我的 Claude Code 质量检查流程
分享我使用 Claude Code 时的质量检查实践:Hooks 自动化、测试策略、AI Review、Pre-commit、GitHub 集成5道防线
为什么要关注 AI 编程的质量控制?
在使用 Claude Code 进行 AI 编程的过程中,我发现了一个重要的现象:虽然 Claude Code 能让开发速度提升 2-3 倍,但这种 AI 辅助编程的效率提升也带来了新的挑战——AI 生成的代码需要更严格的质量检查和质量控制。
没有适当的质量检查流程,我的 Claude Code 工作效率反而会因为频繁的调试和重构而降低。
这让我意识到一个核心原则:AI 的输出需要验证,而不是盲目信任。
经过半年的实践和优化,我建立了一套完整的质量保障体系。接下来我会分享我的质量检查流程,这是一个从自动化检查到人工审查的分层质量控制流程。这套流程是渐进式的——你可以从最基础的部分开始,根据需要逐步增强。
如果你还不熟悉 Claude Code 的基本用法,可以先阅读《Claude Code 10大最佳实践》了解基础工作流。
开始之前:让检查更顺畅的两个准备
在进入具体的检查流程之前,有两个准备工作能让后续的质量检查事半功倍。
按功能组织代码
项目代码的组织方式通常有两种选择:按技术层分类(分层架构)或按业务功能分类(按功能组织)。在 AI 辅助编程的场景下,我选择了后者:
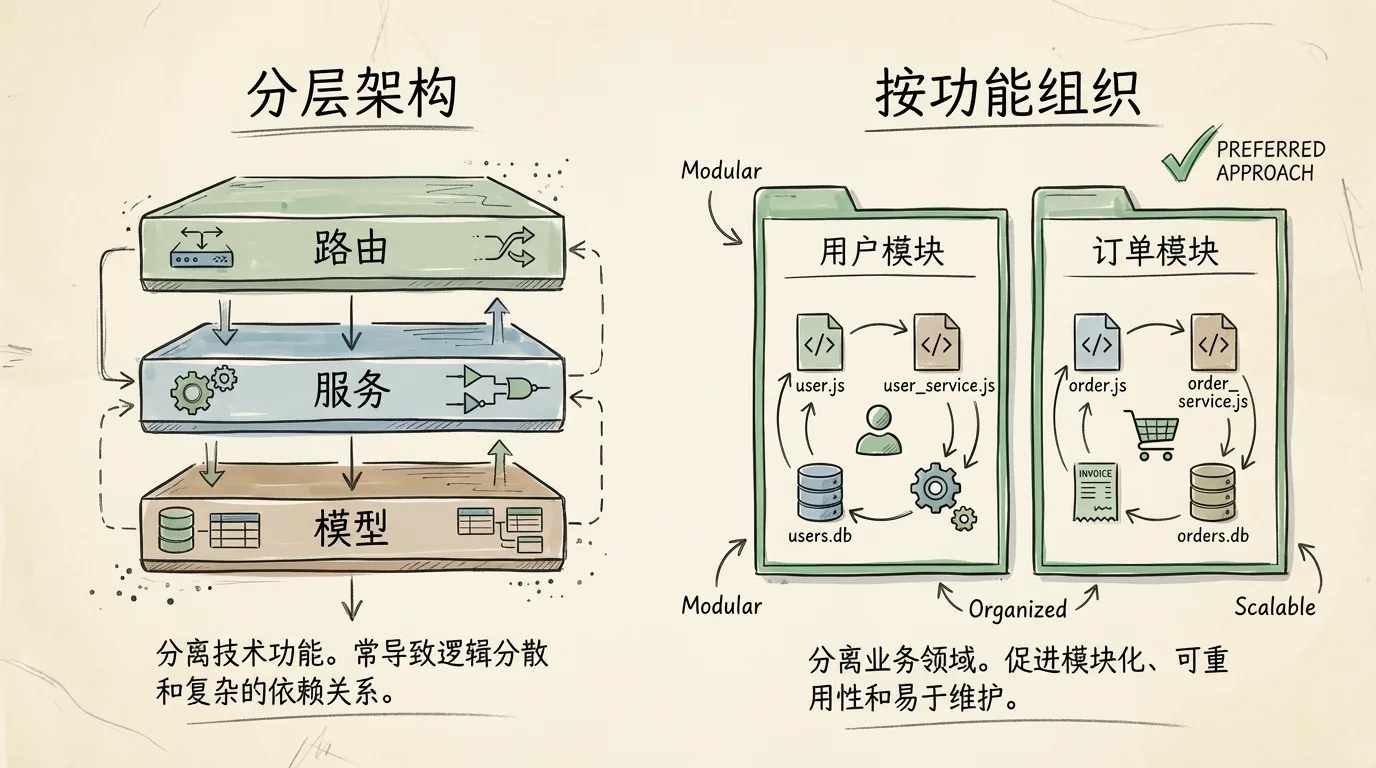
分层架构
src/
├── routers/ # 所有路由/API 端点
├── services/ # 所有业务逻辑
├── repositories/ # 所有数据访问
└── models/ # 所有数据模型按功能组织架构
src/
├── user/
│ ├── __init__.py # Python 包标识
│ ├── router.py # FastAPI 路由定义
│ ├── service.py # 业务逻辑
│ ├── models.py # 数据库模型(SQLAlchemy)
│ ├── schemas.py # Pydantic 数据验证
│ └── CLAUDE.md # 模块特定规范
└── order/
├── __init__.py
├── router.py
├── service.py
├── models.py
└── schemas.py为什么按功能组织对 AI 更友好?
举个例子:当我让 Claude 修改评论功能时,如果是分层架构,它需要分别读取 routers/review.py、services/review_service.py、models/review_model.py,可能还有 schemas/review_schema.py——至少 4 个不同目录的文件。而按功能组织时,所有相关文件都在 src/review/ 目录下,AI 可以一次性理解整个模块的上下文。
此外,每个模块可以有自己的 CLAUDE.md,定义该模块的特定规则和约束。这让 AI 在不同模块间切换时,能自动适应不同的开发规范。
用 Make 命令统一入口
每个新项目的第一件事,我都会创建一个 Makefile。为什么?
当 AI 帮你写代码时,它需要知道项目的"规则"。与其每次都告诉 Claude "请运行 ruff check && mypy . && pytest",不如直接说 "运行 make check"。
这是我的基础 Makefile 模板:
.PHONY: help setup dev run stop format check test clean
help: ## 显示帮助信息
@grep -E '^[a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | awk 'BEGIN {FS = ":.*?## "}; {printf " %-15s %s\n", $$1, $$2}'
setup: ## 初始化开发环境(安装依赖 + git hooks)
@echo "📦 Installing dependencies..."
uv sync
@echo "🔧 Installing pre-commit hooks..."
uv run pre-commit install
dev: ## 本地开发模式(支持热重载)
@echo "🚀 Starting dev server with hot reload..."
uvicorn main:app --reload --host 0.0.0.0 --port 8000
run: ## 生产模式(多 worker)
@echo "🚀 Starting production server..."
uvicorn main:app --workers 4 --host 0.0.0.0 --port 8000
stop: ## 停止后台运行的服务
@echo "🛑 Stopping server..."
# 停止服务的逻辑
format: ## 格式化代码
@echo "🎨 Formatting code..."
black .
ruff check --fix .
check: ## 代码检查 + 类型检查 + 测试
@echo "🔍 Checking code..."
ruff check .
mypy .
pytest
test: ## 运行测试
@echo "🧪 Running tests..."
pytest
clean: ## 清理缓存文件
@echo "🧹 Cleaning up..."
find . -type d -name "__pycache__" -exec rm -rf {} + 2>/dev/null || true
find . -type d -name ".pytest_cache" -exec rm -rf {} + 2>/dev/null || true为什么这样做有效?
- 统一的命令接口:无论项目使用什么技术栈,
make format、make test始终有效 - AI 友好:Claude 更容易记住和使用这些简洁的命令
- 强制规范:团队成员(或未来的你)都知道该运行什么命令
这种简单的规范化减少了重复沟通,对于 AI 辅助开发来说尤其有效。
完整的 AI 编程质量检查流程
第一道防线:Hooks 自动检查
在 Claude Code 的质量检查流程中,最基础的一环是自动化检查。
每次 Claude 完成代码编写后,我配置的 Hook 会自动运行格式化:
{
"hooks": {
"Stop": [{
"hooks": [{
"type": "command",
"command": "make format",
"timeout": 60
}]
}]
}
}这确保了代码风格的一致性,无需人工干预。
第二道防线:测试策略
关于 Mock,我的做法可能和很多人不同:能不 Mock 就不 Mock。
原因很简单,Mock 测试通过了,不代表真实环境能跑。我遇到过好几次这种情况:单元测试全绿,一上线就出问题,因为 Mock 掩盖了真实的边界条件。对于 AI 生成的代码,这个问题更明显:AI 写测试时容易"配合"自己的代码——为了让测试通过而写,而不是真正验证边界情况。集成测试能更有效地发现这类问题。
当然,有些场景必须 Mock:调用付费 API、时间相关的逻辑、不稳定的第三方服务。但除此之外,我更倾向于写集成测试。
至于覆盖率,我的目标是 80%——覆盖核心逻辑就够了,不必追求 100%。修改某个模块时,跑 pytest tests/user/ 就能快速验证,不用等全量测试。
为了让 Claude 遵循这套测试策略,我会在 CLAUDE.md 里写清楚要求:
## 测试规范
- 实现新功能时,先写测试,确认测试失败,再写实现代码
- 每次修改后运行 `make test` 确保没有破坏现有功能
- 不要为了让测试通过而修改测试本身
- 外部 API、时间相关逻辑使用 Mock,其他场景优先使用真实依赖第三道防线:本地 AI Review
对于大的改动,我会使用 Claude Code 的 Commands 进行代码审查。通常我会让 Claude 审查特定目录的改动,比如"审查 src/order/ 这次的修改",上下文更集中。
# 使用专门的审查 Commands
/code-review:code-review何时使用?
- 必须:涉及架构改动、新功能、安全相关
- 推荐:重要的业务逻辑修改
- 可选:小的 bug 修复、简单的文案修改
作为独立开发者,我还会隔一段时间让 Claude 对整个模块做一次 Review。这在团队协作中不太现实——毕竟代码是不同人写的,随意重构容易踩到别人的领地。但独立开发就没这个顾虑,发现问题可以立刻调整。
第四道防线:Pre-commit Hook
这是最关键的一环——如果检查不通过,代码根本无法提交。
我的做法是用 pre-commit 框架配合 make check,配置很简单:
# .pre-commit-config.yaml
repos:
- repo: local
hooks:
- id: make-check
name: Run make check
entry: make check
language: system
pass_filenames: false所有检查逻辑都在 Makefile 里统一管理,pre-commit 只负责在提交时触发。
然后在 Makefile 里加一个 setup 命令:
setup: ## 初始化开发环境
@uv sync
@uv run pre-commit install运行 make setup 后,每次 git commit 都会自动触发 make check。
如果是独立开发,这一步其实可以手动做。但我还是建议配置 setup 命令,这样换台电脑或者重新拉项目时,跑一下 make setup 就能恢复开发环境,不用记那么多步骤,或者重新配置一遍。
这些配置工作本身也可以让 Claude Code 来做——告诉它"帮我配置 pre-commit,提交时运行 make check",它会帮你生成配置文件并安装好。
第五道防线:GitHub 集成
Claude Code 提供了 GitHub 集成功能,可以在每次 Pull Request 时自动触发 AI 代码审查。
在 Claude Code 里运行 /install-github-app,按照提示完成授权流程就行。
安装完成后,你会发现项目里多了 .github/workflows 目录,里面包含了 Claude 的审查工作流配置。
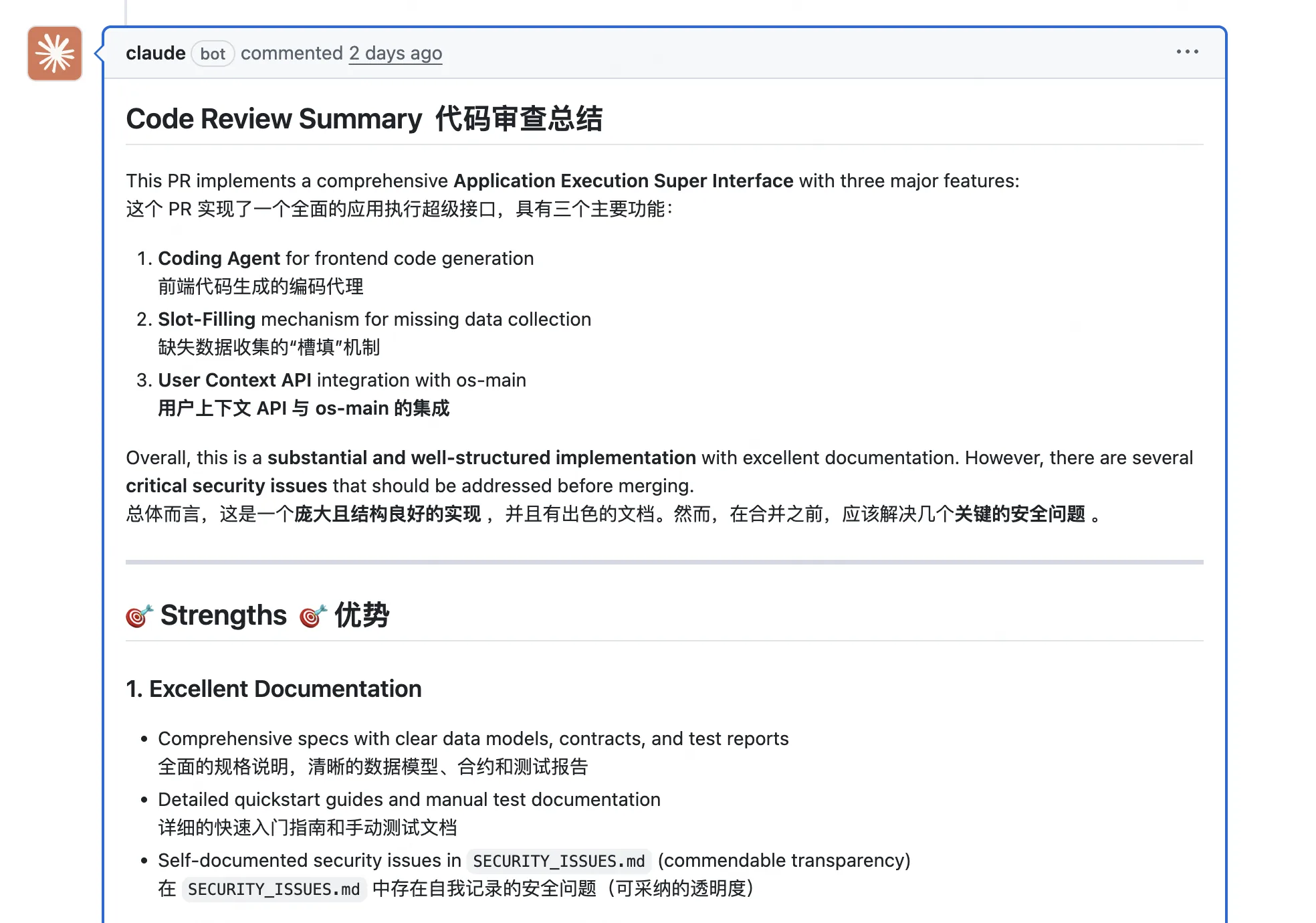
之后每次提交 PR,Claude 都会自动审查代码并在 PR 里留下评论。如果你想调整它的审查风格或关注点,可以直接修改 workflows 里的 prompt 配置。
这是最后一道质量闸门——代码在合并前会再过一遍 AI 审查,确保没有遗漏的问题。
质量检查体系总览
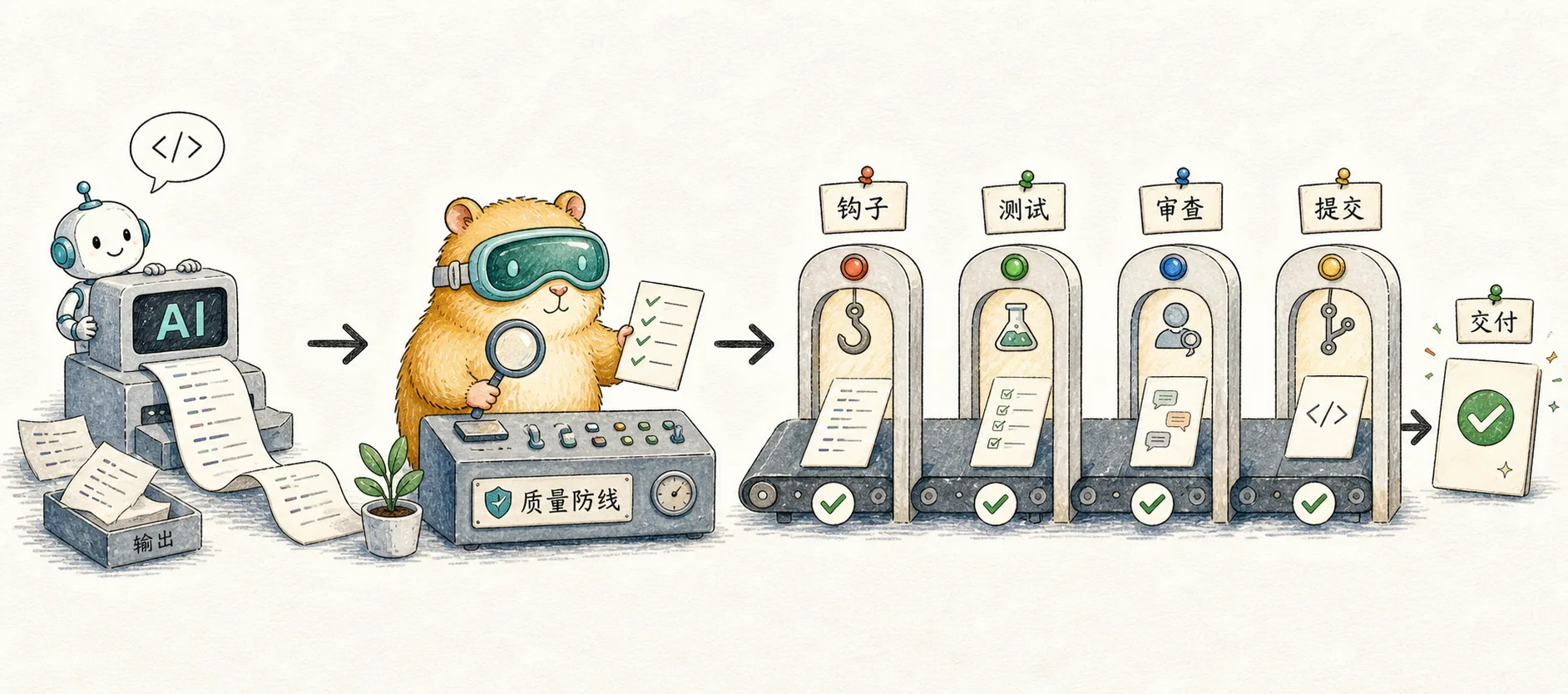
这五层防线组成了一个完整的质量保障体系:
| 防线 | 检查方式 | 触发时机 | 作用 |
|---|---|---|---|
| Hooks | 自动化 | 代码编写完成后 | 保证代码风格一致 |
| 测试 | 手工 + 自动 | 功能实现后 | 发现逻辑问题 |
| AI Review | AI 审查 | 大改动时 | 获得即时反馈 |
| Pre-commit | 自动化 | 提交前 | 防止低质量代码入库 |
| GitHub 集成 | AI 审查 | PR 时 | 最后审查门槛 |
这个质量检查流程从自动化到人工,从本地到云端,确保了 Claude Code 生成代码的质量。
总结:AI 时代的质量控制体系
AI 编程的时代已经到来,但质量控制永远不会过时。
这套完整的 Claude Code 质量检查流程,将五个环节的质量控制串联起来,形成了一个防守严密的质量保障体系。无论你使用什么 AI 编程工具,这套质量检查的思想都是通用的。
希望这篇关于 AI 编程质量控制的详细经验分享,能帮助你建立起适合自己的质量保障体系。如果有任何问题或想分享你的实践经验,欢迎留言讨论!
延伸阅读
- 《Claude 系统架构全解析》— 理解 Hooks、Skills 等组件在架构中的定位
- 《从 Eclipse 到 Zed:一个开发者的编辑器进化史》— 编辑器轻量化 + 终端重度化的工作流演进
- 《GSD 深度解析》— 另一种规格驱动的 AI 编程质量保障思路