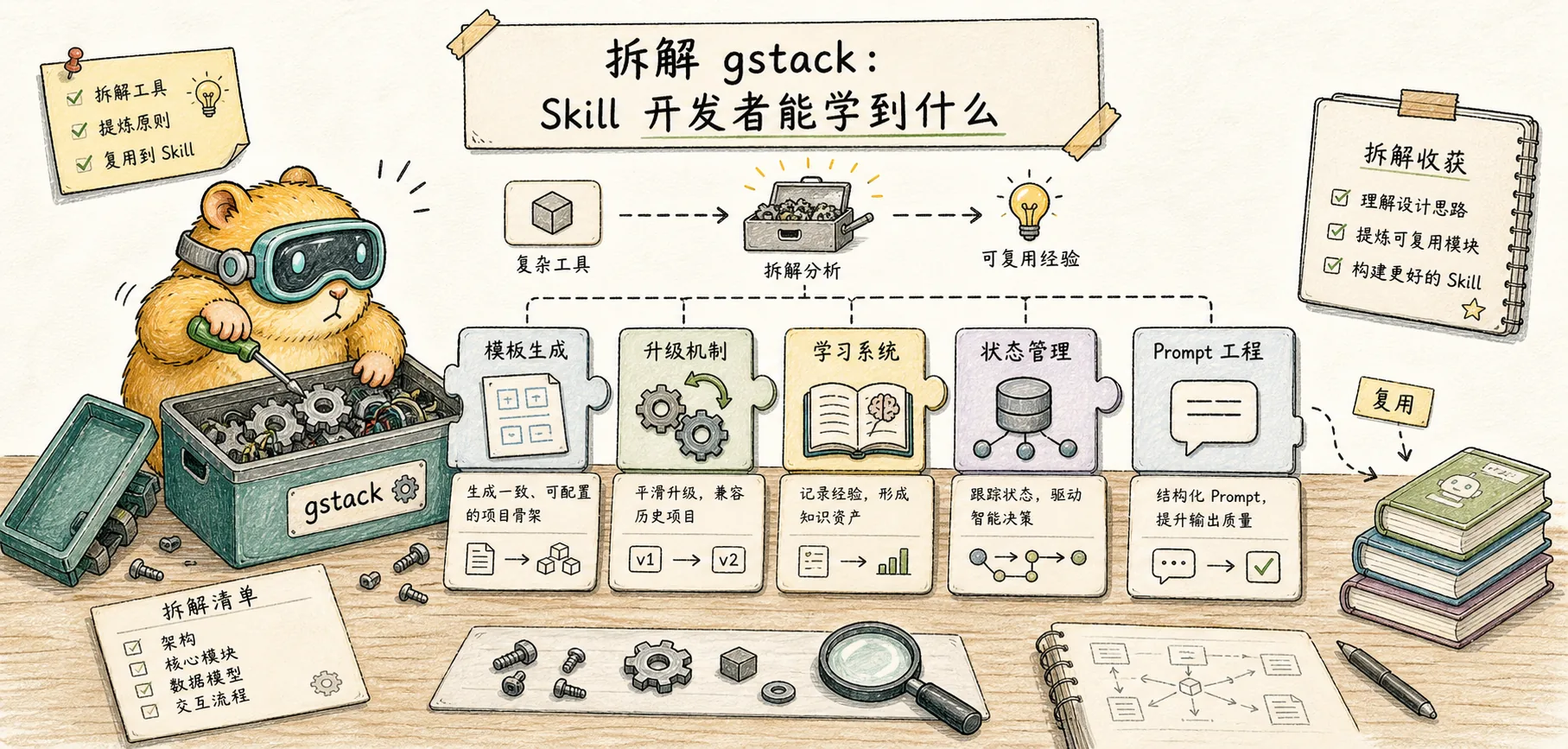
Gstack de démontage : ce que les développeurs de compétences peuvent apprendre
Démantèlement systématique de la conception technique de gstack du point de vue des développeurs de compétences : génération de modèles, mécanisme de mise à niveau, système d'apprentissage, injection de préambule, gestion des statuts, compétences d'ingénierie rapides
##Présentation
Dans Concept et Practical, nous avons appris ce qu'est gstack et comment l'utiliser du point de vue de l'utilisateur. Cette note est d'un point de vue différent - En tant que développeur de compétences, après avoir lu l'entrepôt gstack fichier par fichier, quelles conceptions techniques valent la peine d'être apprises et apprises.
gstack est plus qu'une simple collection de 23 fichiers d'invite. Il y a un système d'ingénierie complet derrière cela : génération de modèles, mise à niveau automatique, apprentissage et mémoire, guidage progressif, adaptation multiplateforme, tests en couches - telles sont les clés pour faire passer un projet de compétences de « utilisable » à « facile à utiliser ».
1. SKILL.md n'est pas manuscrit - système de génération de modèles
La conception la plus contre-intuitive de gstack : **Chaque SKILL.md est généré automatiquement et ne peut pas être modifié directement. **
SKILL.md.tmpl (人写) → gen-skill-docs → SKILL.md (机生)Le modèle .tmpl écrit par l'homme contient la logique de flux de travail et les meilleures pratiques, ainsi que des espaces réservés {{PLACEHOLDER}}. Le script de construction extrait la référence de la commande, la liste des indicateurs du navigateur, le code de démarrage du préambule, etc. du code source et les remplit dans les espaces réservés pour générer le SKILL.md final.
{{PREAMBLE}} ← 从 resolvers/preamble.ts 生成的启动代码
{{BROWSE_SETUP}} ← 浏览器初始化指令
{{COMMAND_REFERENCE}} ← 从 commands.ts 提取的命令文档
{{SNAPSHOT_FLAGS}} ← 从源代码常量提取的快照选项**Pourquoi faire ça ? **
- La documentation et le code ne seront jamais désynchronisés - la référence de commande est générée à partir du code source et la documentation est automatiquement mise à jour lorsque le code source change
- 23 compétences partagent le même préambule (environ 220 lignes), et toutes les compétences sont mises à jour simultanément
- CI peut
--dry-runvérifier si le fichier généré est expiré pour éviter d'oublier de régénérer
À retenir : Si vous gérez plusieurs compétences, tout contenu partagé entre les compétences doit être extrait dans des modèles et utilisé dans les étapes de création pour générer les fichiers finaux. La synchronisation manuelle de plusieurs copies du même contenu entraînera des problèmes tôt ou tard.
2. Mécanisme de mise à niveau - lien complet de la détection à l'exécution
Le système de mise à niveau de gstack est conçu de manière très raffinée et divisé en trois couches :
Première couche : détection de version
bin/gstack-update-check est un script bash autonome qui effectue les opérations suivantes :
- Lisez le fichier
VERSIONlocal - Vérifiez le cache
~/.gstack/last-update-check(UP_TO_DATE met en cache pendant 60 minutes, UPGRADE_AVAILABLE met en cache pendant 720 minutes) - Si le cache expire, requête HTTP
raw.githubusercontent.com/.../VERSIONde GitHub - Comparez le numéro de version et la sortie
UPGRADE_AVAILABLE <旧> <新>
Deuxième couche : intégration du préambule
La première ligne du code de démarrage SKILL.md de chaque compétence est la détection de version :
_UPD=$(~/.claude/skills/gstack/bin/gstack-update-check 2>/dev/null || true)
[ -n "$_UPD" ] && echo "$_UPD" || trueCela signifie que les mises à jour seront automatiquement détectées lorsque les utilisateurs appellent une compétence - pas besoin d'exécuter une commande de mise à niveau spécifiquement, aucune présence mais une couverture à 100 %.
Le troisième niveau : rappel progressif + mise à niveau automatique
Après avoir détecté une nouvelle version, celle-ci ne dérangera pas immédiatement l'utilisateur, mais utilisera le mécanisme de répétition (Snooze) pour un retour progressif :
- 1er Rappel : Merci de le mentionner à nouveau après 24 heures
- 2ème Rappel : Merci de le mentionner à nouveau après 48 heures
- 3ème fois et plus : merci de le mentionner à nouveau après 7 jours
- La nouvelle version réinitialise le compteur de répétition
Les utilisateurs peuvent gstack-config set auto_upgrade true activer la mise à niveau automatique et ignorer la confirmation pour l'exécuter directement.
Lors de la mise à niveau, 5 types d'installation (git global, git local, fournisseur, etc.) seront distingués. L'installation de git utilise git fetch + reset, l'installation fournie par le fournisseur sauvegarde d'abord puis remplace, et restaure à partir de .bak en cas d'échec. Après la mise à niveau, la copie du projet fournie par le fournisseur local sera également automatiquement synchronisée.
Points qui méritent d'être appris :
- Le mode "détecter à chaque appel" a une couverture extrêmement élevée et est imperceptible pour les utilisateurs
- L'arrêt progressif évite les interruptions fréquentes
- Différencier les types d'installation et mettre en œuvre différentes stratégies de mise à niveau au lieu d'une solution unique
- La sauvegarde et la restauration garantissent qu'un échec de mise à niveau n'entraînera pas le blocage de l'ensemble de la compétence.
3. Système d'apprentissage - Rendre les compétences plus intelligentes à mesure que vous les utilisez
gstack implémente un système de mémoire inter-session léger mais efficace.
Stockage
Chaque projet dispose d'un journal d'apprentissage indépendant : ~/.gstack/projects/$SLUG/learnings.jsonl, qui est rédigé en plus.
{
"skill": "review",
"type": "pitfall",
"key": "n-plus-one",
"insight": "这个项目的 User model 有 N+1 查询问题,findAll 要加 include",
"confidence": 8,
"source": "observed",
"files": ["src/models/user.ts"],
"ts": "2026-04-01T14:30:00Z"
}Collecte automatique
Avant que chaque compétence ne soit complétée, il existe un lien « d'auto-amélioration opérationnelle » - indiquant s'il y a eu des échecs inattendus, des détours ou des bizarreries du projet découverts pendant l'exécution, et tous seront automatiquement enregistrés dans learnings.jsonl. Aucun déclenchement manuel n’est requis par l’utilisateur.
Chargement automatique
Chaque fois qu'une nouvelle session démarre, le préambule chargera les 3 premières entrées d'apprentissage à haute confiance pour injecter du contexte, permettant à la nouvelle session d'hériter des connaissances historiques.
Dégradation de la confiance
Les entrées provenant des sources observed et inferred diminuent de 1 point tous les 30 jours. Il n’est pas nécessaire de nettoyer manuellement la base de connaissances : les connaissances obsolètes disparaissent naturellement et de nouvelles observations prennent naturellement leur place.
Interface de gestion
/learn # 显示最近 20 条
/learn search # 搜索
/learn prune # 检测过期条目(引用的文件已删除)
/learn export # 导出为 markdown 可加入 CLAUDE.mdPoints qui méritent d'être appris :
- La conception supplémentaire en écriture seule est simple et fiable, et la concurrence est sécurisée
- La dégradation de la confiance est une gestion du vieillissement des connaissances nécessitant peu d'entretien - beaucoup plus efficace que le nettoyage manuel
- Utilisez l'URL distante git au lieu du chemin pour identifier le projet (via
gstack-slug), qui peut être cloné à différents emplacements et réutilisé. - Prise en charge des requêtes inter-projets, mais isolées par défaut
4. Injection de préambule - "Couche middleware" de la compétence
C'est l'une des conceptions architecturales les plus intelligentes de gstack. Chaque SKILL.md partage un code de préambule d'environ 220 lignes, qui fonctionne comme le middleware d'un framework web :
┌─ 更新检测 ──────────────────────────────────┐
│ 会话追踪 (sessions/$PPID) │
│ 配置读取 (proactive, skill_prefix, telemetry)│
│ 学习历史加载 (前 3 条高置信度) │
│ 上下文恢复 (最近的 checkpoint + timeline) │
│ 路由规则检测 │
│ 首次使用引导流程 │
└──────────────────────────────────────────────┘
↓
Skill 特有逻辑Le script bash du préambule génère des paires clé-valeur (BRANCH: main, PROACTIVE: true), puis le modèle utilise des conditions de langage naturel pour permettre à Claude d'ajuster son comportement en conséquence :
If PROACTIVE is false, do not invoke skills automatically.
Instead suggest: "I think /skillname might help here -- want me to run it?"Il s'agit essentiellement de traiter la sortie bash comme les "variables d'environnement" de Claude - en utilisant bash pour la détection d'exécution et le langage naturel pour le routage comportemental.
Points qui méritent d'être appris : Si vous possédez plusieurs compétences, la logique partagée (chargement de la configuration, récupération d'état, détection de version) doit être extraite dans un préambule unifié au lieu d'écrire une copie pour chaque compétence.
5. Démarrage progressif - Mode fichier Sentinel
La première expérience utilisateur de gstack est conçue avec le plus grand soin. Assurez-vous que chaque étape de démarrage ne se produit qu'une seule fois via un fichier tactile (fichier sentinelle) :
~/.gstack/.completeness-intro-seen ← "Boil the Lake" 理念介绍
~/.gstack/.telemetry-prompted ← 遥测选择(community/anonymous/off)
~/.gstack/.proactive-prompted ← 主动触发开关
~/.gstack/.routing-prompted ← CLAUDE.md 路由规则写入
~/.gstack/.welcome-seen ← 安装欢迎消息Vérifiez si ces fichiers existent à chaque démarrage de la compétence. Sinon, affichez les fichiers de démarrage et tactiles correspondants. Les étapes déjà consultées n'apparaîtront plus jamais.
Points qui méritent d'être appris : Par rapport au maintien du statut de "onboarding_step": 3 dans la configuration, les fichiers sentinelles sont plus simples et plus fiables : ils ne seront pas affectés par la corruption du fichier de configuration et chaque étape est contrôlée indépendamment.
6. Conception structurelle SKILL.md - architecture à trois niveaux
Chaque SKILL.md suit une structure standard à trois couches :
Première couche : YAML Frontmatter
---
name: qa
preamble-tier: 3
version: 0.15.1.0
description: |
Systematically QA test a web application...
Use when asked to "qa", "test this site", "find bugs"...
benefits-from: [office-hours]
allowed-tools:
- Bash
- Read
- Write
hooks:
PreToolUse:
- matcher: "Bash"
hooks:
- type: command
command: "bash ${CLAUDE_SKILL_DIR}/bin/check-careful.sh"
---Champs clés :
allowed-tools: liste blanche d'autorisations au niveau des outils, chaque compétence déclare uniquement les outils dont elle a besoinbenefits-from: Déclarer explicitement la compétence de pré-dépendancehooks: hook PreToolUse, qui peut intercepter avant que l'outil ne soit appelé (comme une interception prudenterm -rf)description: contient tous les mots déclencheurs du langage naturel
Couche 2 : Préambule partagé + Règles générales
préambule code de démarrage + définition vocale + récupération de contexte + principe d'intégrité + priorité de recherche + protocole d'état d'achèvement + règles de mise à niveau, etc. Toutes les compétences sont identiques et générées à partir de modèles.
La troisième couche : la logique spécifique aux compétences
C'est « l'âme » de chaque compétence : définition du workflow, définition des rôles, injection de modèle cognitif, déclenchement des interactions, etc.
Points qui méritent d'être appris : La séparation en trois niveaux permet à chaque compétence de se concentrer uniquement sur sa propre logique unique, et les parties partagées sont assurées par le cadre de cohérence.
7. Collection de conseils d'ingénierie rapides
Après avoir lu tout SKILL.md, voici les techniques de conception rapide qui valent la peine d'être apprises :
Règles anti-flatterie
Le mode de démarrage des heures de bureau interdit explicitement le comportement « et boueux » courant de l’IA :
Never say:
- "That's an interesting approach" → take a position instead
- "There are many ways to think about this" → pick one
- "You might want to consider..." → say "This is wrong because..."
- "That could work" → say whether it WILL workListe de mots interdits
La section Voix contient des mots et des phrases clairement interdits :
- Mots interdits : fouiller, crucial, robuste, complet, nuancé, pivot, paysage...
- Phrases interdites : "voici le kicker", "plot twist", "laisse-moi décomposer ça"...
- Format désactivé : em tiret (remplacer par virgule/point)
Ce sont des mots courants « à saveur d'IA » dans LLM, et le résultat est évidemment plus naturel après avoir été désactivé.
Injection de modèles cognitifs
Chaque compétence de révision injecte un cadre de réflexion différent :
- CEO Review : 18 modèles cognitifs (prise de décision à sens unique/bidirectionnel de Bezos, pensée inversée de Munger, concentration et soustraction de Jobs...)
- Eng Review : 15 modèles de gestion d'ingénierie ("ennuyeux par défaut", intuition du rayon de souffle, loi de Conway...)
- Design Review : 12 modèles cognitifs de conception (hiérarchie en tant que service, culte des contraintes, tests "Est-ce que je le remarquerais ?"...)
Ces modes ne permettent pas à l'IA de fonctionner de manière mécanique, mais lui fournissent un cadre de réflexion - tout comme donner à un nouveau venu intelligent une liste d'expériences de ses prédécesseurs.
Normes de spécification
Not "you should test this"
but `bun test test/billing.test.ts`
Not "this might be slow"
but "this queries N+1, ~200ms per page load with 50 items"
Not "there's an issue in the auth flow"
but "auth.ts:47, the token check returns undefined"Calibrage de confiance
La compétence de révision nécessite que chaque découverte soit accompagnée d'un score de confiance, et les résultats peu fiables sont automatiquement déclassés ou masqués :
| Score | Signification | Traitement |
|---|---|---|
| 9-10 | Lisez le code spécifique et vérifiez | Affichage normal |
| 7-8 | Correspondance de modèles de confiance élevée | Affichage normal |
| 5-6 | Fausse alerte modérée, possible | Affichage avec instructions |
| 3-4 | Faible confiance | Masquer des rapports |
| 1-2 | Pure supposition | Affiché uniquement au niveau P0 |
Portail interactif
La compétence du navire définit précisément quand s'arrêter et attendre l'utilisateur et quand continuer automatiquement :
Only stop for:
- Tests failing with no obvious fix
- Merge conflicts requiring human judgment
- Unclear which changes to include
Never stop for:
- Normal git operations
- CHANGELOG/VERSION updates
- PR creationPoints qui méritent d'être appris : Une bonne compétence n'est pas « L'IA fait tout », mais une définition précise de la frontière homme-machine.
8. Gestion de l'état - le système de fichiers est une base de données
Toute persistance de gstack se fait via le système de fichiers, stocké sous ~/.gstack/ :
| Chemin | Objectif | Formater |
|---|---|---|
config.yaml | Configuration globale | YAML |
sessions/$PPID | séance active | fichier tactile |
projects/$SLUG/learnings.jsonl | Dossier d'apprentissage | JSONL |
projects/$SLUG/timeline.jsonl | Chronologie des compétences | JSONL |
projects/$SLUG/checkpoints/*.md | Point de contrôle | Démarquage |
projects/$SLUG/health-history.jsonl | Historique du bilan de santé | JSONL |
analytics/skill-usage.jsonl | Utiliser la télémétrie | JSONL |
last-update-check | cache des versions | texte brut |
Presque toutes les données de séries chronologiques sont écrites en annexe à l'aide de JSONL (un objet JSON par ligne). Ce choix est intelligent :
- Ajout de la sécurité de la concurrence naturelle en écriture
- Aucune dépendance de base de données requise
- Vous pouvez utiliser
grep/jqpour interroger directement - Corrompu jusqu'à la dernière ligne manquante
9. Mode d'intégration multi-compétences
Produit de transfert de fichiers
Transférer les produits du travail entre les compétences via le système de fichiers :
/office-hours → design doc → /plan-ceo-review 读取
/plan-ceo-review → ceo-plans/*.md → /autoplan 读取
/review → reviews.jsonl → /ship 读取并展示 Dashboard
/qa → qa-reports/ → /retro 读取Review Readiness Dashboard
La compétence du navire indique reviews.jsonl, affichant l'état de révision des compétences croisées avant la publication :
| Review | Runs | Last Run | Status | Required |
| Eng Review | 1 | 2026-03-16 | CLEAR | YES |
| CEO Review | 0 | — | — | no |
| Design Review | 0 | — | — | no |Suggestions de pré-dépendance
Lorsque plan-ceo-review détecte qu'il n'y a pas de document de conception, il recommande activement d'exécuter /office-hours en premier :
"No design doc found. /office-hours produces a structured problem statement...
Takes about 10 minutes."
Options: A) Run /office-hours now B) SkipUtiliser la prédiction de séquence
Context Recovery analysera la séquence récente d'utilisation des compétences et prédira la prochaine étape :
If pattern repeats (e.g., review → ship → review),
suggest: "Based on your recent pattern, you probably want /ship."10. Autres designs remarquables
Système de crochet
Les trois compétences Attention, Gel et Garde utilisent des crochets PreToolUse - c'est le seul mécanisme qui peut intercepter avant que l'outil ne soit appelé :
- attention : interceptez Bash, vérifiez
rm -rf,DROP TABLE,git push --force - freeze : intercepte Edit/Write et vérifie si le chemin est dans la plage autorisée
- garde : combinez les deux ci-dessus
Adaptation multiplateforme
Le même ensemble de modèles génère des fichiers de compétences pour différentes plates-formes via le paramètre --host :
bun run gen:skill-docs --host claude # Claude Code 格式
bun run gen:skill-docs --host codex # OpenAI Codex 格式
bun run gen:skill-docs --host kiro # AWS Kiro 格式
bun run gen:skill-docs --host factory # Factory Droid 格式Le chemin et le sujet sont automatiquement adaptés et la logique des compétences reste inchangée.
Protocole d'état d'achèvement
Un état d'achèvement standardisé doit être affiché à la fin de chaque compétence :
DONE — 全部完成,提供证据
DONE_WITH_CONCERNS — 完成但有顾虑
BLOCKED — 无法继续
NEEDS_CONTEXT — 需要更多信息Trois règles de mise à niveau ayant échoué
If you have attempted a task 3 times without success, STOP and escalate.Empêchez l’IA de rester bloquée dans une boucle de tentatives infinies.
Sélection de tests basée sur les différences
Les tests E2E coûtent environ 4 $ chacun (nécessite le démarrage de l'agent Claude), donc gstack déclare les fichiers sources dont dépend chaque test via touchfiles.ts et exécute uniquement les tests concernés selon git diff :
// test/helpers/touchfiles.ts
{
"qa-workflow": ["qa/SKILL.md.tmpl", "browse/src/server.ts"],
"ship-flow": ["ship/SKILL.md.tmpl", "scripts/resolvers/preamble.ts"]
}Résumé : Des principes de conception que vous pouvez retenir
De la pratique d'ingénierie de gstack, j'ai extrait les principes de conception suivants qui sont les plus précieux pour les développeurs de compétences :
- Génération de modèles > Synchronisation manuelle : le contenu partagé entre les compétences est automatiquement généré à l'aide de modèles + étapes de construction, ne copiez pas et ne collez pas
- Détection passive > Détection active : La détection de mise à niveau est intégrée à chaque appel de compétence, l'utilisateur l'ignore mais le taux de couverture est de 100 %
- Ajouter le journal > Base de données complexe : JSONL + système de fichiers peut couvrir la plupart des besoins de persistance, simple et fiable
- Démarrage progressif > Une configuration : utilisez des fichiers sentinelles pour contrôler les étapes de démarrage, chacune n'apparaissant qu'une seule fois.
- Gating précis > Entièrement automatique : définissez clairement les limites entre « arrêter et attendre l'utilisateur » et « continuer automatiquement »
- Quantification de la confiance > Jugement flou : chaque jugement de l'IA est accompagné d'un score de confiance, et une faible confiance est automatiquement dégradée.
- Time Decay > Manual Cleaning : La confiance dans les enregistrements d'apprentissage diminue avec le temps et les connaissances obsolètes s'estompent naturellement.
- LISTE DE MOTS INTERDITS > GUIDE DE STYLE : Une liste directe de mots interdits est bien plus efficace que « veuillez utiliser un ton naturel »
gstack - Claude Code Skills
23+ opinionated skills that transform Claude Code from a single AI assistant into a virtual engineering team.
Lecture connexe :
- gstack Concepts — Qu'est-ce que gstack et quels problèmes résout-il ?
- Gstack Practical Chapter — Workflow complet de l'installation à l'exécution
- gstack Front-end Skill — Panorama des compétences de conception Front-end/UI et workflow recommandé
- Claude Skills Concept — Comprendre le mécanisme sous-jacent des compétences
Commentaires
chapitre pratique de gstack
Configuration de l'installation de gstack, référence complète des commandes, démonstration du flux de travail et meilleures pratiques de la communauté
compétences frontales de Gstack
Examen du système de plus de 25 compétences liées au front-end/UI dans gstack, flux de travail de développement recommandé et propositions de tests réelles