particularly important. The AI can't help but think, "This function needs to support X anyway, let's add it by the way" - and this starts horizontal slicing.
4. Refactor
After all tests have passed, look for refactoring opportunities:
[ ] Extract duplication
[ ] Deepen modules (move complexity behind simple interfaces)
[ ] Apply SOLID principles where natural
[ ] Consider what new code reveals about existing code
[ ] Run tests after each refactor stepNever refactor while RED. Get to GREEN first.
Refactoring in red = changing tests and code at the same time = you don’t know whether the test is wrong or the code is wrong. Green first, then refactor.
Per-Cycle Checklist
At the end of each red and green cycle, Matt asks the AI to self-check:
[ ] Test describes behavior, not implementation
[ ] Test uses public interface only
[ ] Test would survive internal refactor
[ ] Code is minimal for this test
[ ] No speculative features addedThese five points are used to identify bad tests and over-implementation. AI self-checking can prevent most common mistakes.
Real use: from issue to PR
/tdd is the next step in Matt's workflow from /to-issues. Given a vertical slice issue, the process is:
你: 实现 issue #43
↓
/tdd
↓
Claude 读 issue acceptance criteria
↓
Claude 探索代码库 → 找到 CONTEXT.md → 用项目术语
↓
Planning 阶段:
- 列出准备改的接口
- 列出准备测的行为(按优先级排序)
- 让你点头
↓
Tracer Bullet:
- RED: 写第一个测试(基于 acceptance criteria 第 1 条)
- 跑测试,确认 fail
- GREEN: 写最小实现
- 跑测试,确认 pass
↓
Incremental Loop:
- 每个 acceptance criteria 一个 RED→GREEN
↓
Refactor:
- 看 deep module 提取机会
- 每次重构后跑全套测试
↓
PREvery red and green cycle the AI will stop and give you a status - "test fails"/"test passes, here's the diff". These pauses are the antidote to outrun headlights - the AI has no chance of laying out a thousand lines in one go.
About Mock: Matt’s strong opinion
SKILL.md specifically mentions the dangers of mocks - he also provides a separate mocking.md. Core ideas:
"Bad tests... mock internal collaborators."
Mock internal collaborators = 1:1 coupling between testing and implementation = testing team kneels when refactoring. Matt's preference is integration-style testing - try to use a real database (in-memory or testcontainers), real HTTP (MSW), and a real file system (tmp dir). Only mock at really expensive or unstable boundaries (like calls to the OpenAI API).
This is contrary to the current situation of many teams - most code libraries are full of unit tests, and there are more mocks than real code. Matt made a judgment in his speech: Good code base = easy to test code base. If you have to mock a bunch of things to test, it means there is a problem with the code structure, and you should change the architecture first (go to /improve-codebase-architecture).
The new significance of TDD in the AI era
When Kent Beck wrote that book 23 years ago, the core benefit of TDD was "people not writing wrong code." In the AI era, TDD has an additional meaning:
It is the only "success criterion" that AI can understand.
Matt quoted Karpathy’s words of wisdom later in his speech:
LLMs are exceptionally good at looping until they meet specific goals. Don't tell it what to do, give it success criteria and watch it go.
The best form of "success criteria" is test - it is machine-verifiable, binary, and cannot be quibbled with. Giving AI a test suite + "let it pass" is ten times more reliable than giving AI a description of requirements + "please implement".
So /tdd is not just a quality assurance tool - it is the input interface to the agent loop. Each red and green cycle is a complete "input → action → feedback". The AI learns the true situation of this implementation in the cycle, and the next cycle will be more accurate.
How to install and use
npx skills@latest add mattpocock/skillsCheck tdd + setup-matt-pocock-skills.
If you mainly use Codex now, take over the installation product to .agents/skills/, and write the project-level workflow, test commands, and issue tracker rules into AGENTS.md. The essence of Matt's /tdd is the red-green refactoring cycle, not tied to Claude Code.
Calling method:
- Direct:
/tdd- let it infer what to measure from the current conversation context - Fetch issue:
/tdd implement #43- it will fetch issue and then open it - Fix bug:
/tdd reproduce this bug then fix it- It will first write a failed test that can reproduce the bug, and then fix it
Notes
Not suitable for all tasks. One-off scripts, playground exploration code, UI fine-tuning - don't use TDD, it will slow down the pace. Matt himself said that TDD is suitable for code that "has lasting value and needs to be maintained."
Prepare the test infrastructure first. If the project has not installed the test framework (Vitest / Jest / Playwright, etc.), install it first and then use /tdd, otherwise it will install it for you first, but there are many questions in that step.
Don't let it automatically add e2e tests. e2e is slow and crisp, and the TDD rhythm is minute-level. /tdd defaults to integration test rather than e2e, but you can explicitly tell it "unit + integration only, not e2e".
The reconstruction phase is the easiest to get out of control. After the AI gets the GREEN status, it will refactor a bunch of things excitedly - stare at it, and run tests after each refactoring. This part is a high-risk area for AI deviation.
Reference resources
tdd/SKILL.md (源码)
Full TDD philosophy, horizontal-slice anti-pattern, complete workflow checklists, and per-cycle self-check.
Test-Driven Development: By Example
The original book that defined the red-green-refactor loop.
TDD with AI Coding(中文)
Companion piece exploring how TDD shifts meaning when AI writes the implementation.
Next article: Improve Codebase Architecture: Reconstruct shallow into deep modules - Periodic maintenance allows AI to run in your code base in the long term.
Comments
PRDs and Issues
The middle part of Matt Pocock's workflow - /to-prd turns the conversation into a PRD, and /to-issues cuts the PRD into vertically sliced issues that can be collected independently. In-depth interpretation of the new role of the two old concepts of "tracer bullet" and "vertical slice" in the AI era
Deepen code architecture
The final step in Matt Pocock’s workflow is to periodically scan the code base for “deepening opportunities.” Deeply understand John Ousterhout’s deep modules theory, Matt’s original deletion test, and why this skill is particularly needed in the AI era