TDD : utilisez le refactoring rouge-vert pour forcer l'IA à faire de petits pas
Matt Pocock se présente comme « le moyen le plus stable d'améliorer la qualité du travail des agents ». Une analyse détaillée des raisons pour lesquelles ses compétences TDD insistent sur une refactorisation rouge-vert verticale plutôt qu'horizontale, comment éviter le couplage entre les tests et la mise en œuvre, et la nouvelle signification du TDD à l'ère de l'IA.
The rate of feedback is your speed limit. Don't outrun your headlights.
Mode d'échec : "L'IA fait ce qu'il faut, mais elle ne peut pas fonctionner"
Le troisième mode d'échec dans le discours de Matt : La direction est la bonne, mais elle ne fonctionne pas.
La solution la plus directe consiste à installer une infrastructure de feedback pour l’IA :
- TypeScript (pas de typage statique c'est fou)
- Autoriser LLM à accéder au navigateur et à afficher la page par lui-même
- Tests automatisés
Mais Matt a observé une chose : Même avec ces commentaires installés, LLM ne fonctionne pas bien. Il a tendance à écrire 500 lignes à la fois, puis à penser "oh, je devrais taper, vérifier ça". C'est ce que le Pragmatic Programmer appelle dépasser vos phares : conduisez plus vite que les phares ne peuvent éclairer, et ce n'est qu'une question de temps avant de heurter le mur.
"The rate of feedback is your speed limit, which means you should be testing as you go, taking small deliberate steps. And the AI by default is really not very good at that."
Pour résoudre ce problème, vous devez forcer l'IA à s'arrêter étape par étape au niveau de l'outil. La réponse de Matt est TDD - Les tests en premier peuvent forcer les points de contrôle.
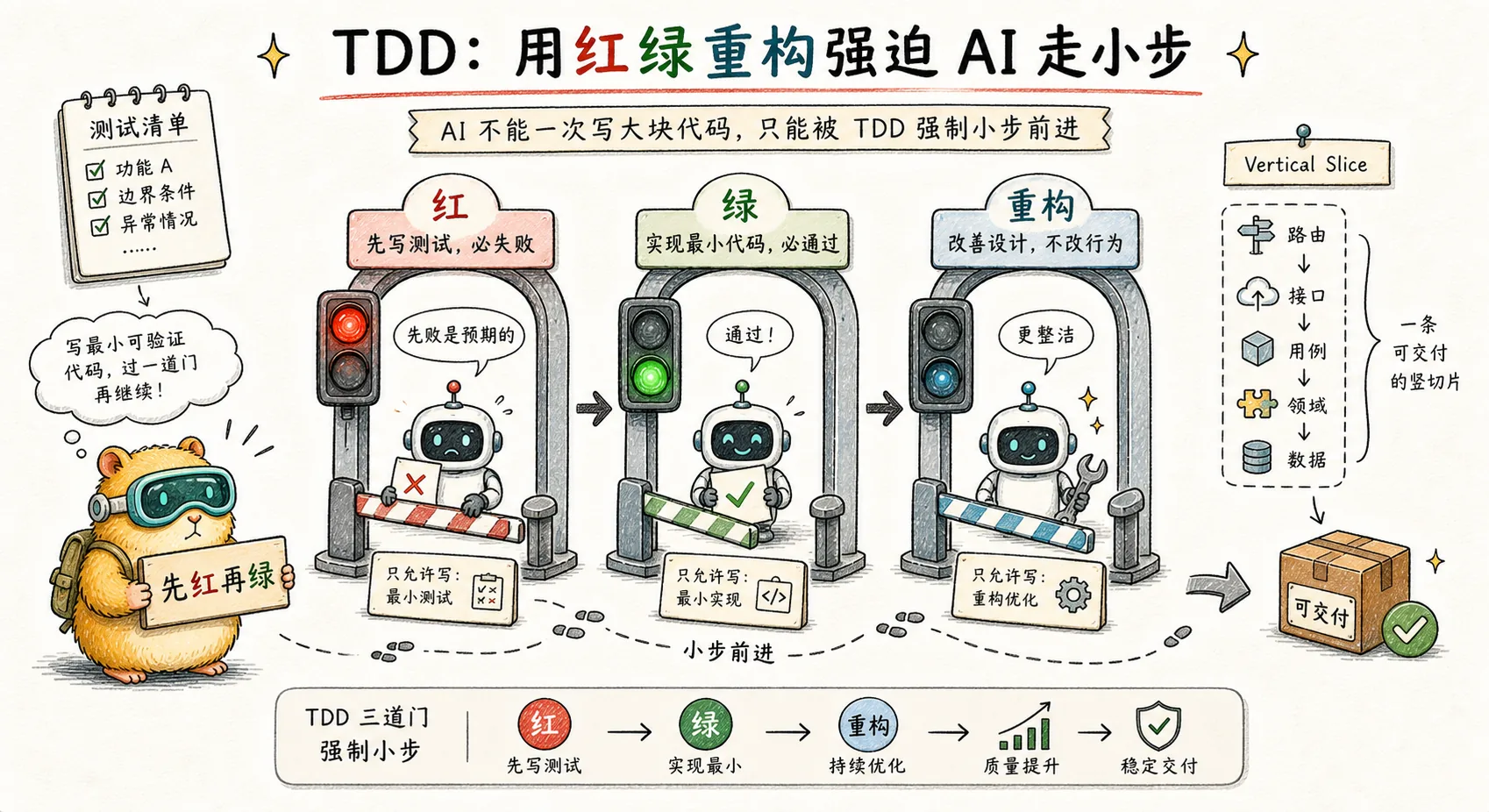
Théorie classique : la reconstruction rouge-vert de Kent Beck
Le rythme standard du TDD est défini par Kent Beck dans son livre de 2003 « Test-Driven Development : By Sample » :
- ROUGE : rédigez un test qui échoue (décrivez ce qu'il faut faire)
- VERT : écrivez le code le plus petit suffisamment pour que le test réussisse
- REFACTOR : Améliorer la structure du code sous protection de test
Chaque boucle est extrêmement courte – de l’ordre de quelques minutes. Il y a des contrôles automatisés (réussite/échec du test) à chaque étape.
Matt suit directement ce rythme, mais son SKILL.md passe beaucoup de temps à parler d'un anti-modèle - c'est le noyau.
Anti-motif clé : rouge et vert tranchés horizontalement
Beaucoup de gens pensent que TDD signifie « écrire d'abord tous les tests, puis écrire toutes les implémentations ». Matt dit directement que c'est faux dans SKILL.md :
WRONG (horizontal slicing):
RED: test1, test2, test3, test4, test5
GREEN: impl1, impl2, impl3, impl4, impl5
RIGHT (vertical slicing via tracer bullets):
RED→GREEN: test1→impl1
RED→GREEN: test2→impl2
RED→GREEN: test3→impl3
...Pourquoi l'horizontale est-elle fausse ? SKILL.md a donné trois raisons :
- Tests written in bulk test imagined behavior, not actual behavior
- You end up testing the shape of things (data structures, function signatures) rather than user-facing behavior
- Tests become insensitive to real changes - they pass when behavior breaks, fail when behavior is fine
Dicton humain : Écrire tous les tests en une seule fois, c'est tester ce qu'il y a dans votre tête, pas le vrai code. Lorsque vous écrivez impl3, vous réalisez que la conception de test1 est erronée - mais à l'heure actuelle, test2/test3/test4 sont tous couplés à une mauvaise conception. Revenez en arrière et apportez des modifications.
L'approche correcte consiste à tester une implémentation, puis à ouvrir la paire suivante après avoir écrit une paire. Une fois que chaque paire est terminée et que vous avez appris quelque chose de cette mise en œuvre, la paire de tests suivante peut être conçue sur la base d'une expérience réelle et non d'une imagination.
Structure du texte intégral de la compétence
engineering/tdd/SKILL.md est l'une des compétences les plus longues que Matt ait écrites car TDD lui-même comporte beaucoup de nuances. La structure de base est la suivante :
Philosophie
Core principle: Tests should verify behavior through public interfaces, not implementation details. Code can change entirely; tests shouldn't.
Good tests are integration-style: they exercise real code paths through public APIs. They describe what the system does, not how it does it. A good test reads like a specification.
Bad tests are coupled to implementation. They mock internal collaborators, test private methods, or verify through external means (like querying a database directly). The warning sign: your test breaks when you refactor, but behavior hasn't changed.
N'oubliez pas un diagnostic : Si vous renommez une fonction interne, le test s'agenouillera - alors ce test teste l'implémentation plutôt que le comportement, ce qui est un mauvais test.
Workflow (avec liste de contrôle)
1. Planning
Alignez-vous avec les utilisateurs avant d'écrire du code :
[ ] Confirm with user what interface changes are needed
[ ] Confirm with user which behaviors to test (prioritize)
[ ] Identify opportunities for deep modules (small interface, deep impl)
[ ] Design interfaces for testability
[ ] List the behaviors to test (not implementation steps)
[ ] Get user approval on the planQuestion clé : "À quoi devrait ressembler l'interface publique ? Quels comportements sont les plus importants à tester ?"
"You can't test everything. Confirm with the user exactly which behaviors matter most. Focus testing effort on critical paths and complex logic, not every possible edge case."
Celui-ci est très contre-intuitif. Par défaut, l'IA voudra épuiser tous les cas extrêmes, mais Matt met l'accent sur la priorité : tous les comportements ne valent pas la peine d'être mesurés et concentre la puissance de feu sur le chemin principal.
2. Tracer Bullet
Écrivez un test qui vérifie une chose :
RED: Write test for first behavior → test fails
GREEN: Write minimal code to pass → test passesIl s'agit d'une "balle traçante" - tirez dessus d'abord et vérifiez le viseur. Matt a souligné que ce travail devrait être de bout en bout - ne pas écrire d'abord le schéma, puis écrire l'API, puis écrire l'interface utilisateur, mais couper le chemin le plus fin qui traverse toute la pile.
3. Incremental Loop
Répétez l’opération pour chaque comportement suivant ROUGE → VERT :
RED: Write next test → fails
GREEN: Minimal code to pass → passesRègles :
- Un test à la fois
- Écrivez seulement assez de code pour réussir le test en cours
- Ne prédisez pas les futurs tests
- Les tests se concentrent sur les comportements observables
"Ne pas prédire" est particulièrement important. L'IA ne peut s'empêcher de penser : « Cette fonction doit de toute façon prendre en charge X, ajoutons-la en passant » - et cela démarre le découpage horizontal.
4. Refactor
Une fois tous les tests réussis, recherchez les opportunités de refactoring :
[ ] Extract duplication
[ ] Deepen modules (move complexity behind simple interfaces)
[ ] Apply SOLID principles where natural
[ ] Consider what new code reveals about existing code
[ ] Run tests after each refactor stepNever refactor while RED. Get to GREEN first.
Refactoring en rouge = changer les tests et le code en même temps = on ne sait pas si le test est faux ou si le code est faux. Vert d'abord, puis refactoriser.
Per-Cycle Checklist
À la fin de chaque cycle rouge et vert, Matt demande à l'IA de s'auto-vérifier :
[ ] Test describes behavior, not implementation
[ ] Test uses public interface only
[ ] Test would survive internal refactor
[ ] Code is minimal for this test
[ ] No speculative features addedCes cinq points sont utilisés pour identifier les mauvais tests et la sur-implémentation. L’auto-vérification de l’IA peut éviter les erreurs les plus courantes.
Utilisation réelle : du problème au PR
/tdd est la prochaine étape du flux de travail de Matt à partir de /to-issues. Étant donné un problème de tranche verticale, le processus est le suivant :
你: 实现 issue #43
↓
/tdd
↓
Claude 读 issue acceptance criteria
↓
Claude 探索代码库 → 找到 CONTEXT.md → 用项目术语
↓
Planning 阶段:
- 列出准备改的接口
- 列出准备测的行为(按优先级排序)
- 让你点头
↓
Tracer Bullet:
- RED: 写第一个测试(基于 acceptance criteria 第 1 条)
- 跑测试,确认 fail
- GREEN: 写最小实现
- 跑测试,确认 pass
↓
Incremental Loop:
- 每个 acceptance criteria 一个 RED→GREEN
↓
Refactor:
- 看 deep module 提取机会
- 每次重构后跑全套测试
↓
PRÀ chaque cycle rouge et vert, l'IA s'arrêtera et vous donnera un statut - "le test échoue"/"le test réussit, voici la différence". Ces pauses sont l'antidote contre les phares - l'IA n'a aucune chance de tracer mille lignes en une seule fois.
À propos de Mock : l'opinion bien arrêtée de Matt
SKILL.md mentionne spécifiquement les dangers des simulations - il fournit également un mocking.md distinct. Idées de base :
"Bad tests... mock internal collaborators."
Collaborateurs internes simulés = couplage 1:1 entre les tests et la mise en œuvre = l'équipe de test s'agenouille lors de la refactorisation. La préférence de Matt est les tests de style intégration - essayez d'utiliser une vraie base de données (en mémoire ou conteneurs de test), un vrai HTTP (MSW) et un vrai système de fichiers (tmp dir). Moquez-vous uniquement des limites très coûteuses ou instables (comme les appels à l'API OpenAI).
Ceci est contraire à la situation actuelle de nombreuses équipes : la plupart des bibliothèques de code regorgent de tests unitaires et il y a plus de simulations que de code réel. Matt a porté un jugement dans son discours : Bonne base de code = base de code facile à tester. Si vous devez vous moquer d'un tas de choses à tester, cela signifie qu'il y a un problème avec la structure du code, et que vous devez d'abord changer l'architecture (allez dans /improve-codebase-architecture).
La nouvelle importance du TDD à l'ère de l'IA
Lorsque Kent Beck a écrit ce livre il y a 23 ans, le principal avantage du TDD était que « les gens n'écrivaient pas de mauvais code ». À l’ère de l’IA, TDD a une signification supplémentaire :
C'est le seul « critère de réussite » que l'IA peut comprendre.
Matt a cité les paroles de sagesse de Karpathy plus tard dans son discours :
LLMs are exceptionally good at looping until they meet specific goals. Don't tell it what to do, give it success criteria and watch it go.
La meilleure forme de « critères de réussite » est le test : il est vérifiable par machine, binaire et ne peut être contesté. Donner à l'IA une suite de tests + "laisser passer" est dix fois plus fiable que de donner à l'IA une description des exigences + "veuillez implémenter".
Ainsi, /tdd n'est pas seulement un outil d'assurance qualité : c'est l'interface d'entrée de la boucle d'agent. Chaque cycle rouge et vert est une « entrée → action → feedback » complète. L'IA apprend la véritable situation de cette mise en œuvre dans le cycle, et le cycle suivant sera plus précis.
Comment installer et utiliser
npx skills@latest add mattpocock/skillsVérifiez tdd + setup-matt-pocock-skills.
Si vous utilisez principalement Codex maintenant, transférez le produit d'installation vers .agents/skills/ et écrivez le flux de travail au niveau du projet, testez les commandes et émettez les règles de suivi dans AGENTS.md. L'essence du /tdd de Matt est le cycle de refactorisation rouge-vert, non lié au Code Claude.
Méthode d'appel :
- Direct :
/tdd- laissez-le déduire ce qu'il faut mesurer à partir du contexte de conversation actuel - Récupérer le problème :
/tdd implement #43- il récupérera le problème puis l'ouvrira - Correction du bug :
/tdd reproduce this bug then fix it- Il écrira d'abord un test échoué pouvant reproduire le bug, puis le corrigera
Notes
Ne convient pas à toutes les tâches. Scripts ponctuels, code d'exploration du terrain de jeu, réglage fin de l'interface utilisateur - n'utilisez pas TDD, cela ralentira le rythme. Matt lui-même a déclaré que TDD convient au code qui « a une valeur durable et doit être maintenu ».
Préparez d'abord l'infrastructure de test. Si le projet n'a pas installé le framework de test (Vitest / Jest / Playwright, etc.), installez-le d'abord puis utilisez /tdd, sinon il l'installera d'abord pour vous, mais il y a beaucoup de questions à cette étape.
Ne le laissez pas ajouter automatiquement des tests e2e. e2e est lent et net, et le rythme TDD est au niveau des minutes. /tdd par défaut est test d'intégration plutôt que e2e, mais vous pouvez lui dire explicitement "unité + intégration uniquement, pas e2e".
La phase de reconstruction est la plus facile à échapper à tout contrôle. Une fois que l'IA a obtenu le statut VERT, elle refactorisera un tas de choses avec enthousiasme - la regardera et exécutera des tests après chaque refactorisation. Cette partie est une zone à haut risque de déviation de l’IA.
Ressources de référence
tdd/SKILL.md (源码)
Full TDD philosophy, horizontal-slice anti-pattern, complete workflow checklists, and per-cycle self-check.
Test-Driven Development: By Example
The original book that defined the red-green-refactor loop.
TDD with AI Coding(中文)
Companion piece exploring how TDD shifts meaning when AI writes the implementation.
Article suivant : Améliorer l'architecture de la base de code : reconstruire des modules superficiels en modules profonds - La maintenance périodique permet à l'IA de fonctionner dans votre base de code sur le long terme.
Commentaires
PRD et problèmes
La partie centrale du flux de travail de Matt Pocock - /to-prd transforme la conversation en PRD, et /to-issues découpe le PRD en problèmes découpés verticalement qui peuvent être collectés indépendamment. Interprétation approfondie du nouveau rôle des deux anciens concepts de « balle traçante » et de « tranche verticale » à l'ère de l'IA
Approfondir l'architecture du code
La dernière étape du flux de travail de Matt Pocock consiste à analyser périodiquement la base de code à la recherche d’« opportunités d’approfondissement ». Comprendre en profondeur la théorie des modules profonds de John Ousterhout, le test de suppression original de Matt et pourquoi cette compétence est particulièrement nécessaire à l'ère de l'IA.