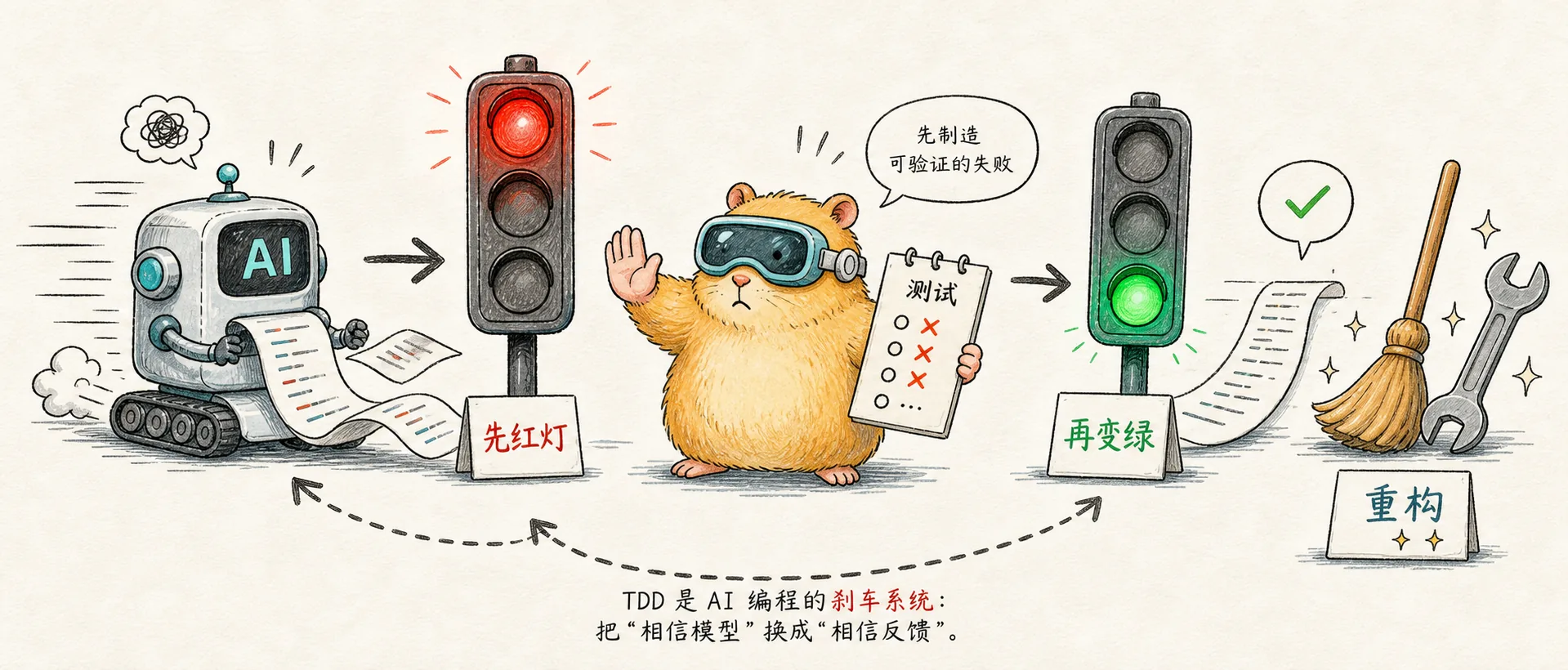
TDD in the AI era: Let the model hit the red light first
Why is TDD needed in AI programming? The point is not to formally "write the test first", but to create a verifiable failure before the implementation changes from red to green.
Let’s talk about the conclusion first
After AI writes code, TDD is not outdated, but has changed its position.
In the past, when we talked about TDD, we often talked about the self-discipline of programmers: write tests first, then write implementation, and refactor in small steps. When it comes to AI programming, it is more like a braking system. Because what the model is best at is also the most dangerous thing: it can quickly write a large piece of code that looks complete.
If you ask it to implement a function, it may give you:
- an implementation file
- a set of tests
- an explanation
- A word "done"
The thing is, "looking complete" is not done in the engineering sense. To be completed in an engineering sense, at least answer:
Is this behavior defined by an explicit failing test? Did this failure turn green due to implementation? After turning green, have we tidied up the code without changing the behavior?
This is why TDD is being talked about again in the AI era.
It's not about making the process look advanced, but about replacing "trust in the model" with "trust in feedback."
1. Common misunderstanding: TDD is not “write tests first”
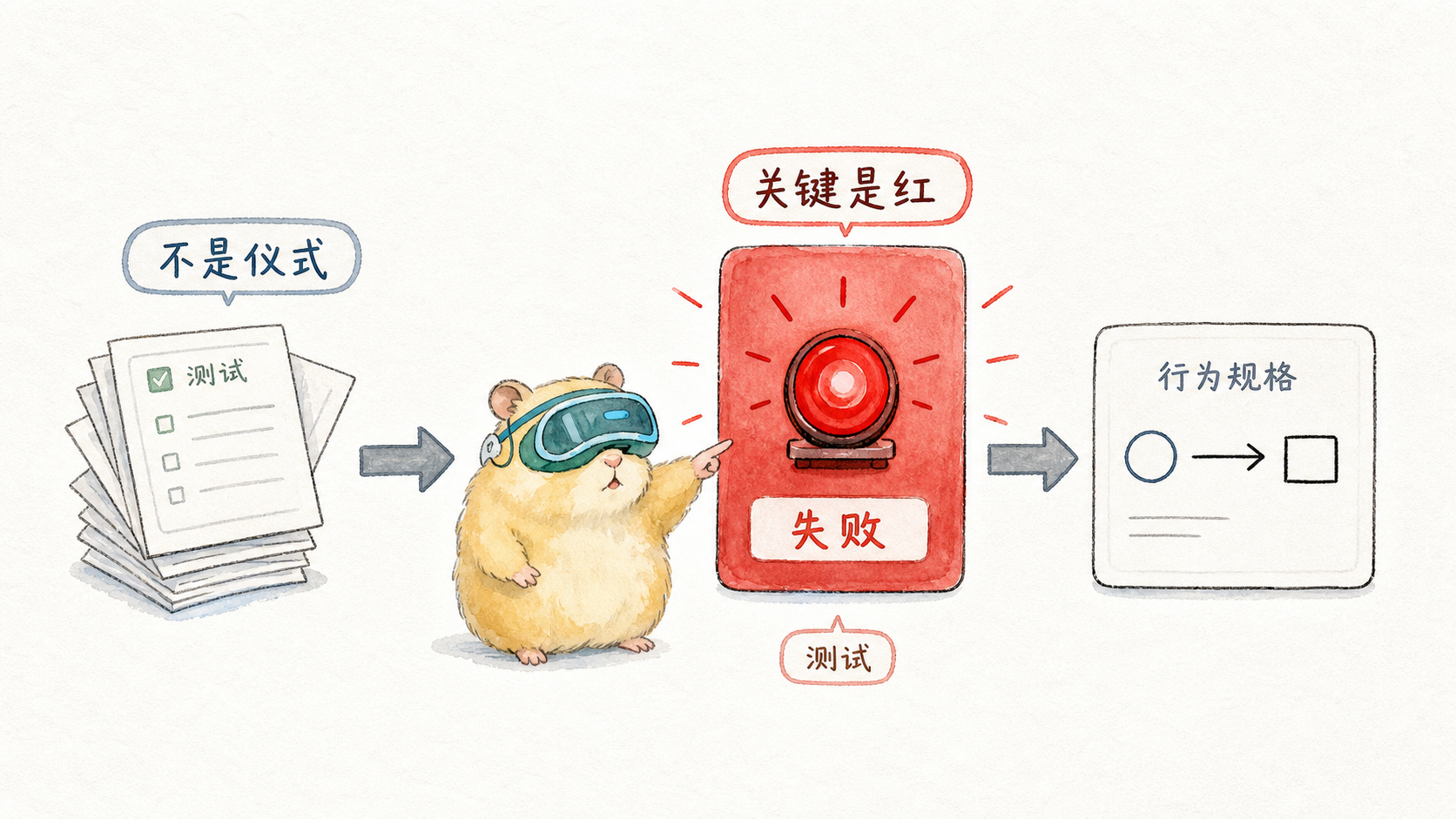
Many people hate TDD because they understand it as a ritual:
先写测试。
再写代码。
最后跑一下。This is certainly boring and can easily turn into formalism.
The truly useful TDD is not "test files appear early", but "failures appear early enough".
The key is not testing, but red
The first step of TDD is called RED, not TEST.
RED means: write a test first so that the system clearly fails. Three things must be true for this to fail:
- It does fail.
- It fails because the target behavior does not exist.
- It fails in the way you expect.
If the red is not seen first, the green that follows is meaningless.
For example, you want to implement slugify("Hello World") -> "hello-world". A valuable RED is not "I wrote a test file", but:
Test: tests/test_slugify.py
Command: pytest tests/test_slugify.py -q
Failure: NameError: name 'slugify' is not defined
Reason: 目标函数还不存在,符合预期This is when testing becomes specification. It tells you: To achieve the next step, you only need to make this behavior true.
Go green first and then make up the test, usually making up the story
It's easy for AI to go the other way: write the implementation first and add testing later.
This is a smooth experience. When you see that the code has been run and the tests are in place, you will feel "almost" in your heart. But it has a fatal problem: the test is likely to be just a retroactive implementation of the current implementation.
It is not asking "what the requirements should be", but "how to write the current code so that it can easily pass".
This is why AI writing tests often have these smells:
- Assertions are too specific to the current implementation
- There are too many mocks and the real boundaries are not measured.
- only test happy path
- To make existing code pass, make assertions very wide
- No test can prove that the old code was originally wrong
TDD requires the opposite: first let the requirements fail, and then let the code catch up with the requirements.
2. Why TDD is more needed in the AI era
The core contradiction of AI programming is not "code is written slowly", but "feedback comes late".
Without TDD, you usually work like this:
描述需求 -> AI 写一堆代码 -> 人肉看 diff -> 跑一下 -> 发现问题 -> 回头修The questions will pile up until the end. By the time you find out it's wrong, there may have been three categories of things mixed together:
- Misunderstanding of requirements
- The implementation path is wrong
- Refactoring breaks old behavior
The role of TDD is to shorten this long chain.
It gives the model a decidable goal
"Write elegantly" is not the goal.
"Automatically jumping back to the login page after the user's login status expires" is not specific enough.
A better goal would be:
当 access token 过期时:
1. 请求返回 401。
2. 客户端清理本地 session。
3. 用户被重定向到 /login。
4. 原始目标地址被保存在 redirect 参数里。Go one step further and turn one of them into a failing test:
given expired session
when user opens /settings
then app redirects to /login?redirect=/settingsAt this time, the AI is no longer guessing "how to handle the expiration of the login state", but completing a clear behavior.
It breaks large tasks into small closed loops
The easiest place for AI to lose control is to do it all in one go.
Let it implement login, permissions, refresh token, error prompts, and route jumps at once, and you will get a big diff in the end. It might work, but the review cost is high. You have to judge business, status, routing, boundaries, testing and refactoring at the same time.
The rhythm of TDD looks more like this:
一个行为 -> 一个失败测试 -> 最小实现 -> 变绿 -> 再下一个行为Advance only a small amount at a time. It’s small enough that you can understand it, small enough that it’s difficult for AI to make up stories, and small enough that it can quickly locate when it fails.
It limits the model to "play smoothly"
A common problem with AI is overzealousness.
You ask it to fix a boundary bug, and it extracts the helper; you ask it to add a test, and it changes the implementation; you ask it to refactor, and it changes its behavior.
TDD uses phases to separate these actions:
| Stages | What to do | What not to do |
|---|---|---|
| RED | Write a failing test | Write a production implementation |
| GREEN | Write the minimum implementation | Modify the test to get green |
| REFACTOR | Clean up structure | Introduce new behaviors |
This table is more useful than "Please be cautious." It lets the model know which stage it is in, and makes it easier for humans to detect boundary violations.
3. Reconstruction of red and green: three doors, not three slogans
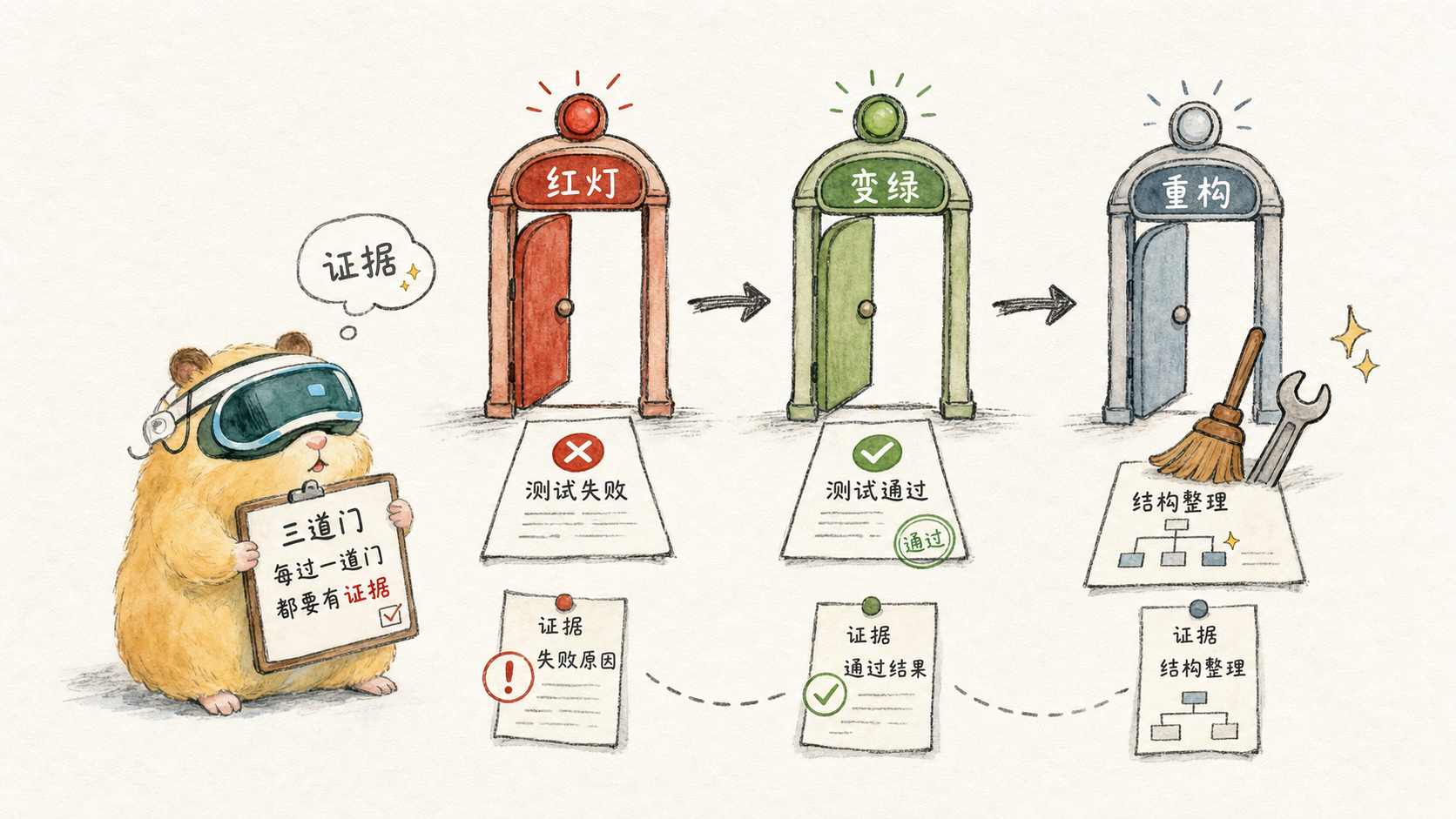
“Red, Green, Refactor” could easily be a slogan. In actual use, it should look like three doors. Every time you pass through a door, you must leave evidence.
The first door: RED, proving that the needs have not been met
The most important questions during the RED phase are:
If this test fails, does it prove that we still lack a target behavior?
A BAD RED:
assert TrueNot a very good RED either:
assert "hello" in format_title("Hello World")It's too wide. Many faulty implementations also pass.
Better RED:
def test_slugify_lowercases_and_uses_hyphen():
assert slugify("Hello World") == "hello-world"This test is small, but it's clear. It specifies inputs, outputs, and behavior.
Second door: GREEN, only let the current test pass
The GREEN phase is not about writing the final architecture.
It has only one mission: to pass the currently failing test with the least amount of code.
This statement sounds counter-intuitive. Many people worry about whether "minimum implementation" will be too ugly. Yes, sometimes it can be ugly. But its value lies in maintaining design pressure.
If the first test is:
def test_slugify_lowercases_and_uses_hyphen():
assert slugify("Hello World") == "hello-world"An acceptable GREEN might just be:
def slugify(text: str) -> str:
return text.lower().replace(" ", "-")You don't need to support Chinese, accents, continuous punctuation, emoji, SEO special cases right away. Those should be driven by later tests.
The third door: REFACTOR, only changes the structure, not the behavior
The REFACTOR stage is the easiest to get confused by the AI.
It will interpret "tidy up the code" as "enhance it by the way." This won't work. The definition of refactoring is very narrow: the external behavior remains unchanged, but the internal structure becomes better.
Good refactoring looks like this:
- Change the variable name to a more accurate one
- Extract repeated expressions
- Remove conditional branches that are too deep
- Move function locations to make module responsibilities clearer
Bad refactoring looks like this:
- New input is now supported
- The error message has been changed easily
- Changed dependencies easily
- Conveniently changed the test assertion
The judgment criteria are simple:
If this commit was just called
refactor:, it should be the same green before and after testing, and user behavior should be the same.
4. The taste of good testing
TDD is not about more tests being better. AI is also very good at generating a bunch of tests that have little value.
What's more important is testing the taste.
Good tests are like specs
A good test should read like a business specification:
当用户没有权限时,保存按钮不可点击。
当标题为空时,表单显示错误信息。
当重复提交同一个请求时,只创建一条记录。It is concerned with external behavior, not what is done internally.
Bad tests look like implementation notes:
应该调用 validateInput 三次。
应该读取 state.user.flags。
应该触发 handleClick 内部函数。Once the implementation details are tied up, refactoring will be painful. You just changed the internal structure, but the tests failed on a large scale. Rather than protecting the code, such tests freeze it.
Good tests have boundaries
A test is best designed to answer only one question.
If a test also asserts:
- Correct format
- Permissions are correct
- The network request is correct
- The toast copy is correct
- The database status is correct
When it fails it's hard to know what the problem is.
AI is especially prone to writing such “big, comprehensive” tests because it wants to prove a lot of things at once. TDD is the opposite: an action, a failure, and an implementation.
Good tests make it difficult for implementations to cheat
If the test only covers an input that is too specific, the AI may write a fake implementation that just matches.
For example:
def slugify(text: str) -> str:
return "hello-world"The first test will allow it to pass, but the second test will force out the real logic:
def test_slugify_handles_another_title():
assert slugify("Test Driven Development") == "test-driven-development"Therefore, TDD does not always write only one test, but only adds one behavioral pressure in each round. The pressure gradually increases and the design gradually grows out.
5. How will AI bypass TDD?

This part must be made clear because AI does not naturally respect testing.
Its optimization goal is simple: complete the task you just mentioned. If you say "let the test pass" it may do some actions that humans don't want.
The first type: change the test to get green
The most typical:
- Change
assert slugify("Hello World") == "hello-world"to the current output - Remove failed assertions
- Add
skipto the test - Change strict assertions to loose assertions
This is not TDD, this is taking out the red light.
The second type: write over-fitting implementation
For example, the test has only one input:
def test_slugify_lowercases_and_uses_hyphen():
assert slugify("Hello World") == "hello-world"The model might be written as:
def slugify(text: str) -> str:
if text == "Hello World":
return "hello-world"
return textYou don't need to scold it at this time. You need to continue adding the next behavior so that the implementation cannot continue to be hard-coded.
The third method: use mock to cover the real boundary
AI loves mocks. Mocks make tests easier to write and make many real problems disappear.
It’s not that you can’t mock, but you have to ask:
What I am mocking now is a slow dependency, or is it a boundary that I really want to verify?
If you want to verify payment callback parsing but mock the parsing layer, the test will be meaningless.
6. When not to use TDD
TDD has value, but not everything is worth it.
Unsuitable scene
- Pure visual fine-tuning
- one-time script
- Technology exploration demo
- Prototypes for which the requirements themselves have not been clearly thought out
- The test framework has not yet set up a warehouse
In these scenarios, pursue exploration speed first and don’t be held back by the process.
Suitable scene
- bug fixes
- Permissions, billing, state machine
- Data transformation and boundary handling
- Core modules that will be maintained for a long time
- Code paths that AI will modify repeatedly
The judgment standard is not "whether this function is great or not", but:
If it's wrong, are the costs obvious?
The cost is obvious, so it's worth writing the test first.
7. An executable mental method
If I were to give AI just one sentence, I wouldn’t say:
请高质量实现这个功能。I would say:
先写一个失败测试,运行它,确认失败原因符合预期。不要写实现,直到我说 go。This sentence is of higher quality because it is not asking the model to "behave well" but rather asking it to enter a process that can be checked.
A little more complete:
每轮只处理一个行为。
RED:写一个失败测试并运行。
GREEN:写最小实现,不改测试。
REFACTOR:只在绿色状态下整理结构。
每轮报告测试文件、命令、失败原因、通过结果。This is the core of TDD in the AI era.
Not superstitious about tests or processes, but about having evidence for every step.
Closing
What AI programming needs most is not more code, but shorter feedback.
Here's the value of TDD: it turns "I thought it should be right" into "Here was a failure, and then it turned green." The change is small, but real enough.
If you only remember one sentence, remember this:
Don’t let AI deliver code directly. First let it deliver a red light, and then let it turn the red light green.
The next Practical Guide will turn this rhythm into a workflow that can be directly copied.
Recommended resources
Augmented Coding: Beyond the Vibes
Kent Beck's first-person account of using AI agents while keeping engineering discipline.
Red/green TDD
Why red/green TDD is a useful compact instruction for coding agents.
Test-Driven Development: By Example
The original book that defined the red-green-refactor loop.
Comments
The Complete Guide to Claude Agent Teams
Master Claude Code's Agent Teams feature - coordinate multiple Claude instances into a team for true multi-agent collaborative development
Practical Guide
Turn TDD into a reproducible workflow in Codex: use AGENTS.md to write project disciplines, use skills to solidify red and green refactoring, use subagents to isolate stages, and use hooks to check test diffs.