规格驱动开发实践指南
掌握 speckit 命令从规格到代码的完整工作流:命令详解、完整案例演示与最佳实践
引言
上一篇我们了解了规格驱动开发的理念——先定义「做什么」,再考虑「怎么做」。这种看似多此一举的流程,实际上能大幅减少 AI 编程中的返工和沟通成本。
这一篇,我们来动手实践。你将学会如何使用 speckit 系列命令,完成从需求描述到代码实现的完整流程。
安装与配置
Speckit 命令源自 GitHub 官方的 Spec Kit 项目。根据你的使用场景,有几种不同的集成方式。
新项目初始化
对于新项目,推荐使用官方的 specify-cli 工具进行初始化:
# 使用 uv 安装 specify-cli
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
# 初始化新项目,指定使用 Claude 作为 AI 助手
specify init my-project --ai claude这会自动创建项目目录结构,包括 .specify/ 配置目录和相关模板文件。
已有项目集成
Speckit 命令需要配置文件才能使用。在已有项目中集成 speckit,推荐使用 specify-cli:
cd your-existing-project
specify init . --ai claude # 注意是 . 表示当前目录这会在项目中创建:
your-project/
├── .specify/
│ ├── templates/ # 规格、计划等模板
│ ├── scripts/ # 辅助脚本
│ └── memory/ # constitution.md
├── .claude/
│ └── commands/ # Claude Code 命令配置
│ ├── speckit.specify.md
│ ├── speckit.plan.md
│ └── ...
└── specs/ # 功能规格存放目录初始化不会覆盖你现有的文件。完成后,在 Claude Code 中即可使用 /speckit.* 系列命令。
注意:speckit 命令不是 Claude Code 内置的,必须先完成上述初始化步骤。如果直接运行
/speckit.specify会提示命令不存在。
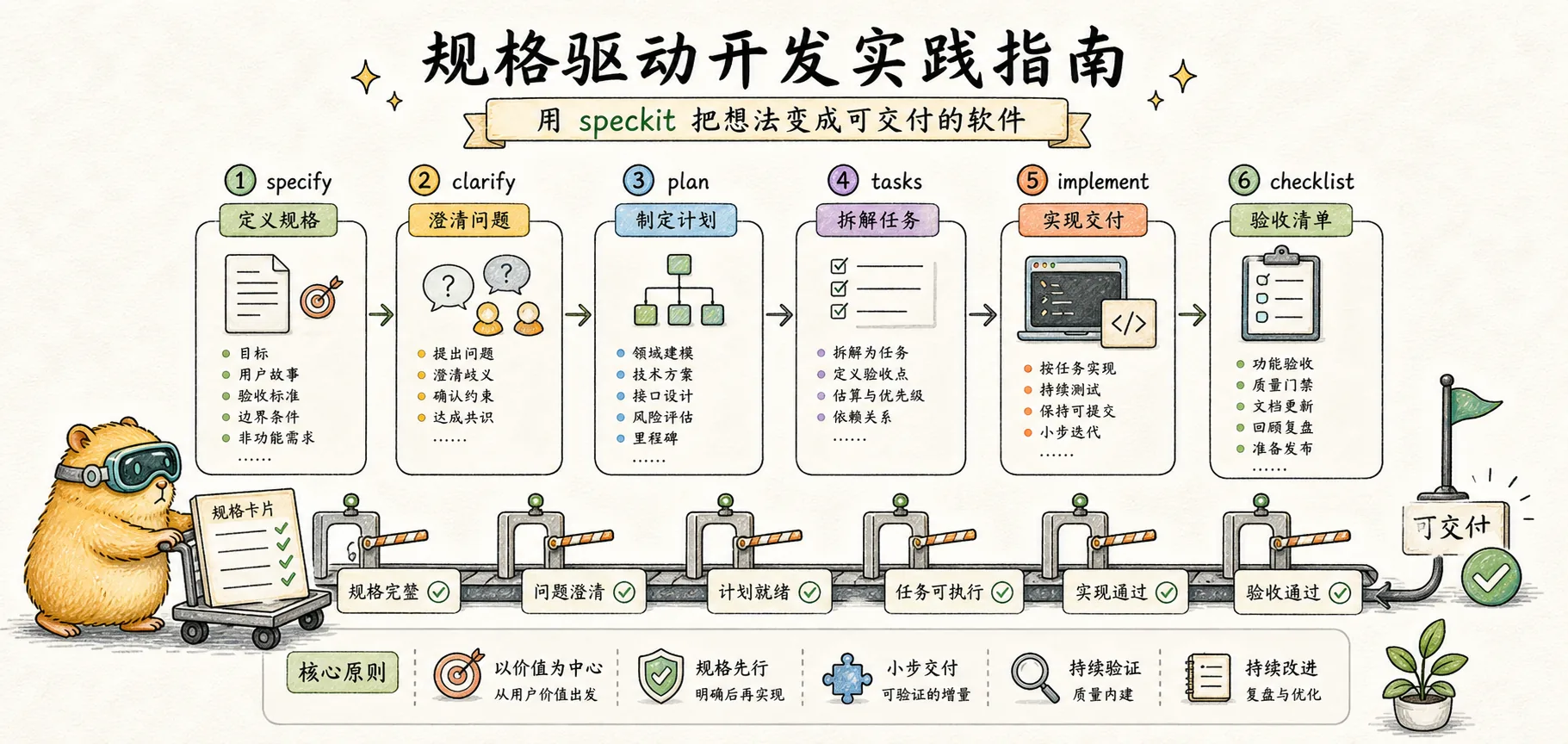
命令详解
Speckit 提供了一套命令来支持规格驱动开发的各个阶段。每个命令都有明确的输入和输出,形成一条可追溯的链条。
/speckit.specify — 创建功能规格
这是整个流程的起点。你用自然语言描述想要的功能,AI 会帮你整理成结构化的规格文档。
功能:从自然语言描述创建功能规格文档
输入:功能描述(自然语言)
输出:
specs/[编号]-[功能名]/spec.md— 功能规格文档- 新的 git 分支(如
001-user-auth)
使用示例:
/speckit.specify 我想添加一个用户登录功能,支持邮箱密码登录,需要有记住登录状态的选项执行后,AI 会:
- 生成一个简短的功能名称(如
user-auth) - 创建新的功能分支
- 生成包含用户故事、功能需求、成功标准的规格文档
- 对不明确的地方标记
[NEEDS CLARIFICATION]
规格文档的核心结构:
# Feature Specification: 用户登录功能
## User Scenarios & Testing
### User Story 1 - 用户登录 (Priority: P1)
读者通过邮箱密码登录系统...
**Acceptance Scenarios**:
1. Given 用户输入正确的邮箱和密码, When 点击登录, Then 成功进入系统
## Requirements
### Functional Requirements
- FR-001: 系统必须支持邮箱密码登录
- FR-002: 系统必须提供"记住我"选项
## Success Criteria
- SC-001: 用户能在 30 秒内完成登录流程注意规格文档不涉及任何技术细节——不提用什么框架、不写数据库结构、不定义 API。这些都是后面阶段的事情。
/speckit.clarify — 澄清模糊点
规格文档写好后,可能还有一些模糊的地方。这个命令会检查规格,提出关键问题帮你澄清。
功能:识别规格中的模糊点,通过问答完善规格
输入:现有的 spec.md 文档
输出:更新后的 spec.md(包含澄清记录)
使用示例:
/speckit.clarify执行后,AI 会:
- 扫描规格文档中的模糊点
- 按优先级(范围 > 安全 > 用户体验 > 技术细节)排序
- 逐一提问,每次只问一个问题
- 根据你的回答更新规格文档
问答示例:
## Question 1: 登录失败处理
**Context**: 规格中提到用户登录,但未说明登录失败的处理方式。
**Recommended:** Option B - 连续 5 次失败后锁定账户是安全最佳实践
| Option | Description |
|--------|-------------|
| A | 仅显示错误提示,不做限制 |
| B | 连续 5 次失败后锁定账户 15 分钟 |
| C | 使用验证码防止暴力破解 |
你可以回复选项字母(如 "B"),说 "yes" 接受推荐,或提供自己的答案。每次澄清后,规格文档会自动更新,添加澄清记录:
## Clarifications
### Session 2025-12-20
- Q: 登录失败如何处理? → A: 连续 5 次失败后锁定账户 15 分钟/speckit.plan — 生成技术计划
规格清晰后,进入技术设计阶段。这一步会产出技术计划和研究报告。
功能:根据规格生成技术实施计划
输入:spec.md 文档
输出:
plan.md— 技术计划(架构、数据模型、API 设计)research.md— 研究报告(技术选型决策)data-model.md— 数据模型(如适用)contracts/— API 合约(如适用)
使用示例:
/speckit.plan 我使用 Next.js + Prisma + PostgreSQL你可以在命令后附加技术栈偏好。执行后,AI 会:
- 分析规格中的功能需求
- 研究相关技术的最佳实践
- 设计数据模型和 API 结构
- 生成完整的技术计划
技术计划的核心内容:
# Implementation Plan: 用户登录功能
## Technical Context
**Language/Version**: TypeScript 5.x
**Primary Dependencies**: Next.js 15, Prisma, PostgreSQL
**Authentication**: NextAuth.js with credentials provider
## Project Structure
src/
├── app/
│ └── (auth)/
│ ├── login/
│ └── api/auth/
├── lib/
│ └── auth/
└── prisma/
└── schema.prisma
## Data Model
- User: id, email, passwordHash, createdAt, updatedAt
- Session: id, userId, expiresAt/speckit.tasks — 分解任务
技术计划有了,接下来把它分解成可执行的任务清单。
功能:将技术计划拆分为可执行的任务列表
输入:plan.md 文档
输出:tasks.md — 按依赖排序的任务清单
使用示例:
/speckit.tasks执行后,AI 会:
- 从 plan.md 提取技术方案
- 从 spec.md 提取用户故事优先级
- 按用户故事分组生成任务
- 标记可并行执行的任务
[P] - 为每个任务指定具体的文件路径
任务清单格式:
## Phase 1: Setup
- [ ] T001 创建项目结构
- [ ] T002 [P] 配置 Prisma schema
- [ ] T003 [P] 配置 NextAuth
## Phase 2: User Story 1 - 用户登录 (P1)
- [ ] T004 [US1] 创建 User 模型 in prisma/schema.prisma
- [ ] T005 [US1] 实现登录 API in src/app/api/auth/[...nextauth]/route.ts
- [ ] T006 [US1] 创建登录页面 in src/app/(auth)/login/page.tsx每个任务都有:
- 任务 ID(T001, T002...)— 用于追踪
- [P] 标记 — 表示可与其他 [P] 任务并行
- [US] 标签 — 表示属于哪个用户故事
- 文件路径 — 明确要操作哪个文件
/speckit.implement — 执行实现
万事俱备,开始执行任务清单。
功能:按任务清单逐个执行实现
输入:tasks.md 文档
输出:实际代码
使用示例:
/speckit.implement执行前,AI 会检查检查清单(如果有)。执行时:
- 按阶段顺序执行任务
- 每完成一个任务,标记为
[X] - 遵循任务依赖关系
- 并行任务可同时进行
执行过程示例:
Phase 1: Setup
✓ T001 创建项目结构
✓ T002 配置 Prisma schema
✓ T003 配置 NextAuth
Phase 2: User Story 1
✓ T004 创建 User 模型
正在执行 T005...实现后的审查
/speckit.implement 完成后,不要直接合并代码。AI 生成的代码需要人工审查:
必做的验证步骤:
-
运行测试套件
npm test # 或你的测试命令确保 AI 没有破坏现有功能。
-
代码审查要点
- 是否符合规格的意图(对照 spec.md)
- 是否遵循项目的代码风格
- 是否有潜在的安全问题
-
边界测试 手动测试 AI 可能遗漏的边界情况:
- 空值处理
- 极端输入
- 并发场景
- 错误路径
-
性能检查 如果涉及数据库操作或 API 调用,检查是否有 N+1 查询等性能问题。
提示:即使规格写得很详细,AI 仍可能在实现细节上出现偏差。审查不是不信任规格驱动开发,而是工程纪律的一部分。
/speckit.analyze — 一致性分析
这是一个可选的质量检查步骤,用于验证规格、计划、任务之间的一致性。
功能:跨文档一致性和质量分析
输入:spec.md, plan.md, tasks.md
输出:分析报告(不修改任何文件)
使用示例:
/speckit.analyze执行后会检查:
- 每个需求是否都有对应的任务
- 任务是否覆盖了所有用户故事
- 术语是否一致
- 是否有遗漏或重复
其他命令(可选)
除了上述核心命令,speckit 还提供了几个辅助命令。这些命令不在主流程中,但在特定场景下很有用。
/speckit.constitution — 创建项目宪法
用于定义项目的开发原则和规范。适合团队项目,确保所有成员遵循统一的开发标准。
- 输入:交互式问答或直接提供原则
- 输出:
.specify/constitution.md项目宪法文件 - 场景:新团队项目初始化、统一代码风格和架构决策
/speckit.checklist — 生成质量检查清单
根据功能规格生成定制化的质量检查清单,用于实施前确认质量标准。
- 输入:spec.md 文档
- 输出:
checklists/目录下的检查清单 - 场景:重要功能上线前的质量把关、代码审查参考
/speckit.taskstoissues — 转换任务为 GitHub Issues
将 tasks.md 中的任务自动转换为 GitHub Issues,方便团队协作和任务分配。
- 输入:tasks.md 文档
- 输出:GitHub Issues(通过 gh CLI 创建)
- 场景:团队协作开发、Sprint 规划、任务追踪
工具生态
本文介绍的 speckit 命令来自 GitHub Spec Kit 项目。除此之外,2025 年多个主流 AI 编程工具都开始支持类似的规格驱动工作流:
| 工具 | 特点 | 适用场景 |
|---|---|---|
| GitHub Spec Kit | 本文使用的工具,MIT 开源,支持 Claude Code / Copilot / Gemini CLI | 命令行偏好者,跨工具协作 |
| AWS Kiro | VS Code fork,可视化工作流,EARS 表示法 | GUI 偏好者,AWS 生态用户 |
| JetBrains Junie | IntelliJ 生态集成,Think More 推理模式 | JetBrains IDE 用户 |
| Cursor Plan Mode | 内置规划阶段,自动生成执行计划 | 已使用 Cursor 的开发者 |
如何选择:
- 如果你使用 Claude Code、GitHub Copilot 或 Gemini CLI,推荐 GitHub Spec Kit
- 如果偏好图形界面和可视化工作流,可以尝试 AWS Kiro
- 如果是 JetBrains 用户,Junie 与 IDE 的集成更自然
- 如果已经在用 Cursor,它的 Plan Mode 提供了类似的规划能力
核心理念是相通的——工具只是载体,重要的是先规格后代码的思维方式。
完整案例演示
让我们通过一个实际案例,走完 speckit 的完整流程。
场景:为博客系统添加文章收藏功能
Step 1: 创建规格
/speckit.specify 我想为博客添加文章收藏功能,用户可以收藏喜欢的文章,并在个人中心查看收藏列表AI 生成规格文档 specs/002-article-bookmark/spec.md:
# Feature Specification: 文章收藏功能
## User Scenarios & Testing
### User Story 1 - 收藏文章 (Priority: P1)
用户在阅读文章时,点击收藏按钮将文章添加到收藏列表。
**Acceptance Scenarios**:
1. Given 用户已登录, When 点击收藏按钮, Then 文章被添加到收藏列表
2. Given 用户未登录, When 点击收藏按钮, Then 提示登录
### User Story 2 - 查看收藏列表 (Priority: P2)
用户在个人中心查看自己收藏的所有文章。
## Requirements
- FR-001: 用户必须能够收藏/取消收藏文章
- FR-002: 收藏按钮必须显示当前收藏状态
- FR-003: 个人中心必须显示收藏列表
## Success Criteria
- SC-001: 收藏操作在 500ms 内完成
- SC-002: 收藏列表支持分页,每页 10 篇Step 2: 澄清需求
/speckit.clarifyAI 提问:「收藏数量是否有上限?」
回答:「最多收藏 100 篇文章」
规格更新,添加:
- FR-004: 每个用户最多收藏 100 篇文章
- 当达到上限时显示提示
Step 3: 生成计划
/speckit.plan 使用 Next.js + Prisma生成技术计划,包括:
- Bookmark 模型(userId, articleId, createdAt)
- API 路由设计(POST/DELETE /api/bookmarks)
- 组件设计(BookmarkButton, BookmarkList)
Step 4: 分解任务
/speckit.tasks生成任务清单:
## Phase 1: Setup
- [ ] T001 添加 Bookmark 模型到 Prisma schema
## Phase 2: US1 - 收藏文章
- [ ] T002 [US1] 创建收藏 API in src/app/api/bookmarks/route.ts
- [ ] T003 [US1] 创建 BookmarkButton 组件 in src/components/BookmarkButton.tsx
- [ ] T004 [US1] 集成到文章页面
## Phase 3: US2 - 收藏列表
- [ ] T005 [US2] 创建收藏列表页面 in src/app/profile/bookmarks/page.tsx
- [ ] T006 [US2] 实现分页逻辑Step 5: 执行实现
/speckit.implement按任务顺序执行,每完成一个任务标记 [X]。
最佳实践与注意事项
什么时候用 speckit
适合的场景:
- 新功能开发(涉及 3+ 个文件)
- 需求不完全明确时(通过 clarify 澄清)
- 多人协作项目(规格作为共识)
- 重要功能(需要可追溯性)
不适合的场景:
- 简单 bug 修复
- 一行代码的改动
- 紧急热修复
- 纯探索性实验
常见陷阱
在使用 speckit 的过程中,有几个常见的陷阱需要注意:
陷阱 1:规格太模糊
症状:AI 生成的代码与预期差距大,需要大量返工。
# ❌ 模糊的规格
用户可以搜索文章
# ✓ 清晰的规格
- FR-001: 用户可以按标题关键词搜索文章
- FR-002: 搜索结果按相关度排序,每页显示 10 条
- FR-003: 搜索词高亮显示在结果中
- FR-004: 空搜索词时显示热门文章解决方案:运行 /speckit.clarify,或手动补充功能需求和成功标准。
陷阱 2:规格太详细
症状:AI 被限制得无法发挥,生成的代码过于僵硬,或者直接忽略部分指令。
# ❌ 过度详细(指定实现细节)
使用 lodash 的 debounce 函数,延迟 300ms,
用 useCallback 包裹,依赖项为 [searchTerm]...
# ✓ 恰当的详细程度(只说做什么)
搜索输入应该防抖,避免频繁请求解决方案:保持规格在「做什么」层面,把「怎么做」留给 Plan 阶段。
陷阱 3:跳过 Plan 阶段
症状:Tasks 太粗糙或太碎片化,实现时频繁返工,任务之间依赖关系混乱。
解决方案:复杂功能务必完成 Plan 阶段。Plan 不仅产出技术方案,还帮助识别潜在的架构问题。
陷阱 4:不审查直接合并
症状:上线后发现边界情况未处理、安全漏洞、性能问题。
解决方案:参考上文「实现后的审查」,始终在合并前运行测试和代码审查。
常见问题
Q: 每个功能都要走完整流程吗?
不必。简单改动可以直接编码,复杂功能建议至少完成 specify + plan。
Q: 规格写得很详细,但 AI 还是生成了不符合预期的代码?
检查规格是否真的「详细」。很多时候我们以为说清楚了,实际上还有模糊点。尝试运行 /speckit.clarify 看看有没有遗漏。
Q: 可以跳过某些步骤吗?
可以。最小流程是 specify → tasks → implement。但跳过 clarify 和 plan 可能增加后期返工风险。
Q: 如何修改已生成的规格?
直接编辑 spec.md 文件即可。修改后建议重新运行 plan 和 tasks 以保持一致性。
Q: AI 生成的代码完全不对,怎么调试?
分几步排查:
- 检查规格:规格是否真的清晰?尝试运行
/speckit.clarify看有没有遗漏 - 检查计划:plan.md 中的技术方案是否合理?如果不合理,直接编辑后重新生成 tasks
- 缩小范围:让 AI 只执行一个任务,观察输出是否符合预期
- 添加约束:在 constitution.md 中添加更明确的技术偏好
Q: Plan 和 Tasks 之间不一致怎么办?
运行 /speckit.analyze 可以检测不一致。常见原因:
- Plan 更新后忘记重新生成 Tasks
- 手动编辑了 Tasks 但没更新 Plan
- 规格变更后只更新了部分文档
解决方案:以 spec.md 为准,依次重新生成 plan.md 和 tasks.md。
Q: 如何处理跨功能的依赖?
如果功能 B 依赖功能 A,有两种方式:
- 合并规格:把 A 和 B 写进同一个 spec.md,让 AI 统一规划
- 分阶段开发:先完成 A 的完整流程,再开始 B 的 specify
不建议同时开发有依赖关系的多个功能,容易造成集成问题。
小结
Speckit 的核心价值不是增加流程,而是把隐性知识显性化。当你被要求写下用户故事、功能需求、成功标准时,那些你以为「不言自明」的细节就会浮出水面。
记住这个流程:
Specify → Clarify → Plan → Tasks → Implement
需求 澄清 设计 分解 执行每一步都在为下一步减少歧义。最终,AI 拿到的是清晰的任务清单,而不是模糊的意图描述。
现在,回到你的项目,试着用 /speckit.specify 开始你的第一个规格驱动开发流程吧。
延伸阅读
- 《规格驱动开发是什么》— 回顾核心理念
- 《GSD 深度解析》— 另一个采用规格驱动思想的上下文工程系统
- 《Claude Skills 是什么》— Speckit 本身就是一个 Claude Skill