Ralph Wiggum 深度解析
理解 Ralph 技术的核心原理:为什么一个 bash 循环能让 AI 在你睡觉时写代码
引言
下班前给 AI 布置任务,第二天早上收获可用的代码——这个梦想听起来需要复杂的 Agent 集群、精妙的编排系统。但 2025 年最火的 AI 编程技术,核心就是这一行:
while :; do cat PROMPT.md | claude ; done一个无限循环,反复把任务喂给 Claude。这就是 Ralph Wiggum。它简单到令人尴尬,但确实有人用它花 $297 完成了原本报价 $50,000 的项目。
为什么这么简单的方法反而有效?Anthropic 发布官方插件后,发明者 Geoffrey Huntley 却说"This isn't it"——这又是怎么回事?
什么是 Ralph

名字来自《辛普森一家》里的角色。Ralph Wiggum 是警察局长的儿子,全剧最"单纯"的人——他不太清楚自己在做什么,但永远不会停下来。他的标志性台词"I'm helping!"意外地揭示了这项技术的精髓:天真且不懈的坚持(Naive and relentless persistence)。
一种 AI 开发方法论,核心是无限循环 + 每次全新上下文。让 AI 反复尝试同一个任务,每次迭代都从干净的状态开始,通过文件系统看到之前的工作成果。
这里有个重要区分:Ralph 是方法论,不是工具。就像"敏捷开发"是方法论而不是某个软件,Ralph 描述的是一种工作方式。不同的实现效果可能差异巨大——后面会详细讨论这个问题。
为什么需要 Ralph:Context Rot 问题

要理解 Ralph 为什么有效,先要理解它解决的问题。
AI 是怎么"变笨"的
用 Claude 处理复杂任务时,你可能有过这样的体验:刚开始对话很顺畅,Claude 理解准确、执行到位。但随着对话越来越长,它开始"迟钝"——忘记重要信息,重复犯同样的错误,代码质量下降,甚至开始产生莫名其妙的"幻觉"。
这不是 AI 不够聪明。问题在于上下文窗口被污染了。
想象这个场景:你让 Claude 写一个功能,第一次失败了。你说"修复这个",它尝试但又失败。来回十次之后,Claude 的上下文里塞满了:九次失败的代码、九组错误信息、大量不再相关的讨论。在这些杂乱信息中找到重点,难度越来越大。
Dumb Zone
Geoffrey Huntley 和社区开发者发现了一个现象,称之为"Dumb Zone":
| 上下文大小 | 表现 |
|---|---|
| 0 - 50k tokens | 最佳性能 |
| 50k - 100k tokens | 良好,轻微下降 |
| 100k+ tokens | 明显退化,开始忽略指令 |
| 150k+ tokens | 严重退化 |
没有精确临界点,但经验法则:上下文用到一半左右就该警惕了。对于 200k tokens 的 Claude,超过 100k 时你可能在和一个"变笨"的 AI 交流。
累积的上下文是负债
这里有个反直觉的洞察:累积的上下文不是资产,而是负债。
我们习惯认为记忆力越好越好,保留的信息越多越好。但在大语言模型的世界里,这个直觉是错的。对话越长,上下文里充斥的"负面信息"越多:失败的代码、不再相关的讨论、被纠正过的错误理解。这些不仅占用空间,还分散 AI 的"注意力"。
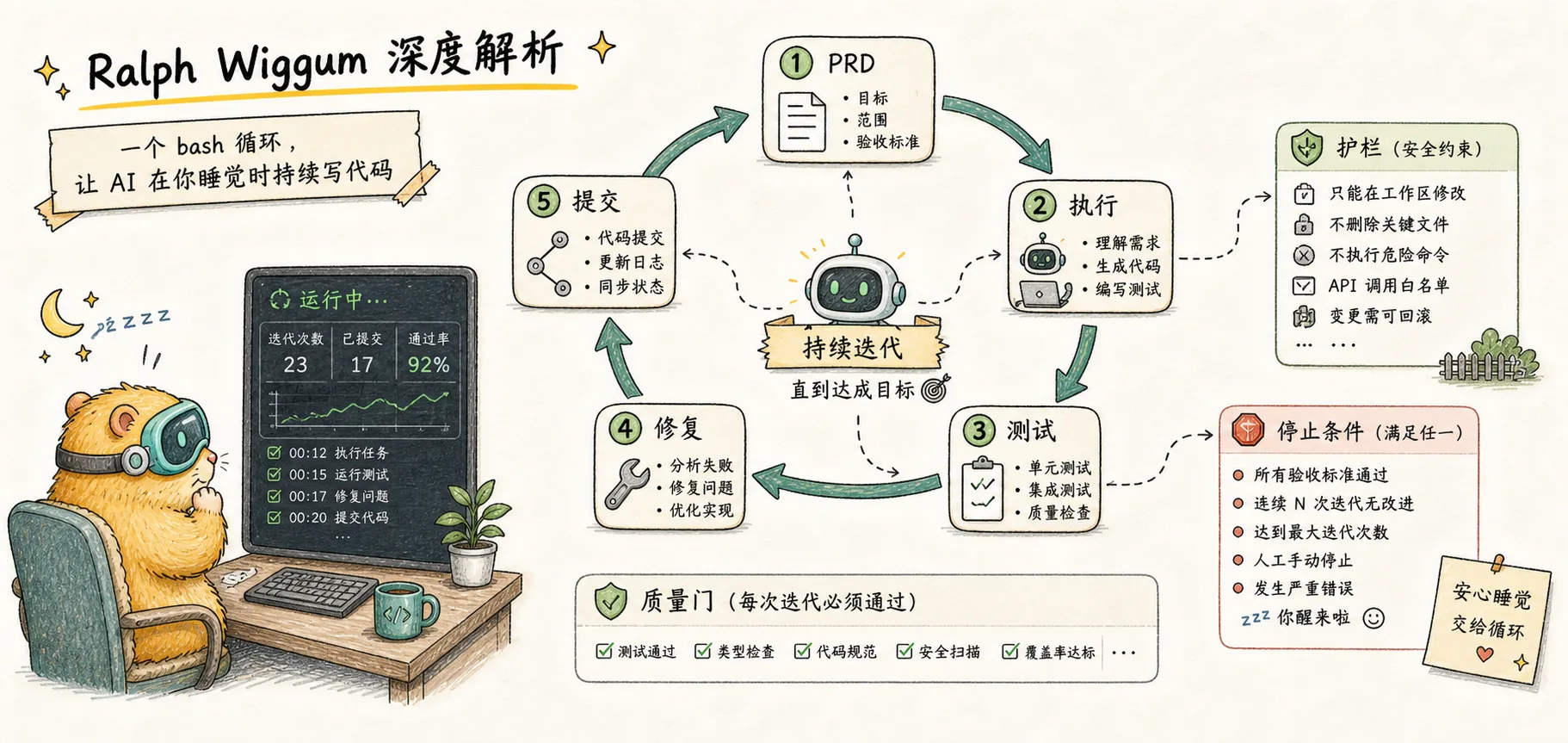
Ralph 的工作原理
理解了 Context Rot,Ralph 的解决方案就清晰了:既然累积上下文是问题,那就不要累积。
Ralph 建立在三个支柱上:
1. 新 Session
每次循环迭代时,启动一个全新的 Claude 实例,获得完全干净的上下文窗口。不是"清空对话历史"——那样累积的状态可能仍然存在。而是彻底关闭当前进程,启动一个新的。
这意味着每次迭代开始时,Claude 都处于最佳状态。没有之前的错误来困扰它,没有过时的讨论来分散注意力。
这就是为什么循环必须在 Claude Code 外部运行——bash 循环需要能够控制 Claude 进程的生命周期。
2. 文件作为真相来源
如果每次都是新上下文,AI 怎么知道之前做了什么?答案:通过文件系统,而不是对话历史。
规格文档和实施计划才是真相来源,而不是之前的对话。
关键文件:
- PRD/spec 文件 — 定义目标、功能列表、成功标准
- IMPLEMENTATION_PLAN.md — 任务分解和进度
- progress.txt — 自由格式日志,每次迭代结束时追加学到的内容
- Git 历史 — 代码修改的证明
每次迭代开始时,Claude 读取这些文件了解目标和进度。它看到的是精心组织的状态快照,而不是混乱的对话历史。
3. 反馈循环
仅有干净上下文和持久化状态还不够。如果 AI 写了有问题的代码并提交了,错误会累积。
反馈循环是自动化的质量门槛:
- TypeScript 类型检查 — 即时反馈类型正确性
- 单元测试 — 验证功能符合预期
- CI/CD — 确保代码可以构建和集成
如果测试失败,代码不会被提交,Claude 会看到失败信息。下一次迭代的新 Claude 实例会尝试修复问题。
关于如何建立完整的质量保障体系,我在 我的 Claude Code 质量检查流程 中分享了五层防线的实践经验:Hooks 自动化、测试策略、AI Review、Pre-commit、GitHub 集成。
Human on the Loop
Geoffrey Huntley 反复强调一个概念区别:
| Human in the Loop | Human on the Loop |
|---|---|
| 保姆式陪伴 | 监督式管理 |
| AI 每一步都等你确认 | 你设定目标和边界,AI 自主运行 |
| 你是工作流程的瓶颈 | 你偶尔检查进度 |
这就像监督一个实习生。你不会站在旁边看他写每一行代码。你给他任务、边界、检验标准,然后让他去做。
实际使用中有两种模式:
- AFK 模式:下班前启动,回家睡觉,早上检查结果
- Human-in-the-loop 模式:每次迭代后暂停检查,适合复杂或不确定的任务
什么任务适合 Ralph
Ralph 不是万能的。它的核心优势是"迭代直到成功",这决定了它适合特定类型的任务。
适合的任务
| 场景 | 原因 |
|---|---|
| 有明确成功标准的任务 | 可以自动验证完成(测试通过、类型检查通过) |
| 需要迭代改进的任务 | Ralph 的核心优势就是不断尝试 |
| 绿地项目 | 无需担心破坏现有代码 |
| 有自动测试的项目 | 测试作为反压机制,确保质量 |
不适合的任务
| 场景 | 原因 |
|---|---|
| 需要人工判断的设计决策 | 无法自动验证"好不好看" |
| 一次性操作 | 不需要迭代的任务用 Ralph 是浪费 |
| 生产环境调试 | 风险太高,不适合无人值守 |
| 成功标准不清晰的任务 | 无法判断何时停止 |
三种使用模式
完整实现模式
这是 Ralph 最常见的用法:从头构建一个完整的功能或项目。你准备好 spec 文件和实施计划,让 Ralph 自动执行所有任务。
典型场景:
- 构建一个新的 REST API
- 开发一个 CLI 工具
- 实现一个新功能模块
真实案例:有开发者用这种模式完成了一个价值 $50,000 的外包项目,总 API 成本仅 $297。整个过程包括 MVP 开发、测试编写和代码审查,全程自动化。另一个案例是将一个老旧代码库从 React v16 升级到 v19,Ralph 跑了 14 小时,完全无需人工干预。
探索模式
不是所有任务都需要产出代码。有时候你需要的是理解——理解一个新接手的代码库、理解一个复杂系统的架构、理解某个模块的工作原理。
典型场景:
- 接手一个陌生的项目,需要快速建立整体认知
- 为现有代码库生成文档
- 分析系统架构,找出潜在问题
在这种模式下,你的 prompt 不是"实现 X 功能",而是"阅读这个代码库,生成架构文档"或"找出所有 API 端点并说明它们的作用"。Claude 每次迭代都会深入探索,逐步建立更完整的理解。
暴力测试模式
有些 bug 你知道症状、知道期望的正确行为,但就是找不到根本原因。这时候可以让 Ralph 来"暴力破解"。
典型场景:
- 一个间歇性出现的 bug,难以复现
- 某个测试偶尔失败,原因不明
- 性能问题,不确定瓶颈在哪里
设置目标:"修复这个 bug,让这个测试稳定通过"。Ralph 会不断尝试不同的修复方案,直到找到有效的那个。这种方法特别适合那些"我不知道怎么修,但我知道什么时候算修好了"的问题。
实现方式的选择
理解了 Ralph 的方法论,接下来面临一个实际问题:如何实现这个循环?
社区发展出了两种工程化程度不同的实现:
极简路线——snarktank/ralph:几百行 bash 脚本,每次全新会话,专注于循环本身。轻量、易上手,适合快速开始。
工程化路线——frankbria/ralph-claude-code:完整工具链(监控仪表盘、断路器、速率限制、会话过期管理)。默认通过 --continue 复用会话,也可通过 --no-continue 切换为全新会话模式。
| 维度 | 极简(snarktank) | 工程化(frankbria) |
|---|---|---|
| 会话模式 | 每次全新 | 默认复用,可切换为全新 |
| 监控 | 手动查看 | 内置 tmux 仪表盘 |
| 安全机制 | max_iterations | 断路器 + 速率限制 + 超时 |
| 安装复杂度 | Skill 复制 | install.sh + 向导 |
两种实现各有优劣,选择取决于你对工程化工具的需求。详细的使用方法和对比分析见各自的实战文章。
写在最后
Ralph 教给我们一个重要的道理:有时候最简单的方法反而最有效。当所有人都在追求更复杂的架构时,一个 bash 循环改变了游戏规则。
当然,Ralph 只是拼图的一部分。它需要好的 prompt、合适的项目、正确的反馈机制才能发挥威力。了解了原理之后,可以根据你的需求选择合适的实现方式:
- 需要长期 AFK、大量迭代?→ 《snarktank/ralph 实战指南》
- 需要工程化监控和安全机制?→ 《frankbria/ralph-claude-code 实战指南》
相关阅读:
- snarktank/ralph 实战指南 — 极简外部循环,从安装到实战的完整操作手册
- frankbria/ralph-claude-code 实战指南 — 工程化实现:监控、断路器与安全机制
- Claude Subagent 完全指南 — 另一种保持上下文清洁的方式
- Claude Skills 是什么 — 探索 Claude 的可重用工作手册
- GSD 深度解析 — 在 Ralph 基础上构建的完整上下文工程系统
- Claude 系统架构全解析 — 理解 Hooks、Subagent 等组件的整体架构