Améliorer l'architecture de base de code : restructurer superficiellement en modules profonds
La dernière étape du flux de travail de Matt Pocock consiste à analyser périodiquement la base de code à la recherche d’« opportunités d’approfondissement ». Comprendre en profondeur la théorie des modules profonds de John Ousterhout, le test de suppression original de Matt et pourquoi cette compétence est particulièrement nécessaire à l'ère de l'IA.
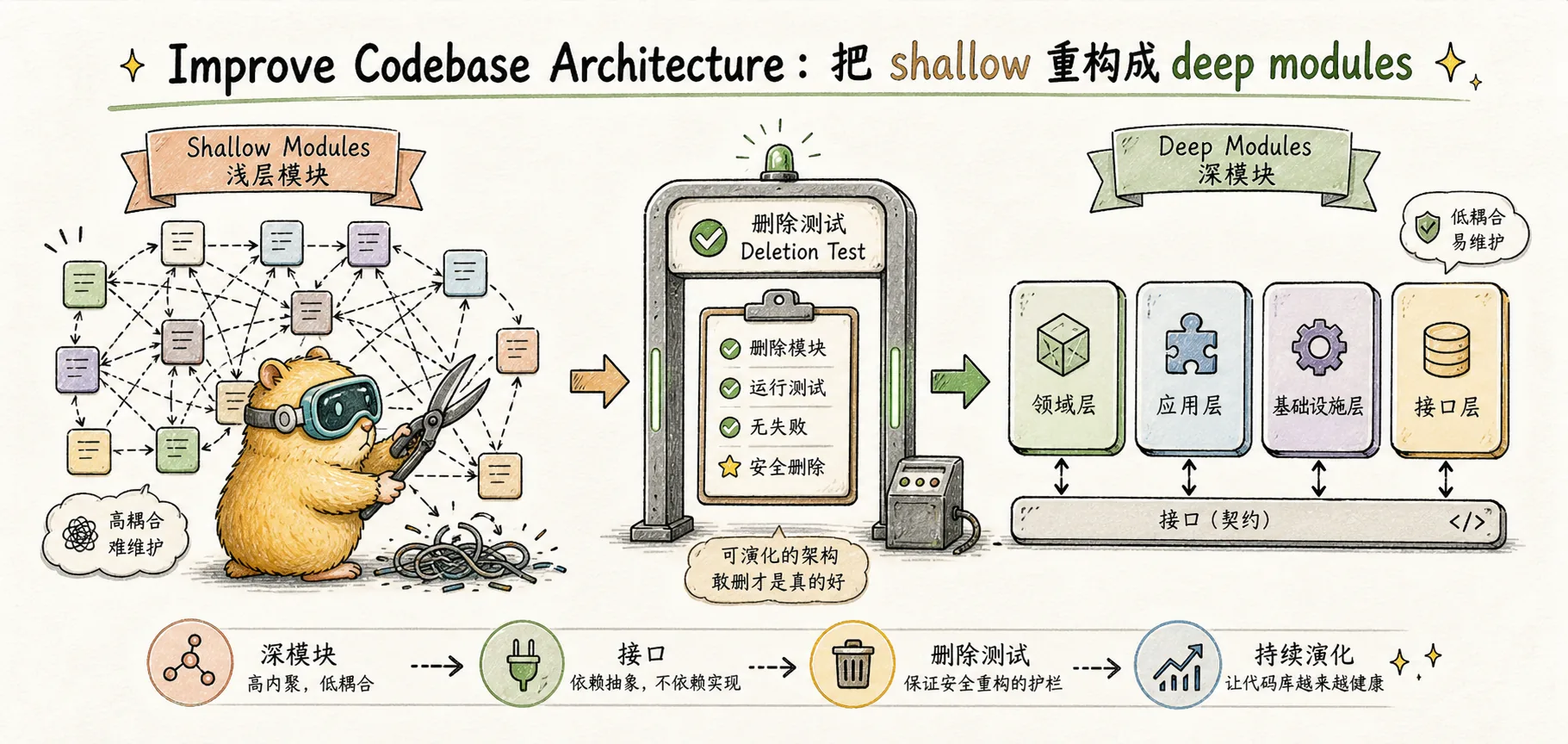
Modules should be relatively few large deep modules with simple interfaces. Deep modules: lots of functionality hidden behind a simple interface.
Mode d'échec : "L'IA se promène dans une mauvaise base de code"
Le quatrième mode d’échec dans le discours de Matt est une métaphore illustrée :
"Les modules superficiels dans une base de code ressemblent à ceci : vous avez un tas de petits blobs, et l'IA doit parcourir un tas de modules et comprendre toutes les dépendances avant de pouvoir les corriger."
"AI is really good at creating codebases like this. So you'll have a situation where AI doesn't understand what your code is doing. It will attempt to explore the code, but because it's poorly laid out, filled with shallow modules, it doesn't get to the right module in time, or doesn't understand all the dependencies."
Il s’agit d’un cercle vicieux propre à la programmation de l’IA :
AI 写代码倾向于产生 shallow 模块(小、多、互相依赖)
↓
代码库变得 shallow
↓
下次 AI 进来探索更难,更容易写错
↓
更多 shallow 模块被加进去
↓
代码库越来越烂,AI 越来越无能Pour rompre ce cycle, une refactorisation inverse manuelle doit être effectuée périodiquement - en fusionnant les modules superficiels en modules profonds. C'est exactement ce que fait /improve-codebase-architecture.
Théorie classique : les modules profonds d'Ousterhout
John Ousterhout est professeur d'informatique à Stanford (et auteur du langage Tcl et des articles Raft). Son livre de 2018 « A Philosophy of Software Design » propose une règle simple mais puissante :
La "profondeur" du module = la complexité cachée de l'interface
| Tapez | Interfaces | Mise en œuvre | Images |
|---|---|---|---|
| Profond | Simple | Riche | Un rectangle : étroit et profond |
| ** Peu profond ** | Complexe | Simple | Un rectangle : large et peu profond |
Le module idéal est profond : les utilisateurs n'ont besoin que de voir l'interface courte et la complexité est cachée à l'intérieur. Un contre-exemple extrême est le module superficiel : l’interface est presque aussi complexe que l’implémentation, ce qui signifie qu’il n’y a pas d’encapsulation. Les utilisateurs pourraient tout aussi bien examiner directement l’implémentation.
Le jugement d'Ousterhout : Les bonnes bases de code sont composées d'un petit nombre de modules approfondis ; les mauvaises bases de code sont composées d'un grand nombre de modules peu profonds. Ceci est complètement à l'opposé du dogme traditionnel consistant à "garder les fonctions aussi petites que possible, les fichiers aussi courts que possible et les modules aussi nombreux que possible" - il pense que ce genre de dogme produit des modules exactement superficiels.
Extension de Matt : Test de suppression
Matt a traduit la théorie d'Ousterhout en un test d'ingénierie opérationnelle, qu'il a appelé le test de suppression :
Imagine deleting the module. If complexity vanishes, it was a pass-through. If complexity reappears across N callers, it was earning its keep.
Mots humains :
- Supprimez-le, la complexité disparaît → Ce module est à l'origine un pass-through (transit), il ne fonctionne pas, alors coupez-le
- Supprimez-le, et la complexité se propagera à N appelants → Cela vous aide à l'origine à cacher la complexité, elle est vraiment profonde, laissez-la
La beauté de ce test est qu'il est bidirectionnel : il peut identifier à la fois « les emballages légers qui doivent être supprimés » et « la logique commune qui doit être extraite ». Si vous constatez qu'après avoir supprimé un morceau de code, la complexité s'étendra à 5 endroits, cela signifie que ce code mérite d'être extrait dans un module approfondi.
Termes clés (définition précise de Matt)
Il existe un glossaire dans improve-codebase-architecture/SKILL.md qui nécessite l'utilisation stricte de ces mots - ne dérivez pas vers « composant », « service », « API » et « limite » :
| Terminologie | Définition |
|---|---|
| Module | Tout ce qui a une interface et une implémentation (fonction/classe/package/slice) |
| Interface | Tout ce que l'appelant doit savoir : types, invariants, modes d'erreur, ordre, configuration (pas seulement les signatures de fonction) |
| Mise en œuvre | Code à l'intérieur du module |
| Profondeur | Le levier à l'interface. Profond = effet de levier élevé, peu profond = l'interface est presque aussi complexe que la mise en œuvre |
| Couture (Couture) | L'emplacement d'une interface - où le comportement peut être modifié sans modification sur place. Utilisez « couture » et non « limite » |
| Adaptateur | Implémenter l'implémentation spécifique d'une interface at Seam |
| Tirer parti | Les avantages que l'appelant tire du « profond » |
| ** Localité ** | Les avantages que les responsables tirent de la « profondeur » : les modifications, les bugs et les connaissances sont tous concentrés en un seul endroit |
Plusieurs principes fondamentaux :
- Test de suppression : voir ci-dessus
- L'interface est la surface de test : les tests ne peuvent être exécutés que via l'interface - c'est la base d'une testabilité approfondie des modules
- Un adaptateur = couture hypothétique. Deux adaptateurs = vraie couture. : Une interface avec une seule implémentation est une fausse couture. Les vrais joints nécessitent au moins deux adaptateurs
La dernière solution est particulièrement contre-intuitive : de nombreuses équipes font abstraction d'une interface à l'avance "pour une expansion future", mais il n'y a en réalité qu'une seule implémentation. Jugement de Matt : inutile, supprimez. Attendez que le second se réalise. Cela a la même origine que YAGNI.
Flux de travail des compétences
1. Explorez
La compétence permet d'abord à l'IA de lire CONTEXT.md et docs/adr/, puis utilise subagent_type=Explore pour envoyer un sous-agent à la base de code.
Au lieu d'une inspiration rigide, utilisez la friction comme signal :
- Where does understanding one concept require bouncing between many small modules?
- Where are modules shallow — interface nearly as complex as the implementation?
- Where have pure functions been extracted just for testability, but the real bugs hide in how they're called (no locality)?
- Where do tightly-coupled modules leak across their seams?
- Which parts of the codebase are untested, or hard to test through their current interface?
Chaque fois que vous trouvez un point suspect, appliquez un test de suppression : sa suppression fera-t-elle disparaître ou étendre la complexité ? La réponse « disperser » est une candidate qui mérite d'être approfondie.
2. Candidats présents (Candidats déclarés)
Présenter une liste numérotée de candidats :
1. Files: src/orders/parser.ts, src/orders/validator.ts, src/orders/normalizer.ts
Problem: 三个文件互相调用,理解 Order 入站需要在三处跳转
Solution: 合并为单一 OrderIntake 模块,对外只暴露 parse(raw) → ValidatedOrder
Benefits:
- Locality: Order 入站的所有逻辑、错误处理、bug 修复集中一处
- Leverage: 调用方从理解 3 个接口降为 1 个
- Tests: 只需测 parse() 的输入输出,不再需要 mock 内部协作Exigences :
- Utilisez le vocabulaire CONTEXT.md pour parler de domaines ("le module de prise de commandes", et non "le FooBarHandler")
- Parlez d'architecture en utilisant le vocabulaire du glossaire ("couture", "profondeur", "localité")
- Ne proposez pas de designs d'interface tout de suite : laissez d'abord les utilisateurs choisir des candidats intéressants
Si un candidat est en conflit avec un ADR existant, mentionnez-le uniquement si le conflit justifie de revoir l'ADR et indiquez-le clairement :
"contradicts ADR-0007 — but worth reopening because…"
Ne déterrez pas toutes les refactorisations interdites par l'ADR.
3. Boucle de grillades
Une fois que l'utilisateur a sélectionné un candidat, passez en mode grillage (hérité de /grill-with-docs) :
- Parcourez l'arbre de conception - contraintes, dépendances, forme du module après approfondissement, ce qui est caché derrière les coutures, quels tests peuvent survivre
- Les effets secondaires surviennent immédiatement :
- Donner au module d'approfondissement un nom qui n'est pas dans CONTEXT.md → Ajoutez-le immédiatement à CONTEXT.md
- Un terme ambigu a été aiguisé dans la torture → Mettez immédiatement à jour CONTEXT.md
- L'utilisateur rejette le candidat pour un motif porteur (critique, quelque chose que les futurs explorateurs doivent savoir) → Proposer de générer des ADR
- Vous souhaitez explorer les différentes conceptions d'interface des modules d'approfondissement → Passer au processus distinct
INTERFACE-DESIGN.md
La maintenance des documents et la transformation de l'architecture se déroulent dans la même conversation : il n'y a pas deux tours.
Cas réel : la pratique de Mejba Ahmed
Le développeur tiers Mejba Ahmed a écrit un article ["Deep Modules: The Claude Code Skill Saving My Codebase"] (https://www.mejba.me/blog/improve-codebase-architecture-skill-deep-modules) pour enregistrer en détail son expérience d'utilisation de cette compétence. Points clés :
- À l'origine, il avait plus de 50 fichiers dans un projet, chaque fichier comportant moins de 100 lignes - Bibliothèque peu profonde typique
/improve-codebase-architecturea manqué 8 candidats d'approfondissement- Il a sélectionné 3 approfondissements (deux modules de traitement de données fusionnés, un ensemble d'outils fusionné)
- Résultat : le nombre de fichiers est passé de 50+ à 30+, mais la taille totale du code reste fondamentalement la même - la complexité est concentrée dans un petit nombre de modules profonds
- Le taux de réussite des changements de code ultérieurs de Claude dans cette bibliothèque a été considérablement amélioré (il a dit "de 60% à 90%", ce qui n'a pas été strictement mesuré, mais cela semblait fort)
Mejba a également un rappel : N'approfondissez pas 8 à la fois. Choisissez-en un seulement à la fois, exécutez le test + commit + observe, puis choisissez le suivant. Sinon, il n’y a aucun moyen de revenir en arrière une fois que vous l’avez terminé.
Comment installer et utiliser
npx skills@latest add mattpocock/skillsVérifiez improve-codebase-architecture + setup-matt-pocock-skills.
Appeler : /improve-codebase-architecture
Rythme recommandé :
- Courir une fois par semaine ou à la fin de chaque sprint
- Ou **exécutez-le une fois après avoir terminé une vague de développement intensif (il est particulièrement facile d'empiler des modules superficiels après l'écriture à haute fréquence du code AI)
- Ne courez pas lorsque vous êtes pressé - cela suggérera de grands changements que vous n'aurez pas le temps de digérer lorsque vous êtes pressé.
Processus typique :
/improve-codebase-architecture- Exploration IA + liste N candidats (avec argument de test de suppression)
- Vous choisissez celui qui vous plaît le plus
- Passez à la conception d'alignement de la boucle de grillage
- Refactoring de l'implémentation de l'IA (il est recommandé de l'exécuter avec
/tdd- le refactoring doit avoir une protection de test) - engager + observer
- Revenez dans une semaine
Pourquoi cette compétence est-elle une « boucle fermée » du flux de travail de Matt ?
Retour au diagramme de flux de travail de Matt :
/grill-me → /to-prd → /to-issues → /tdd → /improve-codebase-architecture → 回到 /grill-meNotez qu'il revient au point de départ. /improve-codebase-architecture n'est pas un outil ponctuel, il s'agit d'une maintenance périodique - car :
- L'IA continue d'ajouter des modules superficiels à la base de code (c'est sa tendance par défaut, et elle s'accumulera si vous écrivez trop)
- À mesure que les affaires continuent d’évoluer, les anciennes coutures deviendront obsolètes.
- Les termes de CONTEXT.md continuent d'être affinés et l'ancienne dénomination ne suivra pas.
Chaque fois que vous exécutez cette compétence, la convivialité de l'IA de la base de code est actualisée. C'est le seul moyen de garder une base de code saine à long terme avec LLM - si vous ne l'actualisez pas, l'IA sera morte dans votre base de code après trois mois.
Cet ensemble de réflexions a plus de valeur que la compétence elle-même
Même si vous n'installez pas du tout /improve-codebase-architecture, rappelez-vous simplement les trois choses suivantes, et la qualité de l'examen des relations publiques sera améliorée d'un cran :
- test de suppression : Chaque fois que vous voyez un nouveau module, demandez-vous « Si vous le supprimez, la complexité disparaîtra-t-elle ou s'étendra-t-elle ?
- Vrai coutures au moins deux adaptateurs : interface d'implémentation unique = faux résumé, supprimer
- L'interface est la surface de test : ne peut pas être mesurée = il y a un problème avec la conception de l'interface
Ces trois éléments ne nécessitent ni IA ni compétences : ils constituent la monnaie forte de l’esthétique de l’ingénierie. Matt les intègre dans des compétences pour l'exécution par lots, mais le véritable levier réside dans les trois principes eux-mêmes.
Notes
N'allez pas trop loin. Ousterhout lui-même a déclaré que le module profond est un objectif plutôt qu'un dogme - une grande classe Util qui regroupe toutes les fonctions n'est pas un module profond, mais un module divin. Le critère de jugement est « une interface simple + une mise en œuvre cohérente », qui doivent tous deux être remplis.
l'approfondissement doit avoir une protection de test. Les changements structurels sont des opérations à haut risque, et oser refactoriser sans tester = attendre d'en prendre la responsabilité. S'il n'y a aucun test actuellement, rendez-vous sur /tdd pour ajouter des tests au chemin critique puis revenez.
Les décisions ADR ne doivent pas être prises sur un coup de tête. Lorsque vous rejetez un candidat lors de l'examen, l'IA vous proposera facilement de générer un ADR - en ne l'acceptant que si la raison est vraiment "les futurs gens doivent savoir". Sinon, docs/adr/ sera rempli d'entrées de journal.
Peu importe si une partie du code est superficielle. Un wrapper d'enregistreur, un fichier constant, un script unique - ils sont superficiels, pas de problème. Cette compétence recherche les modules superficiels qui prétendent vous aider avec l'abstraction mais qui ajoutent en réalité du chaos.
Ressources de référence
improve-codebase-architecture/SKILL.md
Full glossary, deletion test, candidate-presentation format, and grilling loop integration.
A Philosophy of Software Design
The book that defined deep modules. ~190 pages, the most cost-efficient software design book of the past decade.
Deep Modules: The Claude Code Skill Saving My Codebase
Third-party walkthrough of using improve-codebase-architecture on a real project. Concrete before/after numbers.
Conclusion de la série
J'ai lu les 6 articles jusqu'à présent. Passez en revue l'ensemble du flux de travail :
/grill-me 或 /grill-with-docs ← 谈清楚要做什么
↓
/to-prd ← 凝固成 PRD
↓
/to-issues ← 切成 vertical slice
↓
/tdd ← 一个 slice 一个 slice 跑红绿
↓
/improve-codebase-architecture ← 周期性深化
↓
回到 /grill-meL’esprit de ce processus peut être condensé en une phrase :
**L'IA est le soldat tactique sur le terrain et vous êtes la couche stratégique. Reprenez les trois choses de « définir le problème », « déconstruire le problème » et « tester le problème » et faites-le vous-même, et laissez « écrire du code » à l'IA - c'est la vraie position des ingénieurs à l'ère de l'IA. **
L'ensemble des compétences de Matt ne constitue pas la réponse ultime, mais la meilleure pratique à l'heure actuelle. Il y aura peut-être quelque chose de mieux trois mois plus tard, mais l'aspect spirituel ne changera pas : une bonne base de code est toujours plus importante qu'une mauvaise base de code, et les compétences logicielles de base sont toujours précieuses.
Revenez à Présentation, ou choisissez la compétence la plus utile et installez-la pour l'essayer.