What exactly is a self-improving agent improving?
From Reflexion, Voyager, ADAS, AFlow, DGM, SEAL to AlphaEvolve, we map out the technical landscape, key papers, engineering practices, and risk boundaries of self-improving agents.
If you want to systematically understand self-improving agents today, I believe the real need isn't to chase a vague term, but to clarify four things:
- What exactly is it "self-improving"?
- Does this improvement happen during inference, between tasks, or during retraining?
- How does it determine that it has actually improved?
- Which directions are already viable for deployment, and which are still research prototypes?
I'll start with the conclusion: today's self-improving agents are not the sci-fi vision of "models awakening and recursively upgrading indefinitely." A more accurate description is: an agent system that transforms its failures, trajectories, feedback, and evaluation results into a closed loop for better behavior in the next round.
This closed loop can be lightweight or heavy.
Lightweight examples include Reflexion and Self-Refine: they don't change model parameters, but instead write reflections into the context or memory. Heavyweight examples include SEAL: the model generates its own training data and update instructions, truly modifying weights. In between is the most noteworthy layer today: modifying prompts, tools, workflows, and code, then verifying with executable evaluations.
So, the most important part of a self-improving agent is not "self," but "improving." Without evaluation, regression, or controlled experiments, it's just the model repeatedly explaining why it performed well.
First, a definition: It's not one thing
Many articles conflate self-improving, self-evolving, self-adapting, and recursive self-improvement. This makes the problem very abstract.
I prefer to break it down into an engineering problem:
After completing a task, can an agent use feedback to modify one of its components and consistently improve in subsequent tasks?
There are three keywords here.
First, feedback. Feedback can come from tests, compilers, environmental rewards, human comments, LLM-as-judge, production logs, or even the agent's own reflection on failed trajectories.
Second, object of modification. It can modify context, memory, prompts, tool descriptions, workflows, code, training data, reward models, or even model weights.
Third, consistent improvement. This is the hardest part. Improving on a single task is not enough; it must be proven that it's not overfitting, not accidental, not a massive cost increase, and not compromising safety boundaries.
You can use this table to build a mental model:
| Object of Improvement | Typical Form | Advantages | Biggest Risk |
|---|---|---|---|
| Context | Reflection, experience, few-shot examples | Easiest to implement, no training needed | Memory pollution, context bloat |
| Prompt | Automatic instruction search, example generation | Low cost, suitable for production systems | Overfitting to evaluation, difficult to explain transferability |
| Tools and Workflow | Automatic design of agent processes, tool call order | Directly impacts agent capability ceiling | Large search space, difficult regression |
| Code | Agent modifies its own tools, scaffolding, execution logic | Closest to "modifying itself" | Running untrusted code, high security requirements |
| Training Data | Self-generated data, self-evaluated rewards | Can accumulate into model capability | Data collapse, reward hacking |
| Model Weights | SFT, DPO, RL, test-time update | May lead to lasting capability improvements | Forgetting, cost, online safety and rollback |
This is also why I don't recommend simply understanding a self-improving agent as "a model that gets smarter with use." What's truly debatable is: which layer is it modifying, where does the feedback come from, and how is the modification verified?
Phase One: Reflection, no weight changes
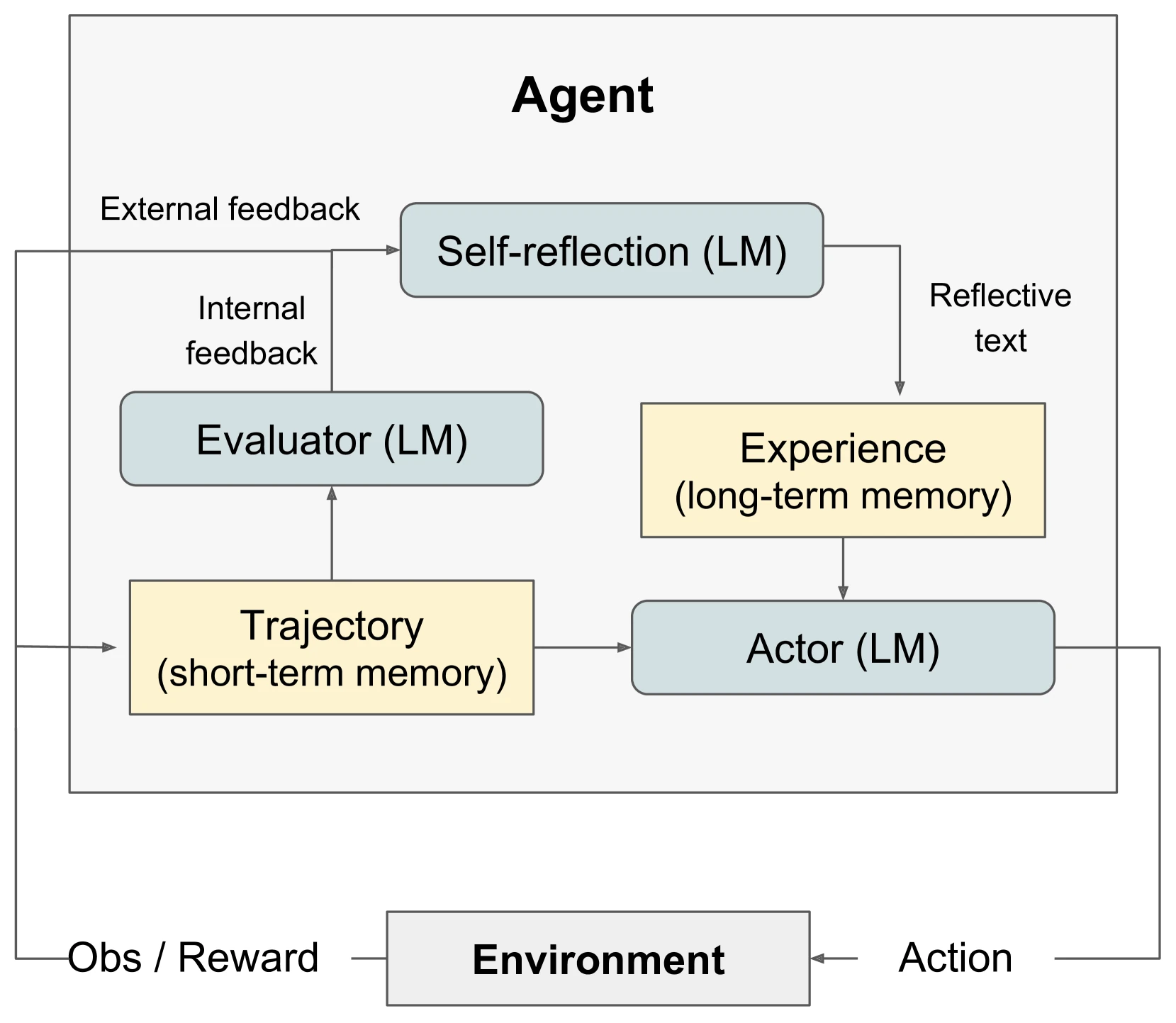
The most representative early approach was to have the model write down reflections after failure and then incorporate those reflections back into the context.
The core idea of Reflexion is that the agent doesn't learn through gradient updates, but instead converts task feedback into linguistic reflections, stores them in episodic memory, and utilizes them when encountering similar tasks again. Its significance isn't a specific benchmark score, but rather transforming "trial-and-error learning" from traditional RL's parameter updates into linguistic memory that the agent can immediately use.
Self-Refine is even more direct: the model first generates an answer, then provides feedback on its own answer, and then revises based on that feedback. This pattern has now become a fundamental module in many agent frameworks: do, review, then revise.
STaR, on the other hand, takes the training data route: the model first generates reasoning processes, filters out incorrect answers, retains rationales that lead to correct answers, and then uses these rationales to train the model. It's not a complete agent, but it provided a key insight for many subsequent self-improvement methods: models can distill training signals from their own successful trajectories.
The advantage of these methods is simplicity; the disadvantage is also clear: reflection does not equal improvement. Models are good at writing seemingly reasonable post-mortems, but without external validation, they might just become better at explaining their own mistakes.
So the boundaries of reflective agents are clear: they are suitable for short-term behavioral correction, not for proving long-term capability growth.
Phase Two: Turning experience into a skill library
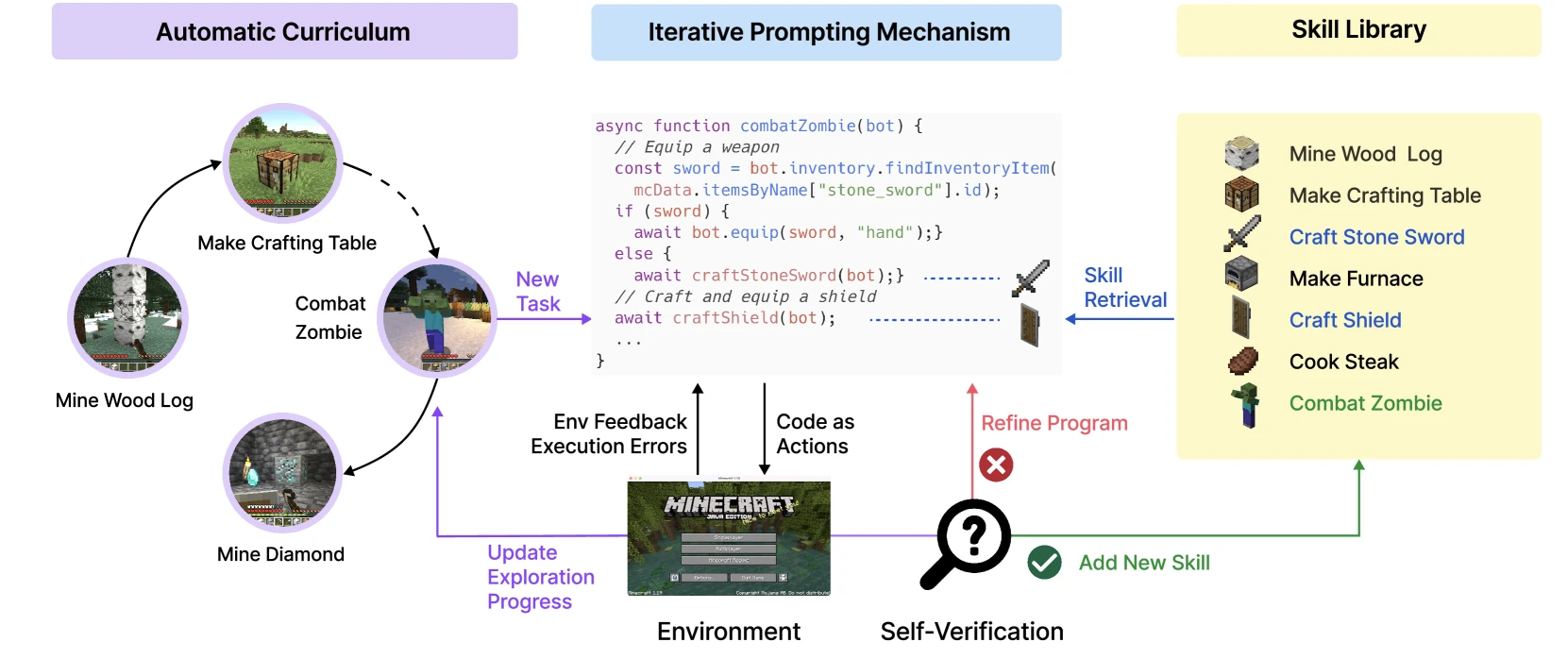
Voyager is a paper I believe is a must-read. It advanced self-improving agents from "answer rewriting" to "skill accumulation."
Voyager does three things in the Minecraft environment:
- Automatically generates an exploration curriculum.
- Saves successful behaviors as executable code skills.
- Iteratively improves programs based on environmental feedback, execution errors, and self-verification.
The most important aspect here isn't Minecraft, but the "skill library" structure. It allows the agent's improvements to not just be a longer prompt for the next turn, but to be solidified into retrievable, composable, and reusable programmatic assets.
This is very insightful for real products. Many teams talk about building self-evolving agents, but the actual first step shouldn't be training a model. Instead, it should be organizing the agent's trajectory after each task completion into three types of assets:
| Asset | Example | Reuse Method |
|---|---|---|
| Successful Path | Stable steps for a certain type of problem | As a workflow template |
| Lessons from Failure | Which tool sequences lead to errors | As a guardrail or counterexample |
| Executable Skill | Script, function, command, operation instruction | Into the tool library or skill library |
In other words, a practical self-improving agent should first act like an engineer who keeps a work log, rather than a model that secretly trains itself every night.
Phase Three: Automatically optimizing prompts and workflows
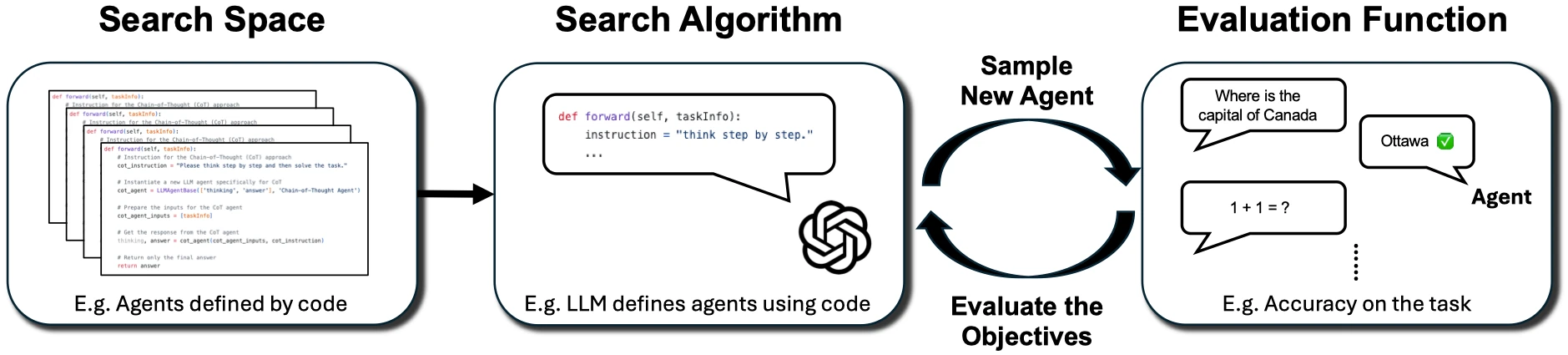
By 2024-2025, a significant change emerged: people started to be dissatisfied with agents merely "reflecting," and instead began to have agents automatically design agents.
OPRO uses an LLM as an optimizer, allowing the model to propose the next batch of candidates based on historical candidate solutions and scores. This idea was later adopted by many prompt optimizers: instead of manually tuning prompts, define tasks, datasets, and metrics, and let the system search for better instructions.
DSPy's MIPROv2 and GEPA make this more engineering-focused. GEPA, in particular, emphasizes not just looking at a scalar score, but having the model read the complete execution trace, diagnose failure reasons in natural language, and then evolve the prompt. This direction is well-suited for real agents, because agent failures are often not as simple as "the final answer was wrong," but rather incorrect tool selection, retrieval errors, routing errors, formatting errors, or incorrect intermediate states.
Further along this path are ADAS and AFlow.
ADAS proposes Automated Design of Agentic Systems: a meta-agent invents new agent designs in code space, including prompts, tool usage, control flow, and combination methods. AFlow, on the other hand, represents agent workflows as nodes and edges in code, using search methods to automatically modify and evaluate workflows.
The key to this direction is not "whether the model can write beautiful prompts," but rather: the agent's structure itself becomes a searchable, evaluable, and iterative object.
This is very important for engineering practice. Because the bottleneck of real agents is often not in a single response, but in the system structure:
- Should it retrieve first, then plan?
- If a tool fails, should it retry, switch tools, or ask the user?
- Should multiple agents collaborate serially, or be coordinated by a single coordinator?
- Which information should go into short-term context, and which into long-term memory?
- When to stop, and when to continue exploring?
In the past, these questions were designed by humans. Research into self-improving agents is turning these questions into search problems.
Phase Four: Modifying its own code
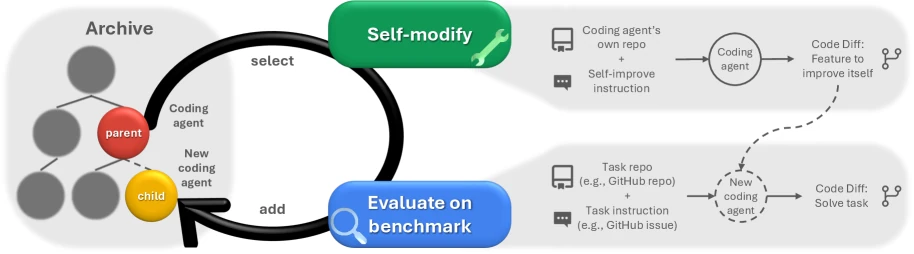
If ADAS is about meta-agents designing agents, then A Self-Improving Coding Agent and Darwin Godel Machine are closer to the literal meaning of "agent modifying itself."
Darwin Godel Machine:开放式演化的自改进 Agent
一个会迭代修改自身代码,并用 SWE-bench、Polyglot 等编程基准验证改进的自改进 coding agent。
A Self-Improving Coding Agent demonstrates how a coding agent can edit its own implementation and achieve improvements on tasks like SWE-bench Verified and LiveCodeBench. DGM goes further: it maintains an agent archive, samples from existing agents, then has a foundation model generate new variants, and retains high-quality branches after benchmark verification.
DGM has two particularly noteworthy aspects.
First, it's not a single-path hill climb; it preserves multiple evolutionary branches. This avoids a single change being effective in the short term but locking in the direction long-term.
Second, it improves not the underlying foundation model, but the agent's external structure: editing tools, context management, peer review mechanisms, patch validation, etc. In other words, it proves not that "models will train themselves to have smarter brains," but that "above a frozen model, there is still significant room for optimization in the agent's scaffolding."
This is also closer to what product teams can do today. You might not be able to train a new model, but you can have the agent generate PRs in a sandbox, run tests, compare metrics, retain effective changes, and then have humans review and merge them.
However, this approach has high security requirements. DGM's repository explicitly warns: running model-generated code carries risks. Real systems must have sandboxes, permission boundaries, resource limits, isolated test sets, rollback mechanisms, and human approval.
Phase Five: Enabling the model to generate its own training signals
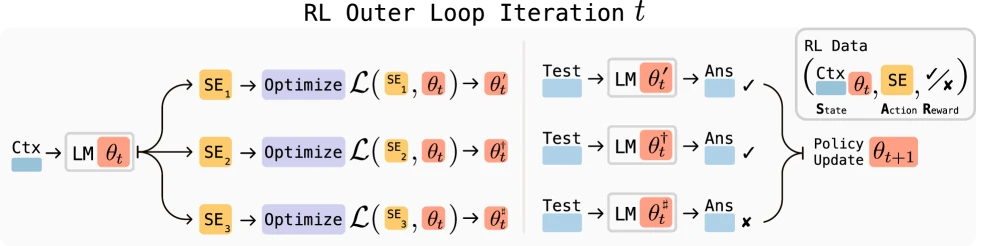
Another route, closer to model training, is to have the model participate in generating its own data, rewards, or update instructions.
Self-Rewarding Language Models uses LLM-as-a-judge to have the model provide reward signals for its own output, then trains via Iterative DPO. Its core problem is ambitious: if future models need feedback beyond human level, can the model itself gradually improve feedback quality?
SEAL: Self-Adapting Language Models goes further, having the model generate self-edits: these self-edits can be synthetic training data, information rewriting methods, hyperparameter optimization, or even calling data augmentation and gradient update tools. The model learns how to generate more effective self-edits by using downstream task performance as a reward.
SEAL:自适应语言模型
让语言模型根据新任务或新知识生成自己的微调数据和更新指令,从而产生持久权重更新。
There's also Self-Improving LLM Agents at Test-Time, which focuses on test-time self-improvement: the model first identifies samples it's uncertain about, then generates similar training examples around these samples, performs lightweight temporary parameter updates, and finally restores the original parameters. This direction is interesting because it pushes "learning" to the inference stage.
But the closer you get to weight updates, the more cautious you need to be.
Because once model weights are contaminated by incorrect data, self-evaluation bias, or malicious input, the problem is no longer just a single incorrect answer, but the system itself changing. For typical product teams, long-term memory, prompt optimization, workflow search, and sandboxed code improvements are more realistic than online self-modification of weights.
AlphaEvolve is closest to production practice
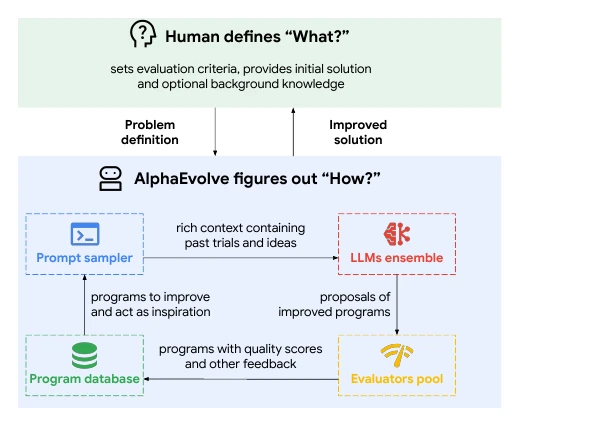
If we're looking at the production form of self-improving agents, AlphaEvolve is one of the most valuable case studies currently available.
AlphaEvolve:用于科学和算法发现的 coding agent
一个通过代码修改、自动评估器和演化式程序数据库来改进算法的 coding agent。
AlphaEvolve's core structure is straightforward:
Generate candidate programs
Run and score
Add high-scoring programs to the database
Continue sampling and mutating based on the database
RepeatIts power lies not in "letting the model think," but in task selection that is highly suitable for automated evaluation: algorithms, scheduling, hardware circuits, matrix multiplication, GPU kernels. As long as candidate programs can run, be verified, and be scored, the agent can explore on a large scale.
Google DeepMind's disclosed practices are also very specific: scheduling heuristics discovered by AlphaEvolve are already in use in Google data centers, recovering an average of 0.7% of global computing resources; it's also used for TPU circuit simplification, Gemini training-related kernel optimization, and mathematical and algorithmic discovery.
This provides a very important realistic assessment for self-improving agents:
The first self-improvements to be deployed will not appear in "can-do-anything" general assistants, but in narrow domains with clear evaluations, cheap feedback, and reversible errors.
Code, algorithms, compiler optimization, data processing pipelines, test generation, retrieval ranking, customer service routing, and internal operational processes are all more suitable for self-improvement than open-ended chat.
The real watershed is eval
Research into self-improving agents always comes back to evaluation.
OpenAI's agent eval documentation describes this in a very engineering-focused way: agent workflow evaluation should look at traces, graders, datasets, and eval runs. In other words, it's not just about the final answer, but the complete trajectory: model calls, tool calls, handoffs, guardrails, routing, failure points.
This is perfectly consistent with self-improving agents. Because an agent needs to know where it went wrong before it can improve itself.
A minimal self-improvement closed loop should look like this:
Production or test trajectory
↓
Failure attribution: wrong tool, wrong retrieval, wrong plan, wrong format, wrong permissions, wrong stopping time
↓
Generate candidate changes: prompt / workflow / tool schema / memory rule / code patch
↓
Offline evaluation: fixed dataset + regression set + cost and latency
↓
Sandbox verification: real tools but restricted permissions
↓
Manual review or automatic grayscale deployment
↓
Write to versioned assetsWithout this system, so-called self-improvement can easily turn into "feeding failed cases back into the prompt." While seemingly improving in the short term, it will lead to three long-term problems:
- Overfitting to recent failures: Fixing A today breaks B tomorrow.
- Reward hacking: The agent learns to cater to the grader instead of solving real problems.
- Boundary drift: To complete tasks, it quietly expands permissions, skips confirmations, and hides uncertainty.
Therefore, I view eval as the foundation of self-improving agents, not an auxiliary tool.
Safety issues are not something to defer
The more emphasis placed on self-improvement, the less safety can be left until last.
Anthropic's Measuring AI agent autonomy in practice, published in February 2026, highlights two noteworthy trends: the longest tail of autonomous work duration for Claude Code has significantly increased over several months; and experienced users more often enable auto-approval but also more frequently interrupt the process. This suggests that real-world agents are not simply moving towards "fully autonomous," but towards "longer periods of autonomous work + human intervention at critical moments."
For self-improving agents, this observation is crucial.
An agent that modifies itself cannot solely have the goal of "increasing success rate"; it must also optimize these constraints:
| Constraint | Questions to Answer |
|---|---|
| Permissions | Which files can it modify, which tools can it call, which data can it access? |
| Rollback capability | Does each self-modification have a version, diff, tests, and a rollback point? |
| Explainability | Why does it believe this change will improve things? What is the evidence? |
| Anti-cheating | Is the evaluation set isolated? Is the grader susceptible to prompt injection? |
| Human intervention | Which changes must pause for human confirmation? |
| Online monitoring | After a change goes live, is quality, cost, risk, and complaints continuously tracked? |
I even believe that truly mature self-improving agent products will not advertise "complete autonomy." They will advertise "supervised autonomy": the system identifies problems, proposes improvements, completes most validations, but critical permissions and long-term states are controlled by humans or organizational policies.
If you want to build one yourself, where should you start?
If I were to build a self-improving agent in a real product today, I wouldn't start by training a model. I would proceed in five layers.
Layer One: Complete trajectory logging
First, log the input, context version, prompt version, tool schema, tool calls, return results, errors, final output, user feedback, and manual modifications for each agent run. Without trajectories, there is no learning material.
Layer Two: Establish a fixed evaluation set
Sample from real failure cases to create an eval set that won't be easily contaminated by daily development. At least three categories:
| Type | Purpose |
|---|---|
| Golden tasks | Core capabilities must not degrade |
| Failure regression | Fixed issues must not recur |
| Stress tasks | Long chains, multiple tools, high permissions, ambiguous requirements |
Layer Three: Optimize prompts and tool descriptions first
This is the lowest cost, lowest risk layer. You can use GEPA, DSPy, OPRO-like approaches, or start with simple candidate prompt searches. The key is that each candidate must run against the same eval set, not rely on subjective feeling.
Layer Four: Optimize workflows
When prompt optimization reaches a certain point, problems usually emerge in the process. For example, incorrect retrieval location, no recovery strategy after tool failure, agent stopping too early or too late. At this point, AFlow/ADAS-like approaches can be introduced to represent the workflow as a modifiable object, then perform offline search.
Layer Five: Let the agent generate code changes, but it must go through a PR process
This is the layer closest to DGM/SICA. The agent can propose code patches, but patches should go through testing, review, permission restrictions, and grayscale deployment, just like regular engineering changes. Do not let it directly modify the production system.
As for online weight modification, I believe most teams should not touch it now. Unless you already have a very mature data governance, evaluation system, model training capabilities, and rollback mechanisms, the operational complexity it introduces will far outweigh the benefits.
Paper Reading Roadmap
If you just broadly search for self-improving agents, it's easy to get overwhelmed by terminology. I recommend reading in this order:
- Self-Refine and Reflexion: Understand the lightest reflection loop.
- STaR and Self-Rewarding Language Models: Understand self-generated training signals.
- Voyager: Understand skill libraries and continuous accumulation in open-ended environments.
- OPRO, GEPA, TextGrad: Understand how natural language feedback optimizes prompts, code, and system components.
- ADAS and AFlow: Understand how agent workflows are automatically designed.
- A Self-Improving Coding Agent and DGM: Understand how agents modify their own implementation.
- SEAL and Self-Improving LLM Agents at Test-Time: Understand weight updates and test-time adaptation.
- AlphaEvolve: Understand the evolutionary coding agent closest to production value.
- A Survey of Self-Evolving Agents: Finally, read the survey to put the concepts back into a complete classification.
Self-Evolving Agents 综述
一篇按“改什么、什么时候改、怎么改”梳理 self-evolving agent 的系统综述。
My Assessment
Self-improving agents are most easily misinterpreted as an AGI narrative: models modifying themselves, leading to exponential capability growth.
However, based on current papers and practices, a more reliable assessment is:
The near-term value of self-improving agents is not to replace model training, but to advance agent engineering from manual tuning to evaluation-driven automatic optimization.
Its core asset is not a "smarter model," but a closed-loop system that:
- Has real task trajectories.
- Has executable evaluations.
- Has versioned prompts, workflows, tools, memory, and code.
- Has mechanisms for automatically generating candidate changes.
- Has safety boundaries, regression tests, and human approval.
This may not sound as exciting as "recursive self-evolution," but it's more important. Because it transforms agents from one-off demos into systems that can be maintained long-term.
If agents truly become continuously stronger in the future, it's highly likely not to start from a mysterious moment, but from these seemingly engineering-focused closed loops: every failure is recorded, every change is evaluated, every effective experience is solidified, and every out-of-bounds attempt is blocked.
A true self-improving agent is not an agent that says, "I have reflected."
It should be an agent that can prove, "This change I made has indeed improved the system, and without breaking boundaries."
Related Posts
From Eclipse to Zed: A Developer's Editor Evolution
From backend to full-stack development, from VS Code with 200+ plugins to a terminal-first workflow — how my editor choices evolved with the AI era
My Claude Code Best Practices
Sharing my experience with Claude Code — 10 core tips, slash command guide, and custom command configuration to boost your AI programming efficiency
My Claude Code Quality Control Workflow
Sharing my quality control practices with Claude Code — Hooks automation, testing strategy, AI Review, Pre-commit, and GitHub integration as 5 lines of defense