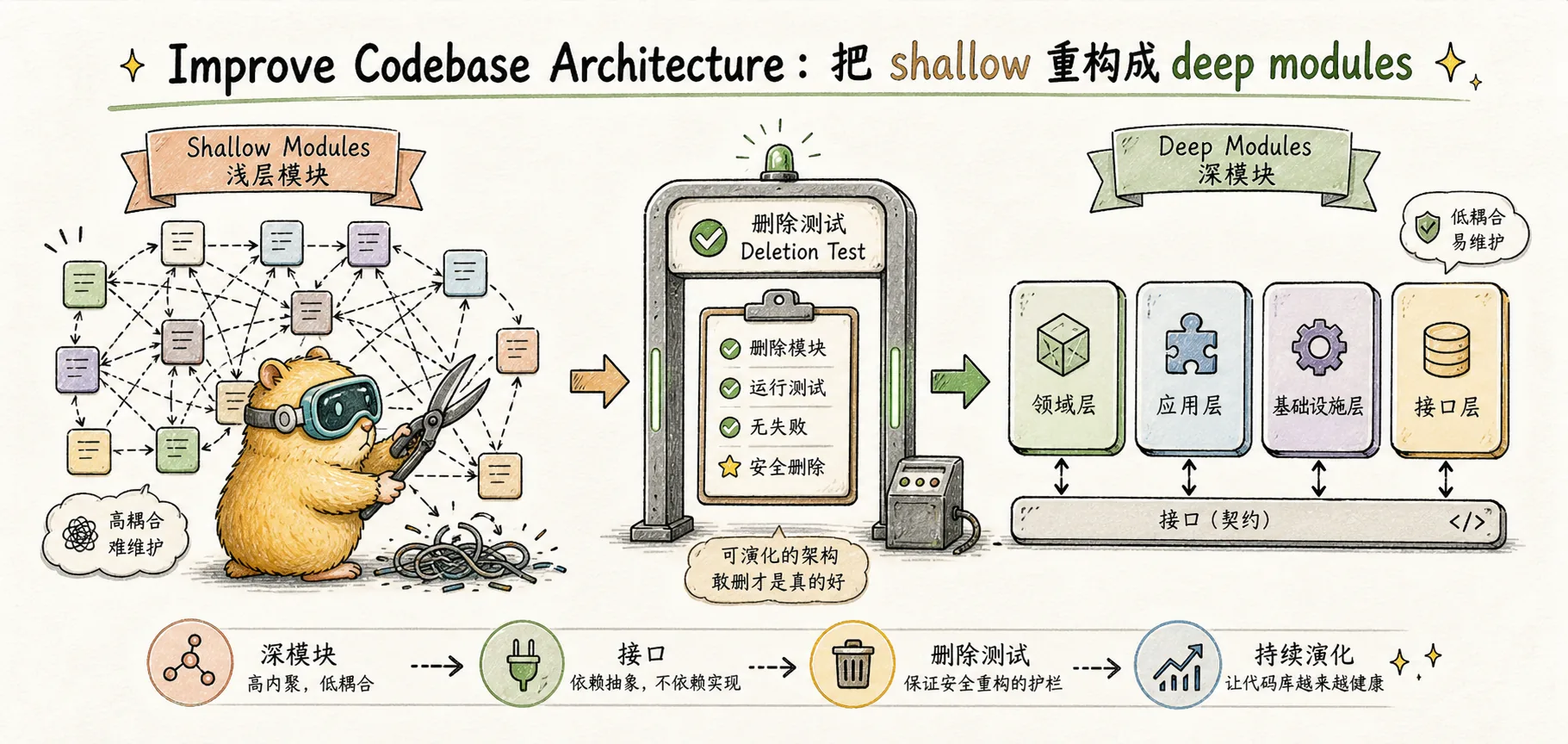
Improve Codebase Architecture: Restructure shallow into deep modules
The final step in Matt Pocock’s workflow is to periodically scan the code base for “deepening opportunities.” Deeply understand John Ousterhout’s deep modules theory, Matt’s original deletion test, and why this skill is particularly needed in the AI era
Modules should be relatively few large deep modules with simple interfaces. Deep modules: lots of functionality hidden behind a simple interface.
Failure mode: “AI wandering around in a bad code base”
The fourth failure mode in Matt’s talk is a picture metaphor:
"Shallow modules in a codebase look like this - you have a bunch of tiny blobs, and the AI has to go through a bunch of modules and understand all the dependencies before it can correct them."
"AI is really good at creating codebases like this. So you'll have a situation where AI doesn't understand what your code is doing. It will attempt to explore the code, but because it's poorly laid out, filled with shallow modules, it doesn't get to the right module in time, or doesn't understand all the dependencies."
This is a vicious cycle unique to AI programming:
AI 写代码倾向于产生 shallow 模块(小、多、互相依赖)
↓
代码库变得 shallow
↓
下次 AI 进来探索更难,更容易写错
↓
更多 shallow 模块被加进去
↓
代码库越来越烂,AI 越来越无能To break this cycle, manual reverse refactoring must be performed periodically - merging shallow modules into deep modules. That's exactly what /improve-codebase-architecture does.
Classic theory: Ousterhout’s Deep Modules
John Ousterhout is a professor of CS at Stanford (and the author of the Tcl language and Raft papers). His 2018 book "A Philosophy of Software Design" proposes a simple but powerful ruler:
The "depth" of the module = the hidden complexity of the interface
| Type | Interface | Implementation | Image |
|---|---|---|---|
| Deep | Simple | Rich | A rectangle: narrow and deep |
| Shallow | Complex | Simple | A rectangle: wide and shallow |
The ideal module is deep - users only need to see the short interface, and the complexity is hidden inside. An extreme counterexample is the shallow module: the interface is almost as complex as the implementation, which means there is no encapsulation. Users might as well look at the implementation directly.
Ousterhout's judgment: Good code bases are composed of a small number of deep modules; bad code bases are composed of a large number of shallow modules. This is completely opposite to the traditional dogma of "keeping functions as small as possible, files as short as possible, and modules as many as possible" - he believes that that kind of dogma produces exactly shallow modules.
Matt’s extension: Deletion Test
Matt translated Ousterhout's theory into an operational engineering test, which he called the deletion test:
Imagine deleting the module. If complexity vanishes, it was a pass-through. If complexity reappears across N callers, it was earning its keep.
Human words:
- Delete it, the complexity disappears → This module is originally a pass-through (transit), it is not working, so cut it off
- Delete it, and the complexity will be spread to N callers → It is originally helping you hide the complexity, it is really deep, leave it
The beauty of this test is that it is bidirectional - it can identify both "thin packaging that should be deleted" and "common logic that should be extracted." If you find that after deleting a piece of code, the complexity will spread to 5 places, it means that this code is worth extracting into a deep module.
Key terms (Matt’s precise definition)
There is a Glossary in improve-codebase-architecture/SKILL.md that requires strict use of these words - do not drift to "component", "service", "API" and "boundary":
| Terminology | Definition |
|---|---|
| Module | Anything with an interface and implementation (function/class/package/slice) |
| Interface | Everything the caller must know - types, invariants, error modes, order, configuration (not just function signatures) |
| Implementation | Code inside the module |
| Depth | The lever at the interface. Deep = high leverage, shallow = interface is almost as complex as the implementation |
| Seam (Seam) | The location of an interface - where behavior can be changed without in-place modification. Use "seam" not "boundary" |
| Adapter | Implement the specific implementation of an interface at seam |
| Leverage | The benefits the caller gets from "deep" |
| Locality | The benefits that maintainers gain from "depth" - changes, bugs, and knowledge are all concentrated in one place |
Several core principles:
- Deletion test: see above
- The interface is the test surface: Tests can only be run through the interface - this is the basis for deep module testability
- One adapter = hypothetical seam. Two adapters = real seam.: An interface with only one implementation is a false seam. Real joints require at least two adapters
The last one is particularly counter-intuitive - many teams will abstract an interface in advance "for future expansion", but there is actually only one implementation. Matt's judgment: useless, delete. Wait until the second one comes true. This has the same origin as YAGNI.
Skill Workflow
1. Explore
Skill first lets AI read CONTEXT.md and docs/adr/, and then uses subagent_type=Explore to send a sub-agent to the code base.
Instead of rigid inspiration, use friction as a signal:
- Where does understanding one concept require bouncing between many small modules?
- Where are modules shallow — interface nearly as complex as the implementation?
- Where have pure functions been extracted just for testability, but the real bugs hide in how they're called (no locality)?
- Where do tightly-coupled modules leak across their seams?
- Which parts of the codebase are untested, or hard to test through their current interface?
Every time you find a suspicious point, apply a deletion test: will deleting it make the complexity disappear or spread out? The answer "disperse" is a candidate worthy of deepening.
2. Present Candidates (Statement Candidates)
Present a numbered list of candidates:
1. Files: src/orders/parser.ts, src/orders/validator.ts, src/orders/normalizer.ts
Problem: 三个文件互相调用,理解 Order 入站需要在三处跳转
Solution: 合并为单一 OrderIntake 模块,对外只暴露 parse(raw) → ValidatedOrder
Benefits:
- Locality: Order 入站的所有逻辑、错误处理、bug 修复集中一处
- Leverage: 调用方从理解 3 个接口降为 1 个
- Tests: 只需测 parse() 的输入输出,不再需要 mock 内部协作Requirements:
- Use CONTEXT.md vocabulary to talk about domains ("the Order intake module", not "the FooBarHandler")
- Talk about architecture using Glossary vocabulary ("seam", "depth", "locality")
- Don’t propose interface designs right away – let users pick interesting candidates first
If a candidate conflicts with an existing ADR - only mention it if the conflict warrants revisiting the ADR, and clearly mark it:
"contradicts ADR-0007 — but worth reopening because…"
Don't dig out every refactoring that is prohibited by ADR.
3. Grilling Loop
After the user selects a candidate, drop into grilling mode (inherited from /grill-with-docs):
- Walk through the design tree - constraints, dependencies, the shape of the module after deepening, what is hidden behind the seams, which tests can survive
- Side effects occur immediately:
- Give the deepening module a name that is not in CONTEXT.md → Add it to CONTEXT.md immediately
- An ambiguous term was sharpened in the torture → Update CONTEXT.md immediately
- User rejects candidate with reason load-bearing (critical, something future explorers need to know) → Propose to generate ADR
- Want to explore the various interface designs of deepening modules → Jump to
INTERFACE-DESIGN.mdseparate process
Document maintenance and architecture transformation happen in the same conversation - no two rounds.
Real case: Mejba Ahmed’s practice
Third-party developer Mejba Ahmed wrote an article ["Deep Modules: The Claude Code Skill Saving My Codebase"] (https://www.mejba.me/blog/improve-codebase-architecture-skill-deep-modules) to record in detail his experience using this skill. Key points:
- He originally had 50+ files in a project, each file having less than 100 lines - Typical shallow library
/improve-codebase-architectureran out 8 deepening candidates- He selected 3 deepenings (two data processing modules merged, one toolset merged)
- Result: Number of files dropped from 50+ to 30+, but the total code size remains basically the same - complexity is squeezed into a small number of deep modules
- The hit rate of Claude's subsequent code changes in this library was significantly improved (he said "from 60% to 90%", which was not strictly measured, but it felt strong)
Mejba also has a reminder: Don’t deepen 8 at a time. Only pick one at a time, run the test + commit + observe, and then pick the next one. Otherwise, there is no way to roll back once you complete it.
How to install and use
npx skills@latest add mattpocock/skillsCheck improve-codebase-architecture + setup-matt-pocock-skills.
Call: /improve-codebase-architecture
Recommended rhythm:
- Run once a week or at the end of each sprint
- Or **run it once after completing a wave of intensive development (it is especially easy to pile up shallow modules after high-frequency writing of AI code)
- Don't run when you're in a rush - it will suggest big changes that you won't have time to digest when you're in a rush
Typical process:
/improve-codebase-architecture- AI exploration + list N candidates (with deletion test argument)
- You pick the one that feels the most
- drop into grilling loop alignment design
- AI implementation refactoring (it is recommended to run together with
/tdd- the refactoring must have test protection) - commit + observe
- Come again in a week
Why is this Skill a "closed loop" of Matt's workflow?
Back to Matt’s workflow diagram:
/grill-me → /to-prd → /to-issues → /tdd → /improve-codebase-architecture → 回到 /grill-meNotice that it loops back to the starting point. /improve-codebase-architecture is not a one-time tool, it is a periodic maintenance - because:
- AI continues to add shallow modules to the code base (this is its default tendency, and it will pile up if you write too much)
- As business continues to evolve, old seams will become obsolete.
- The terms in CONTEXT.md continue to be sharpened, and the old naming will not keep up.
Every time you run this skill, the AI friendliness of the code base is refreshed. This is the only way to keep a long-term codebase healthy with LLM - if you don't refresh it, the AI will be dead in your codebase after three months.
This set of thinking is more valuable than the Skill itself
Even if you don’t install /improve-codebase-architecture at all, just remember the following three things, and the quality of PR review will be improved by a notch:
- deletion test: Every time you see a new module, ask yourself "If you delete it, will the complexity disappear or spread out?"
- True seams at least two adapters: single implementation interface = false abstract, delete
- The interface is the test surface: cannot be measured = there is a problem with the interface design
These three items do not require AI or skill—they are the hard currency of engineering aesthetics. Matt wraps them into skills for batch execution, but the real leverage is the three principles themselves.
Notes
Don't go too deep. Ousterhout himself said that deep module is a goal rather than a dogma - a large Util class that crams all the functions into it is not a deep module, but a god module. The judgment criterion is "simple interface + cohesive implementation", both of which must be met.
deepening must have test protection. Structural changes are high-risk operations, and daring to refactor without testing = waiting to take the blame. If there are no tests currently, go to /tdd to add tests to the critical path and then come back.
ADR decisions should not be made on a whim. When you reject a candidate during grilling, the AI will easily suggest generating an ADR - only accepting it if the reason is really "future people need to know". Otherwise, docs/adr/ will be filled with journal entries.
It doesn’t matter if some of the code is shallow. A logger wrapper, a constant file, a one-off script - they're shallow, no problem. This skill looks for those shallow modules that pretend to help you with abstraction but are actually adding chaos.
Reference resources
improve-codebase-architecture/SKILL.md
Full glossary, deletion test, candidate-presentation format, and grilling loop integration.
A Philosophy of Software Design
The book that defined deep modules. ~190 pages, the most cost-efficient software design book of the past decade.
Deep Modules: The Claude Code Skill Saving My Codebase
Third-party walkthrough of using improve-codebase-architecture on a real project. Concrete before/after numbers.
Series conclusion
I have read all 6 articles so far. Review the entire workflow:
/grill-me 或 /grill-with-docs ← 谈清楚要做什么
↓
/to-prd ← 凝固成 PRD
↓
/to-issues ← 切成 vertical slice
↓
/tdd ← 一个 slice 一个 slice 跑红绿
↓
/improve-codebase-architecture ← 周期性深化
↓
回到 /grill-meThe spirit of this process can be condensed into one sentence:
**AI is the tactical soldier on the ground, and you are the strategic layer. Take back the three things of "defining the problem", "deconstructing the problem" and "testing the problem" and do it yourself, and leave "writing code" to AI - this is the true position of engineers in the AI era. **
Matt's set of skills is not the ultimate answer, but the best practice at the current stage. There may be something better three months later, but the spiritual aspect will not change: a good code base is always more important than a bad code base, and basic software skills are always valuable.
Go back to Overview, or choose the most useful skill and install it to try it out.