Guide pratique
Maîtriser le flux de travail complet des commandes speckit, des spécifications au code : détail des commandes, démonstration complète et bonnes pratiques
Introduction
Dans l'article précédent, nous avons découvert la philosophie du développement piloté par les spécifications — définir d'abord « quoi faire », puis réfléchir au « comment faire ». Ce processus, qui peut sembler superflu, réduit en réalité considérablement les reprises et les coûts de communication dans la programmation avec IA.
Dans cet article, nous passons à la pratique. Vous apprendrez à utiliser la série de commandes speckit pour accomplir le flux de travail complet, de la description des besoins à l'implémentation du code.
Installation et configuration
Les commandes Speckit proviennent du projet officiel Spec Kit de GitHub. Selon votre cas d'utilisation, il existe plusieurs modes d'intégration.
Initialisation d'un nouveau projet
Pour un nouveau projet, il est recommandé d'utiliser l'outil officiel specify-cli pour l'initialisation :
# Installer specify-cli avec uv
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
# Initialiser un nouveau projet en spécifiant Claude comme assistant IA
specify init my-project --ai claudeCela crée automatiquement la structure du répertoire du projet, incluant le répertoire de configuration .specify/ et les fichiers de modèles associés.
Intégration dans un projet existant
Les commandes Speckit nécessitent des fichiers de configuration pour fonctionner. Pour intégrer speckit dans un projet existant, il est recommandé d'utiliser specify-cli :
cd your-existing-project
specify init . --ai claude # Notez le . qui désigne le répertoire courantCela crée dans votre projet :
your-project/
├── .specify/
│ ├── templates/ # Modèles de spécifications, plans, etc.
│ ├── scripts/ # Scripts auxiliaires
│ └── memory/ # constitution.md
├── .claude/
│ └── commands/ # Configuration des commandes Claude Code
│ ├── speckit.specify.md
│ ├── speckit.plan.md
│ └── ...
└── specs/ # Répertoire de stockage des spécificationsL'initialisation ne remplace pas vos fichiers existants. Une fois terminée, vous pouvez utiliser la série de commandes /speckit.* dans Claude Code.
Remarque : les commandes speckit ne sont pas intégrées nativement à Claude Code. Vous devez d'abord compléter les étapes d'initialisation ci-dessus. Si vous exécutez directement
/speckit.specify, un message indiquera que la commande n'existe pas.
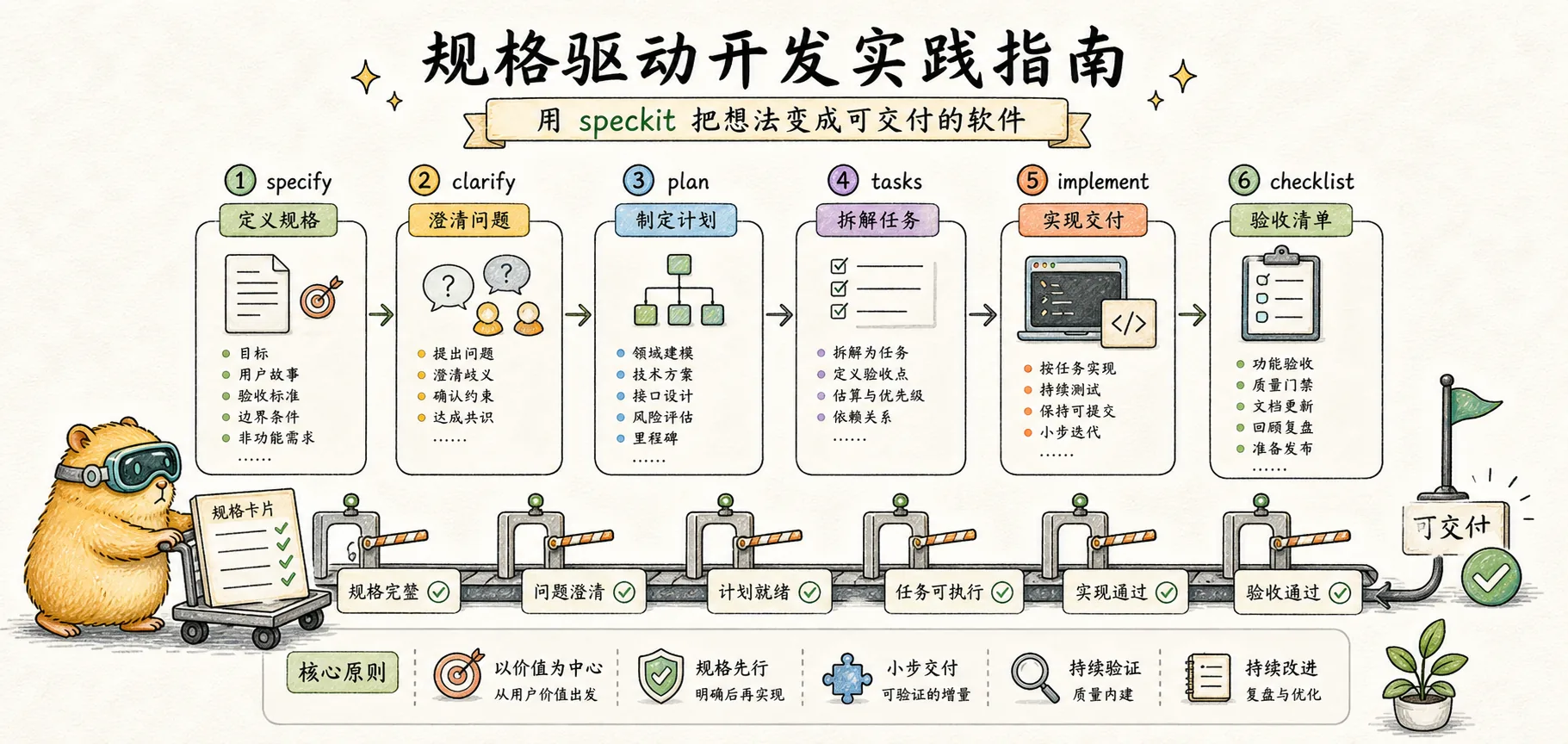
Détail des commandes
Speckit fournit un ensemble de commandes pour accompagner chaque étape du développement piloté par les spécifications. Chaque commande a des entrées et des sorties clairement définies, formant une chaîne traçable.
/speckit.specify — Créer une spécification fonctionnelle
C'est le point de départ de l'ensemble du processus. Vous décrivez la fonctionnalité souhaitée en langage naturel, et l'IA vous aide à l'organiser en un document de spécification structuré.
Fonction : Créer un document de spécification fonctionnelle à partir d'une description en langage naturel
Entrée : Description de la fonctionnalité (langage naturel)
Sortie :
specs/[numéro]-[nom-fonctionnalité]/spec.md— Document de spécification fonctionnelle- Nouvelle branche git (par ex.
001-user-auth)
Exemple d'utilisation :
/speckit.specify Je souhaite ajouter une fonctionnalité de connexion utilisateur, avec authentification par email et mot de passe, et une option pour mémoriser l'état de connexionAprès exécution, l'IA va :
- Générer un nom court pour la fonctionnalité (par ex.
user-auth) - Créer une nouvelle branche de fonctionnalité
- Produire un document de spécification contenant les user stories, les exigences fonctionnelles et les critères de succès
- Marquer les points ambigus avec
[NEEDS CLARIFICATION]
Structure principale du document de spécification :
# Feature Specification: Fonctionnalité de connexion utilisateur
## User Scenarios & Testing
### User Story 1 - Connexion utilisateur (Priority: P1)
L'utilisateur se connecte au système via email et mot de passe...
**Acceptance Scenarios**:
1. Given l'utilisateur saisit un email et un mot de passe corrects, When il clique sur Connexion, Then il accède au système avec succès
## Requirements
### Functional Requirements
- FR-001: Le système doit prendre en charge l'authentification par email et mot de passe
- FR-002: Le système doit proposer une option « Se souvenir de moi »
## Success Criteria
- SC-001: L'utilisateur doit pouvoir compléter le processus de connexion en moins de 30 secondesNotez que le document de spécification ne contient aucun détail technique — il ne mentionne ni framework, ni structure de base de données, ni définition d'API. Tout cela relève des étapes suivantes.
/speckit.clarify — Clarifier les zones d'ombre
Une fois le document de spécification rédigé, certains points peuvent rester flous. Cette commande examine la spécification et pose des questions clés pour vous aider à la préciser.
Fonction : Identifier les zones d'ombre dans la spécification et la perfectionner par un jeu de questions-réponses
Entrée : Document spec.md existant
Sortie : spec.md mis à jour (incluant l'historique des clarifications)
Exemple d'utilisation :
/speckit.clarifyAprès exécution, l'IA va :
- Scanner les zones d'ombre du document de spécification
- Les trier par priorité (périmètre > sécurité > expérience utilisateur > détails techniques)
- Poser les questions une par une, une seule à la fois
- Mettre à jour le document de spécification en fonction de vos réponses
Exemple de questions-réponses :
## Question 1: Gestion des échecs de connexion
**Context**: La spécification mentionne la connexion utilisateur, mais ne précise pas la gestion des échecs de connexion.
**Recommended:** Option B - Verrouiller le compte après 5 tentatives consécutives est une bonne pratique de sécurité
| Option | Description |
|--------|-------------|
| A | Afficher uniquement un message d'erreur, sans restriction |
| B | Verrouiller le compte pendant 15 minutes après 5 échecs consécutifs |
| C | Utiliser un captcha pour prévenir les attaques par force brute |
Vous pouvez répondre avec la lettre de l'option (par ex. "B"), dire "yes" pour accepter la recommandation, ou fournir votre propre réponse.Après chaque clarification, le document de spécification est automatiquement mis à jour avec l'historique des clarifications :
## Clarifications
### Session 2025-12-20
- Q: Comment gérer les échecs de connexion ? → R: Verrouiller le compte pendant 15 minutes après 5 échecs consécutifs/speckit.plan — Générer le plan technique
Une fois la spécification clarifiée, on passe à la phase de conception technique. Cette étape produit le plan technique et le rapport de recherche.
Fonction : Générer un plan d'implémentation technique à partir de la spécification
Entrée : Document spec.md
Sortie :
plan.md— Plan technique (architecture, modèle de données, conception d'API)research.md— Rapport de recherche (décisions de choix technologiques)data-model.md— Modèle de données (le cas échéant)contracts/— Contrats d'API (le cas échéant)
Exemple d'utilisation :
/speckit.plan J'utilise Next.js + Prisma + PostgreSQLVous pouvez ajouter vos préférences de stack technique après la commande. Après exécution, l'IA va :
- Analyser les exigences fonctionnelles de la spécification
- Rechercher les bonnes pratiques des technologies concernées
- Concevoir le modèle de données et la structure d'API
- Produire un plan technique complet
Contenu principal du plan technique :
# Implementation Plan: Fonctionnalité de connexion utilisateur
## Technical Context
**Language/Version**: TypeScript 5.x
**Primary Dependencies**: Next.js 15, Prisma, PostgreSQL
**Authentication**: NextAuth.js with credentials provider
## Project Structure
src/
├── app/
│ └── (auth)/
│ ├── login/
│ └── api/auth/
├── lib/
│ └── auth/
└── prisma/
└── schema.prisma
## Data Model
- User: id, email, passwordHash, createdAt, updatedAt
- Session: id, userId, expiresAt/speckit.tasks — Décomposer en tâches
Le plan technique est prêt, l'étape suivante consiste à le découper en une liste de tâches exécutables.
Fonction : Décomposer le plan technique en une liste de tâches exécutables
Entrée : Document plan.md
Sortie : tasks.md — Liste de tâches ordonnées par dépendances
Exemple d'utilisation :
/speckit.tasksAprès exécution, l'IA va :
- Extraire les solutions techniques du plan.md
- Extraire les priorités des user stories du spec.md
- Générer les tâches regroupées par user story
- Marquer les tâches parallélisables avec
[P] - Spécifier les chemins de fichiers concrets pour chaque tâche
Format de la liste de tâches :
## Phase 1: Setup
- [ ] T001 Créer la structure du projet
- [ ] T002 [P] Configurer le schéma Prisma
- [ ] T003 [P] Configurer NextAuth
## Phase 2: User Story 1 - Connexion utilisateur (P1)
- [ ] T004 [US1] Créer le modèle User in prisma/schema.prisma
- [ ] T005 [US1] Implémenter l'API de connexion in src/app/api/auth/[...nextauth]/route.ts
- [ ] T006 [US1] Créer la page de connexion in src/app/(auth)/login/page.tsxChaque tâche comporte :
- ID de tâche (T001, T002...) — pour le suivi
- Marqueur [P] — indique que la tâche peut être exécutée en parallèle avec d'autres tâches [P]
- Étiquette [US] — indique à quelle user story la tâche appartient
- Chemin de fichier — précise quel fichier doit être modifié
/speckit.implement — Exécuter l'implémentation
Tout est prêt, il est temps d'exécuter la liste de tâches.
Fonction : Exécuter les tâches de la liste une par une
Entrée : Document tasks.md
Sortie : Code réel
Exemple d'utilisation :
/speckit.implementAvant l'exécution, l'IA vérifie la checklist (si elle existe). Pendant l'exécution :
- Les tâches sont exécutées dans l'ordre des phases
- Chaque tâche terminée est marquée
[X] - Les dépendances entre tâches sont respectées
- Les tâches parallèles peuvent être traitées simultanément
Exemple de déroulement :
Phase 1: Setup
✓ T001 Créer la structure du projet
✓ T002 Configurer le schéma Prisma
✓ T003 Configurer NextAuth
Phase 2: User Story 1
✓ T004 Créer le modèle User
Exécution de T005 en cours...Revue post-implémentation
Une fois /speckit.implement terminé, ne fusionnez pas directement le code. Le code généré par l'IA nécessite une revue humaine :
Étapes de validation indispensables :
-
Exécuter la suite de tests
npm test # ou votre commande de testAssurez-vous que l'IA n'a pas cassé les fonctionnalités existantes.
-
Points clés de la revue de code
- Le code est-il conforme à l'intention de la spécification (vérifier par rapport au spec.md) ?
- Respecte-t-il les conventions de codage du projet ?
- Y a-t-il des problèmes de sécurité potentiels ?
-
Tests aux limites Testez manuellement les cas limites que l'IA aurait pu négliger :
- Gestion des valeurs nulles
- Entrées extrêmes
- Scénarios de concurrence
- Chemins d'erreur
-
Vérification des performances Si des opérations de base de données ou des appels d'API sont impliqués, vérifiez s'il y a des problèmes de performance comme des requêtes N+1.
Conseil : même si la spécification est très détaillée, l'IA peut encore dévier dans les détails d'implémentation. La revue ne remet pas en question le développement piloté par les spécifications, elle fait partie de la discipline d'ingénierie.
/speckit.analyze — Analyse de cohérence
C'est une étape optionnelle de contrôle qualité, utilisée pour vérifier la cohérence entre la spécification, le plan et les tâches.
Fonction : Analyse de cohérence et de qualité inter-documents
Entrée : spec.md, plan.md, tasks.md
Sortie : Rapport d'analyse (aucun fichier n'est modifié)
Exemple d'utilisation :
/speckit.analyzeAprès exécution, les vérifications suivantes sont effectuées :
- Chaque exigence a-t-elle une tâche correspondante ?
- Les tâches couvrent-elles toutes les user stories ?
- La terminologie est-elle cohérente ?
- Y a-t-il des oublis ou des doublons ?
Autres commandes (optionnelles)
Outre les commandes principales ci-dessus, speckit fournit quelques commandes auxiliaires. Elles ne font pas partie du flux principal, mais sont utiles dans certaines situations.
/speckit.constitution — Créer la constitution du projet
Permet de définir les principes de développement et les normes du projet. Idéal pour les projets d'équipe, afin de garantir que tous les membres suivent des standards de développement uniformes.
- Entrée : Questions-réponses interactives ou principes fournis directement
- Sortie : Fichier
.specify/constitution.mdde constitution du projet - Cas d'usage : Initialisation d'un projet d'équipe, unification du style de code et des décisions architecturales
/speckit.checklist — Générer une checklist qualité
Génère une checklist qualité personnalisée basée sur la spécification fonctionnelle, utilisée pour confirmer les standards de qualité avant l'implémentation.
- Entrée : Document spec.md
- Sortie : Checklists dans le répertoire
checklists/ - Cas d'usage : Contrôle qualité avant la mise en production d'une fonctionnalité importante, référence pour la revue de code
/speckit.taskstoissues — Convertir les tâches en GitHub Issues
Convertit automatiquement les tâches du tasks.md en GitHub Issues, facilitant la collaboration en équipe et l'attribution des tâches.
- Entrée : Document tasks.md
- Sortie : GitHub Issues (créées via gh CLI)
- Cas d'usage : Développement collaboratif en équipe, planification de Sprint, suivi des tâches
Écosystème d'outils
Les commandes speckit présentées dans cet article proviennent du projet GitHub Spec Kit. Par ailleurs, en 2025, plusieurs outils de programmation IA majeurs ont commencé à prendre en charge des flux de travail similaires pilotés par les spécifications :
| Outil | Caractéristiques | Cas d'usage |
|---|---|---|
| GitHub Spec Kit | Outil utilisé dans cet article, open source MIT, compatible Claude Code / Copilot / Gemini CLI | Adeptes de la ligne de commande, collaboration inter-outils |
| AWS Kiro | Fork de VS Code, flux visuel, notation EARS | Adeptes de l'interface graphique, utilisateurs de l'écosystème AWS |
| JetBrains Junie | Intégration à l'écosystème IntelliJ, mode de raisonnement Think More | Utilisateurs d'IDE JetBrains |
| Cursor Plan Mode | Phase de planification intégrée, génération automatique de plans d'exécution | Développeurs utilisant déjà Cursor |
Comment choisir :
- Si vous utilisez Claude Code, GitHub Copilot ou Gemini CLI, GitHub Spec Kit est recommandé
- Si vous préférez les interfaces graphiques et les flux de travail visuels, essayez AWS Kiro
- Si vous êtes utilisateur de JetBrains, l'intégration de Junie avec l'IDE est plus naturelle
- Si vous utilisez déjà Cursor, son Plan Mode offre des capacités de planification similaires
La philosophie fondamentale est la même — l'outil n'est qu'un véhicule, l'important est la mentalité spécifications d'abord, code ensuite.
Démonstration complète
Parcourons le flux complet de speckit à travers un cas pratique.
Scénario : Ajouter une fonctionnalité de favoris d'articles pour un système de blog
Étape 1 : Créer la spécification
/speckit.specify Je souhaite ajouter une fonctionnalité de favoris pour le blog. Les utilisateurs peuvent mettre en favoris les articles qu'ils aiment et consulter leur liste de favoris dans leur espace personnelL'IA génère le document de spécification specs/002-article-bookmark/spec.md :
# Feature Specification: Fonctionnalité de favoris d'articles
## User Scenarios & Testing
### User Story 1 - Mettre un article en favoris (Priority: P1)
L'utilisateur, en lisant un article, clique sur le bouton favoris pour ajouter l'article à sa liste de favoris.
**Acceptance Scenarios**:
1. Given l'utilisateur est connecté, When il clique sur le bouton favoris, Then l'article est ajouté à la liste de favoris
2. Given l'utilisateur n'est pas connecté, When il clique sur le bouton favoris, Then il est invité à se connecter
### User Story 2 - Consulter la liste de favoris (Priority: P2)
L'utilisateur consulte tous les articles mis en favoris dans son espace personnel.
## Requirements
- FR-001: L'utilisateur doit pouvoir ajouter/retirer un article de ses favoris
- FR-002: Le bouton favoris doit afficher l'état actuel du favori
- FR-003: L'espace personnel doit afficher la liste des favoris
## Success Criteria
- SC-001: L'opération de mise en favoris doit s'effectuer en moins de 500 ms
- SC-002: La liste de favoris doit prendre en charge la pagination, avec 10 articles par pageÉtape 2 : Clarifier les besoins
/speckit.clarifyL'IA pose la question : « Y a-t-il un nombre maximum de favoris ? »
Réponse : « Maximum 100 articles en favoris »
La spécification est mise à jour avec :
- FR-004: Chaque utilisateur peut mettre en favoris un maximum de 100 articles
- Un message s'affiche lorsque la limite est atteinte
Étape 3 : Générer le plan
/speckit.plan Utilisation de Next.js + PrismaUn plan technique est généré, incluant :
- Modèle Bookmark (userId, articleId, createdAt)
- Conception des routes API (POST/DELETE /api/bookmarks)
- Conception des composants (BookmarkButton, BookmarkList)
Étape 4 : Décomposer en tâches
/speckit.tasksListe de tâches générée :
## Phase 1: Setup
- [ ] T001 Ajouter le modèle Bookmark au schéma Prisma
## Phase 2: US1 - Mettre en favoris
- [ ] T002 [US1] Créer l'API de favoris in src/app/api/bookmarks/route.ts
- [ ] T003 [US1] Créer le composant BookmarkButton in src/components/BookmarkButton.tsx
- [ ] T004 [US1] Intégrer à la page d'article
## Phase 3: US2 - Liste de favoris
- [ ] T005 [US2] Créer la page de liste de favoris in src/app/profile/bookmarks/page.tsx
- [ ] T006 [US2] Implémenter la logique de paginationÉtape 5 : Exécuter l'implémentation
/speckit.implementLes tâches sont exécutées dans l'ordre, chacune marquée [X] une fois terminée.
Bonnes pratiques et points d'attention
Quand utiliser speckit
Scénarios adaptés :
- Développement de nouvelles fonctionnalités (impliquant 3 fichiers ou plus)
- Besoins pas entièrement définis (clarification via clarify)
- Projets collaboratifs (la spécification comme consensus)
- Fonctionnalités importantes (nécessitant une traçabilité)
Scénarios inadaptés :
- Corrections de bugs simples
- Modifications d'une seule ligne de code
- Correctifs urgents (hotfix)
- Expérimentations purement exploratoires
Pièges courants
Lors de l'utilisation de speckit, plusieurs pièges courants méritent votre attention :
Piège 1 : Spécification trop vague
Symptôme : Le code généré par l'IA s'éloigne fortement des attentes, nécessitant de nombreuses reprises.
# ❌ Spécification vague
L'utilisateur peut rechercher des articles
# ✓ Spécification claire
- FR-001: L'utilisateur peut rechercher des articles par mots-clés dans le titre
- FR-002: Les résultats de recherche sont triés par pertinence, avec 10 résultats par page
- FR-003: Les termes recherchés sont surlignés dans les résultats
- FR-004: Lorsque le champ de recherche est vide, les articles populaires sont affichésSolution : Exécutez /speckit.clarify, ou complétez manuellement les exigences fonctionnelles et les critères de succès.
Piège 2 : Spécification trop détaillée
Symptôme : L'IA est tellement contrainte qu'elle ne peut pas s'exprimer, le code généré est trop rigide, ou elle ignore tout simplement certaines instructions.
# ❌ Trop détaillé (spécifie les détails d'implémentation)
Utiliser la fonction debounce de lodash, délai de 300ms,
envelopper avec useCallback, dépendances : [searchTerm]...
# ✓ Niveau de détail approprié (dit seulement quoi faire)
La saisie de recherche doit être anti-rebond pour éviter les requêtes trop fréquentesSolution : Gardez la spécification au niveau du « quoi faire », laissez le « comment faire » à la phase Plan.
Piège 3 : Sauter la phase Plan
Symptôme : Les tâches sont trop grossières ou trop fragmentées, reprises fréquentes lors de l'implémentation, relations de dépendance chaotiques entre les tâches.
Solution : Pour les fonctionnalités complexes, complétez impérativement la phase Plan. Le Plan ne produit pas seulement une solution technique, il aide aussi à identifier les problèmes architecturaux potentiels.
Piège 4 : Fusionner sans revue
Symptôme : Après la mise en production, on découvre des cas limites non traités, des failles de sécurité, des problèmes de performance.
Solution : Référez-vous à la section « Revue post-implémentation » ci-dessus, et exécutez toujours les tests et la revue de code avant de fusionner.
Questions fréquentes
Q : Faut-il suivre le processus complet pour chaque fonctionnalité ?
Non. Les modifications simples peuvent être codées directement. Pour les fonctionnalités complexes, il est recommandé de compléter au minimum specify + plan.
Q : La spécification est très détaillée, mais l'IA génère quand même du code qui ne correspond pas aux attentes ?
Vérifiez si la spécification est vraiment « détaillée ». Souvent, nous pensons avoir été clairs alors qu'il reste des zones d'ombre. Essayez d'exécuter /speckit.clarify pour voir s'il y a des oublis.
Q : Peut-on sauter certaines étapes ?
Oui. Le flux minimal est specify, puis tasks, puis implement. Cependant, sauter clarify et plan peut augmenter le risque de reprises ultérieures.
Q : Comment modifier une spécification déjà générée ?
Éditez directement le fichier spec.md. Après modification, il est recommandé de relancer plan et tasks pour maintenir la cohérence.
Q : Le code généré par l'IA est complètement erroné, comment déboguer ?
Procédez par étapes :
- Vérifier la spécification : la spécification est-elle vraiment claire ? Essayez d'exécuter
/speckit.clarifypour voir s'il y a des oublis - Vérifier le plan : la solution technique dans plan.md est-elle pertinente ? Si elle ne l'est pas, éditez-la directement puis régénérez les tasks
- Réduire le périmètre : faites exécuter une seule tâche par l'IA et observez si le résultat correspond aux attentes
- Ajouter des contraintes : ajoutez des préférences techniques plus explicites dans constitution.md
Q : Que faire si le Plan et les Tasks sont incohérents ?
Exécutez /speckit.analyze pour détecter les incohérences. Causes courantes :
- Le Plan a été mis à jour mais les Tasks n'ont pas été régénérées
- Les Tasks ont été modifiées manuellement sans mettre à jour le Plan
- La spécification a changé mais seule une partie des documents a été mise à jour
Solution : Prenez spec.md comme référence, puis régénérez successivement plan.md et tasks.md.
Q : Comment gérer les dépendances inter-fonctionnalités ?
Si la fonctionnalité B dépend de la fonctionnalité A, deux approches sont possibles :
- Fusionner les spécifications : intégrez A et B dans un même spec.md et laissez l'IA planifier de manière unifiée
- Développement par étapes : complétez d'abord le processus complet de A, puis commencez le specify de B
Il est déconseillé de développer simultanément plusieurs fonctionnalités ayant des dépendances entre elles, car cela risque de causer des problèmes d'intégration.
Synthèse
La valeur fondamentale de Speckit n'est pas d'ajouter des processus, mais de rendre explicites les connaissances implicites. Lorsqu'on vous demande de rédiger des user stories, des exigences fonctionnelles et des critères de succès, tous ces détails que vous pensiez « évidents » émergent à la surface.
Retenez ce processus :
Specify → Clarify → Plan → Tasks → Implement
Besoins Clarifier Concevoir Découper ExécuterChaque étape réduit l'ambiguïté pour la suivante. Au final, l'IA reçoit une liste de tâches claire, et non une description d'intentions vague.
Maintenant, retournez à votre projet et essayez de lancer /speckit.specify pour démarrer votre premier flux de développement piloté par les spécifications.
Lectures complémentaires
- Qu'est-ce que le développement piloté par les spécifications — Revoir les concepts fondamentaux
- Analyse approfondie de GSD — Un autre système d'ingénierie contextuelle adoptant la pensée pilotée par les spécifications
- Qu'est-ce que Claude Skills — Speckit est lui-même un Claude Skill
Commentaires
Introduction conceptuelle
Du Vibe Coding au développement piloté par les spécifications : comprendre comment la programmation avec IA passe de l'« intuition » à l'« ingénierie », et maîtriser le nouveau paradigme qui consiste à écrire les spécifications avant le code
Ralph Wiggum - Analyse approfondie
Comprendre les principes fondamentaux de la technique Ralph : pourquoi une simple boucle bash permet a l'IA d'ecrire du code pendant que vous dormez