frankbria/ralph-claude-code Practical Guide
An engineered Ralph loop implementation: interactive setup, real-time monitoring, circuit breakers, and safety mechanisms
Introduction
The previous article introduced Ralph's methodology, and snarktank/ralph demonstrated a minimalist outer loop implementation. Now let's look at another approach: frankbria/ralph-claude-code.
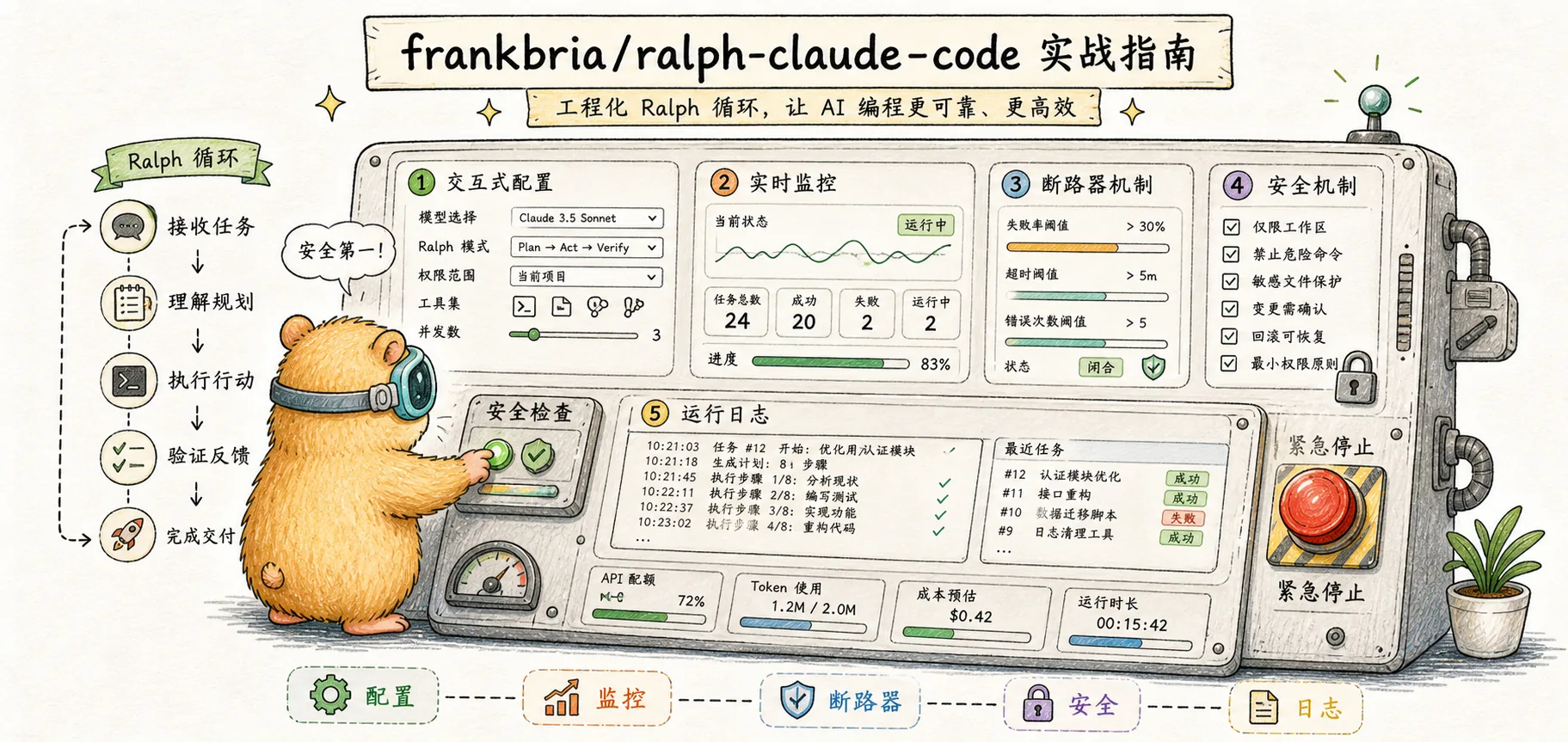
If snarktank/ralph's philosophy is "do the most with the least code," then frankbria's philosophy is "engineer everything" — interactive configuration wizards, real-time monitoring dashboards, circuit breakers, rate limiting, and session expiration management. It doesn't pursue simplicity; it pursues controllability.
Neither implementation is inherently better — they suit different use cases. This article walks you through frankbria's complete toolchain.
Installation and Configuration
Global Installation
# Clone the repository
git clone https://github.com/frankbria/ralph-claude-code.git
cd ralph-claude-code
# Global install
./install.shAfter installation, you'll have the following global commands:
| Command | Description |
|---|---|
ralph | Start the Ralph loop |
ralph-enable | Enable Ralph in an existing project |
ralph-setup | Create a new project and configure Ralph |
ralph-import | Import an existing PRD/requirements document |
ralph-monitor | Launch the real-time monitoring dashboard |
Project Initialization
For existing projects, use the interactive wizard:
cd your-project
ralph-enableThe wizard automatically detects the project type (Node.js, Python, Go, etc.) and framework (Next.js, FastAPI, etc.), then generates the corresponding configuration files.
For brand-new projects:
ralph-setup my-new-projectThis creates the project directory, initializes Git, and generates the .ralph/ configuration directory.
Importing Existing Requirements
If you already have a PRD document or requirements specification:
ralph-import path/to/your-prd.mdRalph will parse the document, extract the task list, and generate a structured fix_plan.md.
.ralph/ Directory Structure
frankbria's memory and configuration are centralized in the .ralph/ directory:
.ralph/
├── PROMPT.md # Project goals and context
├── fix_plan.md # Task checklist (similar role to prd.json)
├── AGENT.md # Build/test commands (auto-maintained)
├── specs/ # Detailed requirement documents
│ ├── feature-a.md
│ └── feature-b.md
└── sessions/ # Session persistence data
├── current.json
└── history/Comparison with snarktank/ralph:
| frankbria | snarktank | Purpose |
|---|---|---|
PROMPT.md | prd.json's projectName + description | Define project goals |
fix_plan.md | prd.json's userStories | Task list and progress |
AGENT.md | CLAUDE.md / AGENTS.md | Build commands and project conventions |
specs/ | prd.json's notes field | Detailed requirements |
sessions/ | None (new process each time) | Session state tracking |
Note that AGENT.md is auto-maintained — Ralph automatically updates this file based on project conventions discovered during execution, similar to snarktank/ralph's progress.txt, but more structured.
Core Commands
Basic Execution
# Start the Ralph loop
ralph
# With real-time monitoring
ralph --monitor
# Run in tmux (recommended for long-running tasks)
ralph --liveMonitoring Dashboard
# Launch monitoring independently
ralph-monitorralph-monitor opens a tmux dashboard that displays in real time:
- The currently executing task
- Completed/remaining task counts
- API call counts and cost estimates
- Circuit breaker status
- Recent error logs
Common Parameters
| Parameter | Description | Default |
|---|---|---|
--resume | Continue from where you left off | - |
--calls <n> | Maximum API call count | 100 |
--timeout <min> | Timeout in minutes | 300 |
--monitor | Enable real-time monitoring | false |
--live | Run in tmux | false |
# Limit to 50 API calls with a 2-hour timeout
ralph --calls 50 --timeout 120
# Resume from where you left off
ralph --resumeSafety Mechanisms
frankbria's biggest differentiator is its multi-layered safety mechanisms.
Circuit Breaker
The circuit breaker automatically stops the loop when it detects "no progress," preventing wasteful API consumption:
Consecutive no-progress detection: If N consecutive iterations complete without any new task being finished, the circuit breaker triggers.
Repeated error detection: If the same error message appears consecutively, it indicates the AI is stuck in a loop, and the circuit breaker triggers.
Rate Limiting
The default limit is 100 calls/hour, preventing unexpected API billing spikes. You can adjust this via parameters:
ralph --calls 200 # Increase to 200 calls5-Hour API Quota Three-Layer Detection
The Anthropic API has a 5-hour sliding window usage quota. frankbria includes three layers of detection:
- Pre-check: Estimates remaining quota before each API call
- Response detection: Parses rate limit headers from API responses
- Fallback strategy: Automatically reduces call frequency when approaching the limit
Session Expiration Management
The default session validity is 24 hours. After that, session data is automatically cleaned up to prevent stale context from affecting subsequent executions.
Intelligent Exit Detection
frankbria doesn't simply exit when all tasks are complete. It uses a dual-condition exit gate:
Exit condition = completion_indicators >= 2 AND EXIT_SIGNAL: truecompletion_indicators is the number of completion signals detected from AI output, including:
- "All tasks completed"
- "No more pending items"
- All tests passing
- All entries in fix_plan.md marked as done
EXIT_SIGNAL is an explicit exit intent declared by the AI in its output.
Why two conditions? To prevent premature exits. A single signal could be a false positive — for example, the AI might say "task complete" when it has only finished the current story. The dual condition ensures the loop only truly exits when multiple independent signals confirm completion.
Comparison with snarktank/ralph
| Dimension | snarktank/ralph | frankbria/ralph-claude-code |
|---|---|---|
| Implementation | External bash loop (new session each time) | External bash loop (--continue reuses session) |
| Session mode | Fresh each time | Reuse by default (switch to fresh via --no-continue) |
| Context | Fresh each time | Accumulated across iterations via --continue |
| Installation | Skill copy | install.sh + interactive wizard |
| Task format | prd.json | PROMPT.md + fix_plan.md |
| Monitoring | Manual cat/jq | Built-in tmux dashboard |
| Safety mechanisms | max_iterations | Circuit breaker + rate limiting + timeout |
| Task sources | PRD only | beads / GitHub Issues / PRD |
| Best suited for | Long AFK sessions, many iterations | Short-to-medium iterations, monitoring needed |
Core Difference: Level of Engineering
Both are external bash loops launching new Claude processes. The core difference isn't in session management (frankbria can switch to fresh session mode via --no-continue), but in the level of engineering:
- snarktank: Minimalist script, a few hundred lines of bash, focused on the loop itself
- frankbria: Full-engineered toolchain — monitoring dashboard, circuit breaker, rate limiting, session expiration management
frankbria enables --continue by default to reuse sessions, which suits short tasks. For long tasks, you can switch to --no-continue mode to get the same Context Rot protection as snarktank, while retaining frankbria's engineering advantages.
How to Disable Session Reuse
frankbria offers three ways to disable --continue:
# Method 1: Command-line argument
ralph --no-continue
# Method 2: Environment variable
export CLAUDE_USE_CONTINUE=false
# Method 3: .ralphrc configuration
SESSION_CONTINUITY=falseOnce disabled, frankbria behaves like snarktank (fresh session each time), but retains all engineering tools (monitoring, circuit breaker, rate limiting, etc.).
The Real-World Trade-off of Context Rot
The choice of session reuse strategy is fundamentally a trade-off between Context Rot and startup overhead:
Short tasks (< 50k tokens): Session reuse has the advantage. Context hasn't had time to degrade, and memory from earlier iterations can still benefit subsequent ones. The startup overhead of creating a new session each time is actually wasteful.
Long tasks (100k+ tokens): Fresh sessions are more reliable. Beyond 100k tokens, Context Rot intensifies significantly — accumulated context turns from an asset into a liability. Fresh sessions have startup overhead, but each one starts in optimal condition.
Practical recommendations:
| Scenario | Recommendation | Reason |
|---|---|---|
| Fewer than 5 small tasks | frankbria (default mode) | Fast startup, reusable context |
| 10+ tasks, need to go AFK | snarktank or frankbria + --no-continue | Avoids Context Rot, more reliable |
| Need real-time monitoring | frankbria | Built-in dashboard |
| Uncertain task volume | frankbria + --no-continue | Engineering tools + Context Rot protection |
frankbria users can choose flexibly based on task scale: use the default --continue mode for short tasks, and switch to --no-continue mode for long tasks. Compared to snarktank, frankbria's advantage is that the complete engineering toolchain is retained regardless of which mode is used.
Summary
frankbria/ralph-claude-code represents the engineered implementation path of the Ralph methodology. It trades some of snarktank's simplicity for more comprehensive monitoring, safety, and configuration capabilities.
Which implementation you choose depends on your specific needs — there's no "more correct" answer, only a "better fit."
Further reading:
- Ralph Wiggum Deep Dive — Core principles and methodology
- snarktank/ralph Practical Guide — Minimalist outer loop implementation
- GSD Deep Dive — A complete context engineering system built on Ralph
- Claude System Architecture Guide — Understanding the overall architecture of Hooks, Subagents, and other components