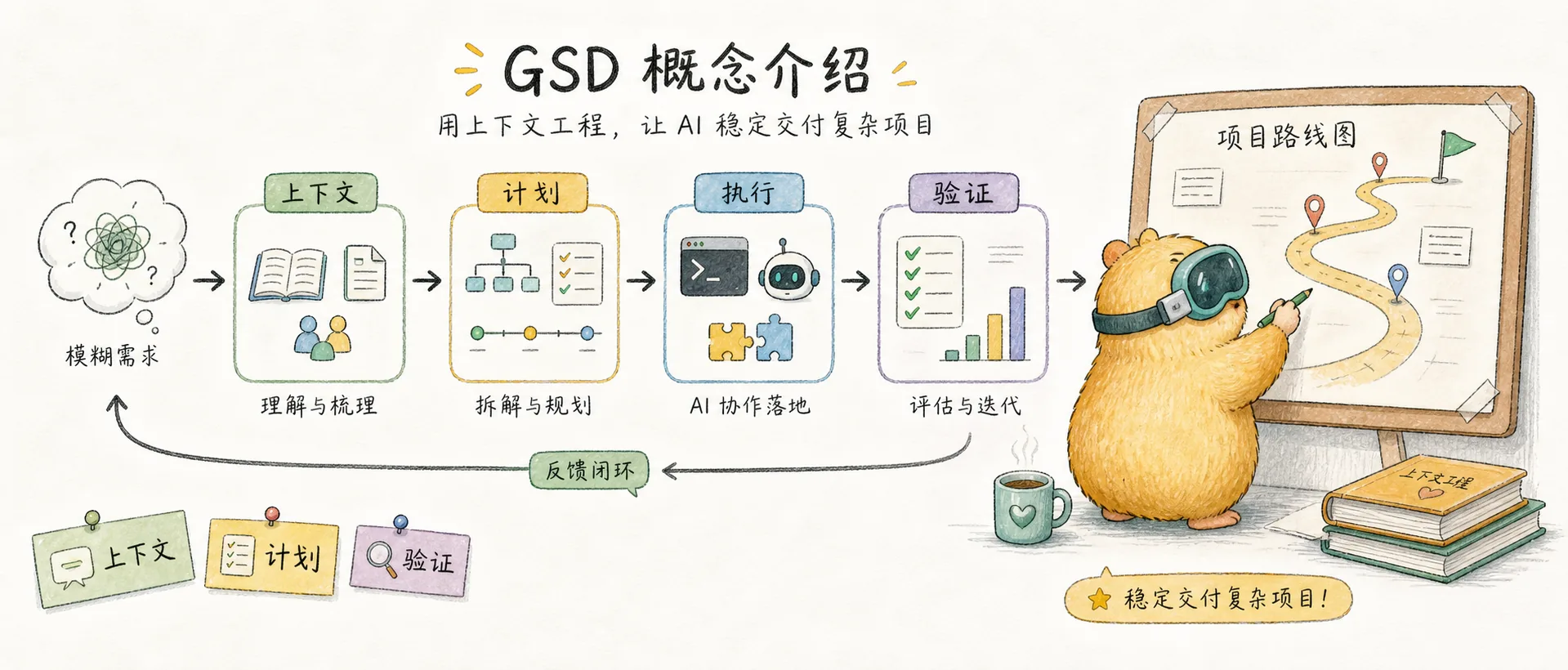
GSD 概念介绍
理解 GSD 的核心原理:一个让 Claude Code 可靠地完成复杂项目的上下文工程系统
引言
在 Ralph Wiggum 深度解析 中,我们了解了一个核心问题:Context Rot——随着对话越来越长,Claude 的上下文窗口被失败代码、过时讨论和无关信息填满,输出质量不断下降。
Ralph 的解决方案是"重启一切":用 bash 无限循环每次启动全新的 Claude 实例,通过文件系统传递状态。简单,有效,但也有明显的局限——它只是一个方法论,没有项目理解、没有阶段规划、没有质量验证。你需要自己写 spec、自己编排任务、自己判断"完成了没有"。
正如 Chase AI 在视频中精准概括的:Ralph Loop 是一个极其强大的武器,但大多数人需要的不是一件武器——而是整个军火库。 Ralph 循环完全依赖于前置准备:你的 PRD 够不够好?功能定义够不够紧凑?你知道"完成"长什么样吗?如果这些问题的答案不精确,那无论循环运行多少次,都只是 garbage in, garbage out。
如果你想要一个不只是循环运行 Claude,而是真正理解你的项目并可靠地交付代码的系统呢?
复杂性在系统中,而不是在你的工作流中。背后是上下文工程、XML 提示格式化、子代理编排、状态管理。你看到的只是几个简单命令。
这就是 GSD (Get Shit Done) 要做的事。
什么是 GSD
一个轻量级的元提示、上下文工程和规格驱动开发系统,为 Claude Code、OpenCode 和 Gemini CLI 设计。核心解决 context rot 问题——通过结构化的工作流、子代理编排和文件系统状态管理,让 AI 编程工具可靠地完成复杂项目。
GSD 的创建者是 TÂCHES (GitHub: glittercowboy),一位独立开发者。他的动机很直接:
"我不是 50 人的软件公司。我不想玩企业戏剧。我只是一个想做出好东西的创意人。"
在他的直播中,TÂCHES 展示了一个令人震撼的事实:他从不手写代码。他用 GSD 在 4 小时内从零构建了一个完整的 macOS 原生音乐生成应用(Sample Digger),全程零手写代码。他的自我定位不是程序员,而是"高层项目经理"——描述愿景、做关键决策、验证结果。GSD 让这种工作方式成为可能。
"This has like 100x'd my ability to make cool shit with Claude Code because it's just created this systematization."
—— TÂCHES
其他规格驱动开发工具——BMAD、SpecKit——都有各自的价值,但它们倾向于引入复杂的企业工作流:sprint ceremonies、story points、stakeholder syncs。对于独立开发者或小团队来说,这些流程本身就是负担。正如 Chase AI 评价的:"It's not enterprise theater. We understand that you're just one person, you just want some sort of scaffolding around Claude Code to make sure it executes the tasks it says it's going to execute in an effective way."
GSD 的设计哲学是把复杂性藏在系统里。用户只需要几个简单的命令,系统在背后处理所有的上下文管理、任务编排和质量验证。项目发布一个月内就获得了近 3,000 GitHub stars 和 14,000 npm 安装量,TÂCHES 几乎每天更新 15-20 次。
GSD 在工具生态中的位置
| 维度 | Ralph Wiggum | SpecKit | BMAD | GSD |
|---|---|---|---|---|
| 核心定位 | 执行技术(bash loop) | 规格生成工具包 | 企业级框架 | 上下文工程 + 规格驱动 |
| 规划能力 | 无(需自备 spec) | 强(spec→plan→tasks) | 强(完整敏捷流程) | 强(研究→讨论→规划) |
| 执行自主性 | 最高(AFK 模式) | 需手动触发每步 | 需手动触发每步 | 需手动触发每步 |
| 人类参与模式 | Human on the Loop | Human in the Loop | Human in the Loop | Human in the Loop |
| Context Rot 处理 | 新 session 重启 | 无内置方案 | 无内置方案 | 子代理新鲜上下文 |
| 质量验证 | 依赖外部测试 | 构建检查 | 内置 QA 流程 | 自动验证 + UAT |
| 用户复杂度 | 最低 | 中等 | 较高 | 低 |
| 系统复杂度 | 最低 | 中等 | 较高 | 高 |
这张表揭示了一个关键取舍:Ralph 用最低的系统复杂度换取了最高的执行自主性——启动后就可以去睡觉;而 GSD 用高系统复杂度换取了规划质量和人类校验——每个阶段都有你介入的机会。SpecKit 和 BMAD 落在中间地带,提供规划能力但缺少 GSD 的上下文工程和 Ralph 的自主执行。
GSD 和 Ralph 并不矛盾。GSD 继承了 Ralph 的核心原则——新鲜上下文、文件作为真相来源——但在此基础上构建了完整的项目理解和执行体系。如果 Ralph 是"给 AI 一个任务让它反复尝试",GSD 就是"理解你要什么,研究怎么做,规划怎么分步,执行并验证"。
Chase AI 的总结非常到位:Ralph 循环假设你带着完整蓝图来——GSD 帮你构建这个蓝图。 GSD 接过你半成型的想法,深入提问、代为研究、生成完整 PRD、将其拆解为原子任务,然后端到端地交付项目。而在执行代码时,它使用的正是让 Ralph 循环强大的那些基础原则:子代理的新鲜上下文,以及尽可能小而精确的任务。
GSD - 把事情搞定
一个轻量级且强大的元提示、上下文工程和规格驱动开发系统,支持 Claude Code、OpenCode 和 Gemini CLI。
核心工作流
GSD 的工作流是一个讨论 → 计划 → 执行 → 验证的循环,每个阶段都有明确的输入和输出。
1. 初始化项目
/gsd:new-project一个命令启动整个流程。系统会:
- 提问 — 持续追问直到完全理解你的想法(目标、约束、技术偏好、边界情况)
- 研究 — 派出并行代理调查相关领域(可选但推荐)
- 需求提取 — 区分 v1、v2 和超出范围的内容
- 路线图 — 创建与需求对应的阶段规划
你审批路线图,然后开始构建。TÂCHES 的经验是:提供的初始描述越详细,系统追问得越少;越模糊,追问越多。他建议在启动前先准备一份粗略的愿景文档——不需要知道技术栈或实现细节,只需要描述你想要什么。
产出文件: PROJECT.md、REQUIREMENTS.md、ROADMAP.md、STATE.md
已有代码库?先运行
/gsd:map-codebase,系统会派出并行代理分析你的技术栈、架构、约定和潜在问题。之后/gsd:new-project就能基于已有代码库进行规划。
2. 讨论阶段
/gsd:discuss-phase 1路线图里每个阶段只有一两句话的描述,这不足以构建你想要的东西。讨论阶段的作用是在研究和规划之前,捕获你的实现偏好。
系统会分析当前阶段,识别"灰色地带"——那些有多种合理实现方式的决策点:
- 视觉功能 → 布局、交互、空状态处理
- API/CLI → 响应格式、错误处理、详细程度
- 内容系统 → 结构、语气、深度、流程
你在这里做的每个决定都会直接影响后续的研究和规划质量。跳过这步也可以(系统会用合理默认值),但深入讨论能让系统构建出更符合你期望的东西。
产出文件: {phase}-CONTEXT.md
3. 计划阶段
/gsd:plan-phase 1系统会:
- 研究 — 调查如何实现当前阶段,以讨论阶段的决策作为指导
- 计划 — 创建 2-3 个原子任务计划,使用 XML 结构化格式
- 验证 — 检查计划是否满足需求,循环修正直到通过
一个重要的设计理念是 Goal-Backward Planning(目标回溯规划)。不是从"我们应该构建什么"出发,而是问"为了实现目标,什么条件必须成立?"——然后反向推导出计划和任务。TÂCHES 表示这种方式"极大地提升了输出质量",因为每个任务都理解自己和其他任务的关系,而不只是一个待办列表。
每个计划足够小,可以在一个全新的上下文窗口中执行。这是关键——不会有质量退化。
产出文件: {phase}-RESEARCH.md、{phase}-{N}-PLAN.md
4. 执行阶段
/gsd:execute-phase 1系统会:
- 波次执行 — 独立任务并行执行,有依赖的按顺序
- 新鲜上下文 — 每个计划在全新的 200k tokens 上下文中执行,零累积垃圾
- 原子提交 — 每个任务独立 git commit
- 目标验证 — 检查代码库是否实现了阶段承诺的功能
在 TÂCHES 的直播演示中,他完成了 3 个完整阶段的开发,主上下文窗口始终保持在 24%。GSD Executor 子代理只需要加载不到 1,000 行的上下文就能完成一个完整阶段——你可以连续执行 10 个计划,上下文仍然低于 50%。这和直接在 Claude Code 中工作的体验完全不同:不再是"玩俄罗斯轮盘赌,赌什么时候撞到上下文窗口的墙"。
产出文件: {phase}-{N}-SUMMARY.md、{phase}-VERIFICATION.md
5. 验证阶段
/gsd:verify-work 1自动化验证能检查代码是否存在、测试是否通过。但功能是否按你的预期工作?这需要你来确认。
系统会:
- 提取可测试的交付物 — 列出你现在应该能做到的事情
- 逐一引导验证 — "能用邮箱登录吗?" 是/否,或描述问题
- 自动诊断失败 — 派出调试代理查找根因
- 创建修复计划 — 可直接执行的修复方案
如果一切通过,继续下一阶段。如果有问题,再次运行 /gsd:execute-phase 执行修复计划。
这是 GSD 和 Ralph 循环最大的理念差异:Ralph 是 hands-off 的——启动后放手让它跑;GSD 在每个阶段结束后都有人类验证环节。 Chase AI 指出,Ralph 循环是"去征服型"的——它自行运转不回头;GSD 确保你在每个关键节点都能介入纠偏,避免错误在无人监督下层层叠加。
此外,GSD 还提供了专用调试流程。当验证发现问题时,/gsd:debug 会启动一个隔离的调试子代理,它有自己的假设-证据-解决工作流,创建独立的调试文档追踪整个调查过程,不污染主上下文。
产出文件: {phase}-UAT.md
循环重复
/gsd:discuss-phase 2 → /gsd:plan-phase 2 → /gsd:execute-phase 2 → /gsd:verify-work 2
...
/gsd:complete-milestone → /gsd:new-milestone每个阶段都经历完整的讨论 → 计划 → 执行 → 验证循环。上下文保持新鲜,质量保持一致。
当所有阶段完成后,/gsd:complete-milestone 归档里程碑并标记版本。然后 /gsd:new-milestone 开启下一个版本的构建。
为什么有效:技术原理
GSD 的可靠性不是偶然的,背后有四个关键技术支撑。
Context Engineering
Claude Code 在获得正确上下文时非常强大。大多数人不知道如何给它正确的上下文。GSD 替你处理了这个问题。
| 文件 | 作用 |
|---|---|
PROJECT.md | 项目愿景,始终加载 |
research/ | 生态知识(技术栈、功能、架构、陷阱) |
REQUIREMENTS.md | 分版本的需求,带阶段追溯 |
ROADMAP.md | 方向和进度 |
STATE.md | 决策、阻碍、位置——跨 session 的记忆 |
PLAN.md | 原子任务 + XML 结构 + 验证步骤 |
SUMMARY.md | 执行记录,提交到历史 |
每个文件都有基于 Claude 质量退化阈值的大小限制。保持在限制之下,就能获得一致的高质量输出。主上下文窗口保持在 30-40%,实际工作在子代理的全新 200k 上下文中完成。
Chase AI 对 context rot 有一个直观的解释:无论上下文窗口多大——Sonnet、Opus、甚至百万 token 的窗口——前半段的 token 都比后半段更有效。 这不是 bug,这是 LLM 的固有特性。Claude Code 内置的 autocompact 只能部分缓解。GSD 的方案更彻底:每个原子任务都在全新的子代理中执行,确保每一个任务都能获得 Claude 的最佳表现。
TÂCHES 自己的数据印证了这一点:他在 $200/月的 Max 计划上,每月消耗约 $30,000 的 Opus tokens。这听起来很多,但因为每个任务都在新鲜上下文中执行,返工极少,实际效率远高于在一个退化的上下文中反复修修补补。
XML Prompt Formatting
每个计划都是为 Claude 优化的结构化 XML:
<task type="auto">
<name>Create login endpoint</name>
<files>src/app/api/auth/login/route.ts</files>
<action>
Use jose for JWT (not jsonwebtoken - CommonJS issues).
Validate credentials against users table.
Return httpOnly cookie on success.
</action>
<verify>curl -X POST localhost:3000/api/auth/login returns 200 + Set-Cookie</verify>
<done>Valid credentials return cookie, invalid return 401</done>
</task>精确的指令,不需要猜测,验证内置在每个任务中。
Multi-Agent Orchestration
每个阶段使用相同的模式:薄编排器派出专门化代理,收集结果,路由到下一步。
| 阶段 | 编排器做什么 | 代理做什么 |
|---|---|---|
| 研究 | 协调、展示发现 | 4 个并行研究员调查技术栈、功能、架构、陷阱 |
| 规划 | 验证、管理迭代 | 规划者创建计划,检查者验证,循环直到通过 |
| 执行 | 分组波次、跟踪进度 | 执行者并行实现,各自拥有全新 200k 上下文 |
| 验证 | 展示结果、路由下一步 | 验证者检查代码库,调试者诊断失败 |
编排器从不做重活。它派出代理、等待、整合结果。结果是:你可以运行一整个阶段——深度研究、多个计划创建和验证、数千行代码并行编写、自动验证——而你的主上下文窗口保持在 30-40%。
Atomic Git Commits
每个任务完成后立即独立提交:
abc123f docs(08-02): complete user registration plan
def456g feat(08-02): add email confirmation flow
hij789k feat(08-02): implement password hashing
lmn012o feat(08-02): create registration endpoint好处:git bisect 能定位到具体的失败任务,每个任务可独立回滚,清晰的历史记录帮助 Claude 在未来 session 中理解代码演变。
GSD 的边界
GSD 很强大,但理解它做不到什么同样重要。
GSD 是人类引导的工作流,不是自主代理
GSD 不能持久化运行。每个阶段边界——从 discuss 到 plan 到 execute 到 verify——都需要你手动输入命令。你不能说"帮我做个 app"然后去睡觉。
这和 Ralph 的 AFK 模式形成了鲜明对比。Ralph 就是设计来"启动后去睡觉"的——bash 无限循环会持续运行,直到任务完成或失败。GSD 则要求你在每个关键节点都在场:审批路线图、回答讨论问题、触发规划、启动执行、确认验证结果。
TÂCHES 在直播中 4 小时里一直在键入命令:new-project、discuss-phase 1、plan-phase 1、execute-phase 1、verify-work 1、discuss-phase 2……每一次转换都需要他按回车。这不是偶然的——这是有意识的设计选择。
我们不是在追求尽可能快地一步到位。我们是方法论驱动的。
一个有意识的设计取舍
Ralph 牺牲了规划能力换取了执行自主性;GSD 牺牲了执行自主性换取了规划质量和人类校验。这是设计取舍,不是缺陷。
- Ralph 的优势:你可以在睡觉时让它跑完一整个功能。但如果 spec 不够好,它会在错误的方向上一路狂奔。
- GSD 的优势:每个阶段结束后你都能纠偏。但你必须全程在场,不能离开。
理想状态是什么?如果 GSD 的讨论、规划、执行、验证能串成一个自动循环——类似 Ralph 的 bash loop,但带有 GSD 的结构化规划和质量验证——那就是两个世界的最佳组合。但目前还没有这样的工具。这也许是下一个值得探索的方向。
视频资源
以下视频可以帮助你更直观地理解 GSD 的使用方式和效果。
写在最后
GSD 代表了 AI 编程工具演进的一个方向:从"让 AI 写代码"到"让 AI 可靠地交付项目"。
Ralph Wiggum 证明了一个关键洞察——新鲜上下文比累积上下文更有价值。GSD 在这个基础上,加入了项目理解(new-project)、决策捕获(discuss)、结构化规划(plan)、并行执行(execute)和质量验证(verify),形成了一个完整的闭环。
对于独立开发者和小团队来说,GSD 的价值在于它把复杂的工程实践封装成了几个简单命令。你不需要理解子代理编排或 XML 提示工程——你只需要描述你想要什么,然后让系统去搞定。
Chase AI 说得好:GSD 适合那些"不来自技术背景,但仍然想在 Claude Code 中以可持续、可重复的方式端到端构建项目"的人。而 TÂCHES 的直播证明了这一点——一个自称"可能只能自己写一个 Hello World HTML 页面"的人,用 GSD 构建了一个完整的原生桌面应用。
这不是魔法。这是把正确的复杂性放在正确的地方——系统承担编排的复杂性,人类专注于创意和决策。而它的边界同样值得尊重:GSD 选择了让人类始终在场,这既是它的限制,也是它可靠性的来源。
想要上手实操?继续阅读 GSD 实践指南——涵盖完整命令参考、配置详解、实战工作流演示和常见问题。
相关阅读:
- Ralph Wiggum 深度解析 — Context Rot 问题和 Ralph 方法论的完整解析
- 规格驱动开发是什么 — 从 Vibe Coding 到规格驱动开发的范式升级
- Claude Subagent 完全指南 — 另一种保持上下文清洁的方式
- Claude 系统架构全解析 — Hooks、Subagent 等组件的整体架构
- 我的 Claude Code 最佳实践 — Claude Code 日常使用技巧