Guía práctica
Domine el flujo de trabajo completo de especificación a código con los comandos speckit — referencia de comandos, demostración de extremo a extremo y mejores prácticas
Introducción
En el artículo anterior, exploramos la filosofía del desarrollo dirigido por especificaciones — definir "qué construir" antes de pensar en "cómo construirlo". Aunque este paso adicional pueda parecer innecesario, reduce drásticamente el retrabajo y los costos de comunicación en la programación asistida por IA.
En este artículo, pasamos a la práctica. Aprenderá a utilizar la suite de comandos speckit para completar el flujo de trabajo completo, desde los requisitos hasta el código funcional.
Instalación y configuración
Los comandos de Speckit provienen del proyecto oficial Spec Kit de GitHub. Dependiendo de su caso de uso, existen varias formas de integrarlos.
Inicialización de un proyecto nuevo
Para proyectos nuevos, el enfoque recomendado es utilizar la herramienta oficial specify-cli:
# Instalar specify-cli usando uv
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
# Inicializar un nuevo proyecto, especificando Claude como asistente de IA
specify init my-project --ai claudeEsto crea automáticamente la estructura de directorios del proyecto, incluyendo el directorio de configuración .specify/ y los archivos de plantilla relacionados.
Integración con un proyecto existente
Los comandos de Speckit requieren archivos de configuración para funcionar. Para integrar speckit en un proyecto existente, utilice specify-cli:
cd your-existing-project
specify init . --ai claude # Nota: . se refiere al directorio actualEsto crea lo siguiente en su proyecto:
your-project/
├── .specify/
│ ├── templates/ # Plantillas de especificaciones, planes, etc.
│ ├── scripts/ # Scripts auxiliares
│ └── memory/ # constitution.md
├── .claude/
│ └── commands/ # Configuraciones de comandos de Claude Code
│ ├── speckit.specify.md
│ ├── speckit.plan.md
│ └── ...
└── specs/ # Directorio de almacenamiento de especificacionesLa inicialización no sobrescribirá sus archivos existentes. Una vez completada, podrá utilizar la suite de comandos /speckit.* en Claude Code.
Nota: Los comandos de speckit no están integrados en Claude Code — primero debe completar los pasos de inicialización descritos anteriormente. Ejecutar
/speckit.specifysin la inicialización resultará en un error de "comando no encontrado".
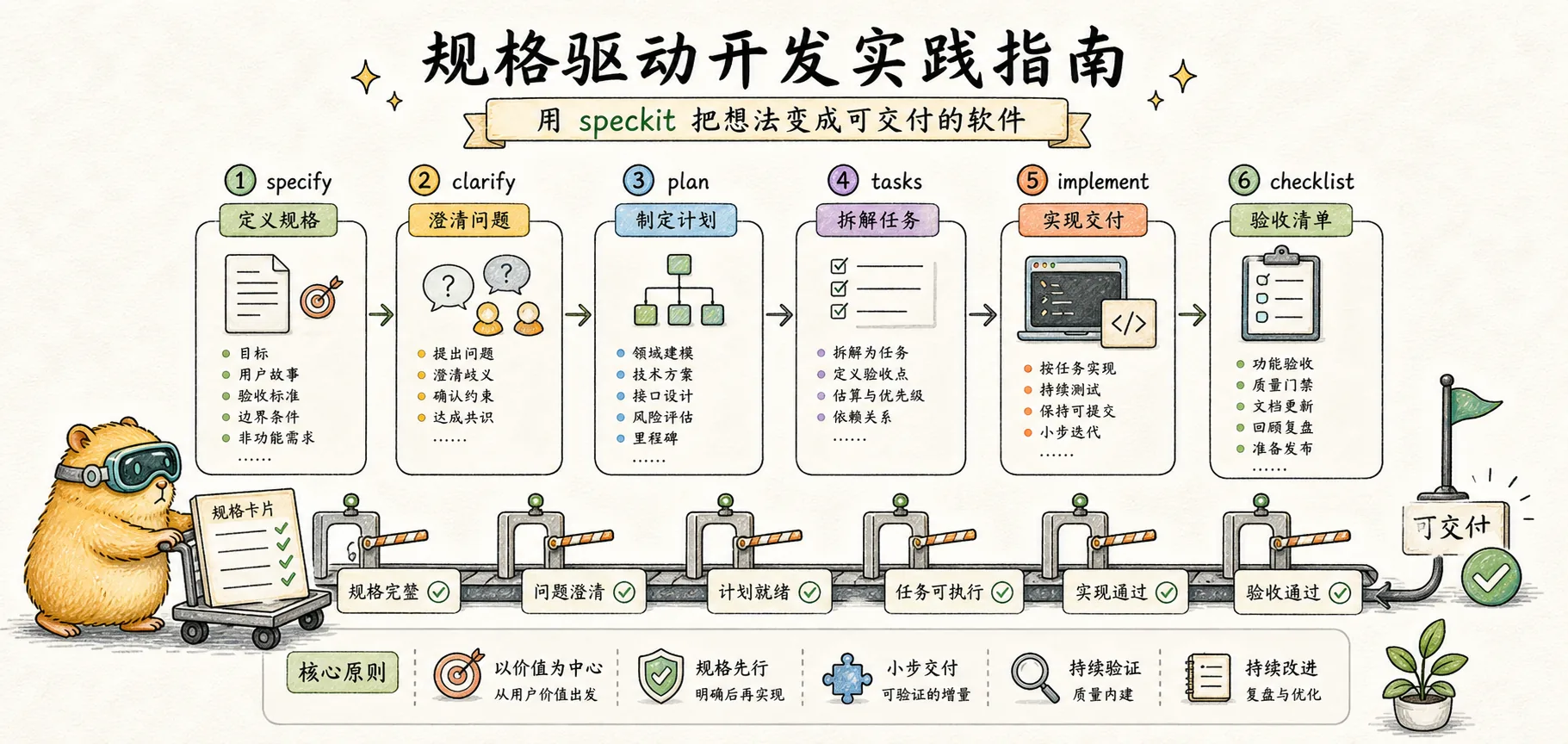
Referencia de comandos
Speckit proporciona un conjunto de comandos que soportan cada fase del desarrollo dirigido por especificaciones. Cada comando tiene entradas y salidas bien definidas, formando una cadena trazable.
/speckit.specify — Crear una especificación de funcionalidad
Este es el punto de partida de todo el flujo de trabajo. Usted describe la funcionalidad deseada en lenguaje natural y la IA la organiza en un documento de especificación estructurado.
Propósito: Crear una especificación de funcionalidad a partir de una descripción en lenguaje natural
Entrada: Descripción de la funcionalidad (lenguaje natural)
Salida:
specs/[número]-[nombre-funcionalidad]/spec.md— Documento de especificación- Una nueva rama de git (por ejemplo,
001-user-auth)
Ejemplo de uso:
/speckit.specify Quiero agregar una funcionalidad de inicio de sesión con autenticación por correo electrónico/contraseña y una opción de "recordarme"Después de la ejecución, la IA:
- Genera un nombre corto para la funcionalidad (por ejemplo,
user-auth) - Crea una nueva rama de funcionalidad
- Produce un documento de especificación con historias de usuario, requisitos funcionales y criterios de éxito
- Marca las áreas poco claras con
[NEEDS CLARIFICATION]
Estructura central de un documento de especificación:
# Feature Specification: Inicio de sesión de usuario
## User Scenarios & Testing
### User Story 1 - Inicio de sesión (Priority: P1)
Los usuarios inician sesión en el sistema usando correo electrónico y contraseña...
**Acceptance Scenarios**:
1. Given correo y contraseña válidos, When se hace clic en iniciar sesión, Then se ingresa exitosamente al sistema
## Requirements
### Functional Requirements
- FR-001: El sistema debe soportar inicio de sesión con correo/contraseña
- FR-002: El sistema debe proporcionar una opción de "recordarme"
## Success Criteria
- SC-001: Los usuarios pueden completar el flujo de inicio de sesión en 30 segundosNote que el documento de especificación no contiene detalles técnicos — no menciona frameworks, esquemas de bases de datos ni definiciones de API. Eso viene en fases posteriores.
/speckit.clarify — Resolver ambigüedades
Después de redactar la especificación, pueden quedar áreas ambiguas. Este comando revisa la especificación y formula preguntas clave para ayudar a aclararlas.
Propósito: Identificar ambigüedades en la especificación y refinarla mediante preguntas y respuestas
Entrada: Documento spec.md existente
Salida: spec.md actualizado (con registros de aclaraciones)
Ejemplo de uso:
/speckit.clarifyDespués de la ejecución, la IA:
- Escanea la especificación en busca de puntos ambiguos
- Los prioriza (Alcance > Seguridad > Experiencia de usuario > Detalles técnicos)
- Formula una pregunta a la vez
- Actualiza la especificación según sus respuestas
Ejemplo de preguntas y respuestas:
## Question 1: Manejo de fallos de inicio de sesión
**Context**: La especificación menciona el inicio de sesión pero no especifica cómo se deben manejar los fallos.
**Recommended:** Opción B - Bloquear la cuenta después de 5 intentos fallidos consecutivos es una mejor práctica de seguridad
| Option | Description |
|--------|-------------|
| A | Mostrar solo mensaje de error, sin restricciones |
| B | Bloquear la cuenta durante 15 minutos después de 5 fallos consecutivos |
| C | Usar CAPTCHA para prevenir ataques de fuerza bruta |
Puede responder con una letra de opción (por ejemplo, "B"), decir "yes" para aceptar la recomendación, o proporcionar su propia respuesta.Después de cada aclaración, el documento de especificación se actualiza automáticamente con un registro de aclaración:
## Clarifications
### Session 2025-12-20
- Q: ¿Cómo se deben manejar los fallos de inicio de sesión? → A: Bloquear la cuenta durante 15 minutos después de 5 fallos consecutivos/speckit.plan — Generar un plan técnico
Una vez que la especificación está clara, se pasa a la fase de diseño técnico. Este paso produce un plan técnico y un informe de investigación.
Propósito: Generar un plan de implementación técnica a partir de la especificación
Entrada: Documento spec.md
Salida:
plan.md— Plan técnico (arquitectura, modelos de datos, diseño de API)research.md— Informe de investigación (decisiones de selección tecnológica)data-model.md— Modelo de datos (si aplica)contracts/— Contratos de API (si aplica)
Ejemplo de uso:
/speckit.plan Estoy usando Next.js + Prisma + PostgreSQLPuede agregar sus preferencias de stack tecnológico después del comando. Después de la ejecución, la IA:
- Analiza los requisitos funcionales de la especificación
- Investiga las mejores prácticas para las tecnologías relevantes
- Diseña modelos de datos y estructuras de API
- Produce un plan técnico completo
Contenido central de un plan técnico:
# Implementation Plan: Inicio de sesión de usuario
## Technical Context
**Language/Version**: TypeScript 5.x
**Primary Dependencies**: Next.js 15, Prisma, PostgreSQL
**Authentication**: NextAuth.js with credentials provider
## Project Structure
src/
├── app/
│ └── (auth)/
│ ├── login/
│ └── api/auth/
├── lib/
│ └── auth/
└── prisma/
└── schema.prisma
## Data Model
- User: id, email, passwordHash, createdAt, updatedAt
- Session: id, userId, expiresAt/speckit.tasks — Descomponer tareas
Con el plan técnico listo, el siguiente paso es descomponerlo en una lista de tareas ejecutables.
Propósito: Dividir el plan técnico en una lista de tareas ejecutables
Entrada: Documento plan.md
Salida: tasks.md — Lista de tareas ordenada por dependencias
Ejemplo de uso:
/speckit.tasksDespués de la ejecución, la IA:
- Extrae el enfoque técnico de plan.md
- Extrae las prioridades de historias de usuario de spec.md
- Genera tareas agrupadas por historia de usuario
- Marca las tareas paralelizables con
[P] - Especifica rutas de archivo concretas para cada tarea
Formato de la lista de tareas:
## Phase 1: Setup
- [ ] T001 Crear estructura del proyecto
- [ ] T002 [P] Configurar esquema de Prisma
- [ ] T003 [P] Configurar NextAuth
## Phase 2: User Story 1 - Inicio de sesión (P1)
- [ ] T004 [US1] Crear modelo User en prisma/schema.prisma
- [ ] T005 [US1] Implementar API de inicio de sesión en src/app/api/auth/[...nextauth]/route.ts
- [ ] T006 [US1] Crear página de inicio de sesión en src/app/(auth)/login/page.tsxCada tarea incluye:
- ID de tarea (T001, T002...) — para seguimiento
- Marcador [P] — indica que puede ejecutarse en paralelo con otras tareas [P]
- Etiqueta [US] — indica a qué historia de usuario pertenece
- Ruta de archivo — especifica exactamente qué archivo se debe modificar
/speckit.implement — Ejecutar la implementación
Todo está listo — es hora de ejecutar la lista de tareas.
Propósito: Ejecutar las tareas de la lista una por una
Entrada: Documento tasks.md
Salida: Código real
Ejemplo de uso:
/speckit.implementAntes de la ejecución, la IA verifica la lista de verificación (si existe una). Durante la ejecución:
- Las tareas se ejecutan en orden de fase
- Cada tarea completada se marca como
[X] - Se respetan las dependencias entre tareas
- Las tareas paralelas pueden ejecutarse simultáneamente
Ejemplo de ejecución:
Phase 1: Setup
✓ T001 Crear estructura del proyecto
✓ T002 Configurar esquema de Prisma
✓ T003 Configurar NextAuth
Phase 2: User Story 1
✓ T004 Crear modelo User
Ejecutando T005...Revisión posterior a la implementación
Después de que /speckit.implement finalice, no fusione el código directamente. El código generado por IA requiere revisión humana:
Pasos de verificación obligatorios:
-
Ejecutar la suite de pruebas
npm test # o su comando de pruebasAsegúrese de que la IA no haya roto la funcionalidad existente.
-
Lista de verificación para revisión de código
- ¿El código coincide con la intención de la especificación (comparar con spec.md)?
- ¿Sigue el estilo de codificación del proyecto?
- ¿Existen posibles problemas de seguridad?
-
Pruebas de casos límite Pruebe manualmente los casos límite que la IA pueda haber pasado por alto:
- Manejo de valores nulos
- Entradas extremas
- Escenarios de concurrencia
- Rutas de error
-
Verificación de rendimiento Si hay operaciones de base de datos o llamadas a API involucradas, verifique si existen consultas N+1 y problemas de rendimiento similares.
Consejo: Incluso con una especificación exhaustiva, la IA aún puede desviarse en los detalles de implementación. La revisión no es una señal de desconfianza en el desarrollo dirigido por especificaciones — es parte de la disciplina de ingeniería.
/speckit.analyze — Análisis de consistencia
Este es un paso opcional de verificación de calidad que valida la consistencia entre la especificación, el plan y las tareas.
Propósito: Análisis de consistencia y calidad entre documentos
Entrada: spec.md, plan.md, tasks.md
Salida: Informe de análisis (no se modifica ningún archivo)
Ejemplo de uso:
/speckit.analyzeDespués de la ejecución, verifica:
- Si cada requisito tiene una tarea correspondiente
- Si las tareas cubren todas las historias de usuario
- Si la terminología es consistente
- Si hay omisiones o duplicaciones
Otros comandos (opcionales)
Además de los comandos principales descritos anteriormente, speckit proporciona varios comandos auxiliares. Estos no forman parte del flujo de trabajo principal, pero son útiles en escenarios específicos.
/speckit.constitution — Crear una constitución del proyecto
Se utiliza para definir los principios y estándares de desarrollo del proyecto. Ideal para proyectos de equipo para garantizar que todos los miembros sigan estándares de desarrollo unificados.
- Entrada: Preguntas y respuestas interactivas o principios proporcionados directamente
- Salida: Archivo de constitución del proyecto
.specify/constitution.md - Caso de uso: Inicialización de nuevos proyectos de equipo, unificación de estilo de código y decisiones de arquitectura
/speckit.checklist — Generar una lista de verificación de calidad
Genera una lista de verificación de calidad personalizada basada en la especificación de la funcionalidad, utilizada para asegurar la calidad antes de la implementación.
- Entrada: Documento spec.md
- Salida: Listas de verificación en el directorio
checklists/ - Caso de uso: Controles de calidad antes del lanzamiento de funcionalidades importantes, referencia para revisión de código
/speckit.taskstoissues — Convertir tareas en GitHub Issues
Convierte automáticamente las tareas de tasks.md en GitHub Issues para la colaboración en equipo y la asignación de tareas.
- Entrada: Documento tasks.md
- Salida: GitHub Issues (creados a través del CLI gh)
- Caso de uso: Colaboración en equipo, planificación de sprints, seguimiento de tareas
Ecosistema de herramientas
Los comandos speckit presentados en este artículo provienen del proyecto GitHub Spec Kit. Más allá de esto, en 2025, varias herramientas importantes de programación con IA comenzaron a soportar flujos de trabajo similares dirigidos por especificaciones:
| Herramienta | Características | Ideal para |
|---|---|---|
| GitHub Spec Kit | La herramienta utilizada en este artículo, licencia MIT, soporta Claude Code / Copilot / Gemini CLI | Usuarios de línea de comandos, colaboración entre herramientas |
| AWS Kiro | Fork de VS Code, flujo de trabajo visual, notación EARS | Usuarios orientados a GUI, ecosistema AWS |
| JetBrains Junie | Integración con el ecosistema IntelliJ, modo de razonamiento Think More | Usuarios de JetBrains IDE |
| Cursor Plan Mode | Fase de planificación integrada, planes de ejecución generados automáticamente | Desarrolladores que ya usan Cursor |
Cómo elegir:
- Si utiliza Claude Code, GitHub Copilot o Gemini CLI, se recomienda GitHub Spec Kit
- Si prefiere interfaces gráficas y flujos de trabajo visuales, pruebe AWS Kiro
- Si es usuario de JetBrains, Junie ofrece una integración más natural con el IDE
- Si ya está usando Cursor, su Plan Mode proporciona capacidades de planificación similares
La filosofía central es la misma — la herramienta es solo el vehículo; lo que importa es la mentalidad de primero la especificación, después el código.
Demostración de extremo a extremo
Recorramos un ejemplo del mundo real utilizando el flujo de trabajo completo de speckit.
Escenario: Agregar una funcionalidad de marcadores de artículos a un sistema de blog
Paso 1: Crear la especificación
/speckit.specify Quiero agregar una funcionalidad de marcadores para que los usuarios puedan guardar sus artículos favoritos y verlos en su perfilLa IA genera el documento de especificación specs/002-article-bookmark/spec.md:
# Feature Specification: Marcadores de artículos
## User Scenarios & Testing
### User Story 1 - Marcar un artículo (Priority: P1)
Mientras lee un artículo, el usuario hace clic en el botón de marcador para agregarlo a su lista de marcadores.
**Acceptance Scenarios**:
1. Given el usuario ha iniciado sesión, When hace clic en el botón de marcador, Then el artículo se agrega a la lista de marcadores
2. Given el usuario no ha iniciado sesión, When hace clic en el botón de marcador, Then se muestra un aviso de inicio de sesión
### User Story 2 - Ver lista de marcadores (Priority: P2)
El usuario visualiza todos sus artículos marcados en su perfil.
## Requirements
- FR-001: Los usuarios deben poder marcar/desmarcar artículos
- FR-002: El botón de marcador debe reflejar el estado actual
- FR-003: El perfil debe mostrar la lista de marcadores
## Success Criteria
- SC-001: Las operaciones de marcado se completan en menos de 500ms
- SC-002: La lista de marcadores soporta paginación con 10 artículos por páginaPaso 2: Aclarar requisitos
/speckit.clarifyLa IA pregunta: "¿Existe un límite superior en la cantidad de marcadores?"
Respuesta: "Un máximo de 100 artículos marcados por usuario"
La especificación se actualiza con:
- FR-004: Cada usuario puede marcar un máximo de 100 artículos
- Se muestra una notificación cuando se alcanza el límite
Paso 3: Generar el plan
/speckit.plan Usando Next.js + PrismaEl plan técnico generado incluye:
- Modelo Bookmark (userId, articleId, createdAt)
- Diseño de rutas de API (POST/DELETE /api/bookmarks)
- Diseño de componentes (BookmarkButton, BookmarkList)
Paso 4: Descomponer tareas
/speckit.tasksLa lista de tareas generada:
## Phase 1: Setup
- [ ] T001 Agregar modelo Bookmark al esquema de Prisma
## Phase 2: US1 - Marcar artículo
- [ ] T002 [US1] Crear API de marcadores en src/app/api/bookmarks/route.ts
- [ ] T003 [US1] Crear componente BookmarkButton en src/components/BookmarkButton.tsx
- [ ] T004 [US1] Integrar en la página de artículos
## Phase 3: US2 - Lista de marcadores
- [ ] T005 [US2] Crear página de lista de marcadores en src/app/profile/bookmarks/page.tsx
- [ ] T006 [US2] Implementar lógica de paginaciónPaso 5: Ejecutar la implementación
/speckit.implementLas tareas se ejecutan en orden y cada tarea completada se marca como [X].
Mejores prácticas y consideraciones
Cuándo usar Speckit
Escenarios adecuados:
- Desarrollo de nuevas funcionalidades (que involucren 3+ archivos)
- Cuando los requisitos no están completamente claros (use clarify para resolverlos)
- Proyectos colaborativos de múltiples personas (las especificaciones sirven como entendimiento compartido)
- Funcionalidades críticas (donde se necesita trazabilidad)
Escenarios no adecuados:
- Correcciones simples de errores
- Cambios de una sola línea de código
- Correcciones de emergencia
- Experimentos puramente exploratorios
Errores comunes
Hay varios errores comunes a los que debe prestar atención al usar speckit:
Error 1: Especificaciones demasiado vagas
Síntoma: El código generado por la IA difiere significativamente de las expectativas, requiriendo retrabajo extensivo.
# ❌ Especificación vaga
Los usuarios pueden buscar artículos
# ✓ Especificación clara
- FR-001: Los usuarios pueden buscar artículos por palabras clave del título
- FR-002: Los resultados de búsqueda se ordenan por relevancia, mostrando 10 por página
- FR-003: Los términos de búsqueda se resaltan en los resultados
- FR-004: Un término de búsqueda vacío muestra artículos popularesSolución: Ejecute /speckit.clarify, o agregue manualmente requisitos funcionales y criterios de éxito.
Error 2: Especificaciones demasiado detalladas
Síntoma: La IA está demasiado restringida y no puede aprovechar sus fortalezas, produciendo código rígido — o simplemente ignora partes de las instrucciones.
# ❌ Sobre-especificado (dictando detalles de implementación)
Usar la función debounce de lodash con un retraso de 300ms,
envuelto en useCallback con [searchTerm] como dependencia...
# ✓ Nivel de detalle apropiado (solo indicar qué, no cómo)
La entrada de búsqueda debe tener debounce para evitar solicitudes excesivasSolución: Mantenga las especificaciones en el nivel de "qué" y deje el "cómo" para la fase de Plan.
Error 3: Omitir la fase de Plan
Síntoma: Las tareas son demasiado generales o demasiado fragmentadas, lo que lleva a retrabajo frecuente durante la implementación y dependencias enredadas entre tareas.
Solución: Siempre complete la fase de Plan para funcionalidades complejas. La planificación no solo produce un enfoque técnico, sino que también ayuda a identificar posibles problemas de arquitectura.
Error 4: Fusionar sin revisión
Síntoma: Se descubren casos límite, vulnerabilidades de seguridad o problemas de rendimiento después del despliegue.
Solución: Consulte la sección "Revisión posterior a la implementación" anterior — siempre ejecute pruebas y realice revisión de código antes de fusionar.
Preguntas frecuentes
P: ¿Necesito seguir el flujo de trabajo completo para cada funcionalidad?
No necesariamente. Los cambios simples pueden ir directamente al código. Para funcionalidades complejas, se recomienda completar al menos specify + plan.
P: La especificación es muy detallada, pero la IA aún generó código inesperado.
Verifique si la especificación es verdaderamente "detallada". A menudo pensamos que hemos sido claros, pero quedan ambigüedades. Intente ejecutar /speckit.clarify para ver si se omitió algo.
P: ¿Puedo omitir ciertos pasos?
Sí. El flujo de trabajo mínimo es specify → tasks → implement. Sin embargo, omitir clarify y plan puede aumentar el riesgo de retrabajo posterior.
P: ¿Cómo modifico una especificación ya generada?
Simplemente edite el archivo spec.md directamente. Después de realizar cambios, se recomienda volver a ejecutar plan y tasks para mantener la consistencia.
P: El código generado por la IA es completamente incorrecto — ¿cómo lo depuro?
Investigue por etapas:
- Verificar la especificación: ¿La especificación es realmente clara? Intente ejecutar
/speckit.clarifypara ver si se omitió algo - Verificar el plan: ¿El enfoque técnico en plan.md es razonable? Si no lo es, edítelo directamente y regenere las tareas
- Reducir el alcance: Haga que la IA ejecute solo una tarea y observe si el resultado cumple con las expectativas
- Agregar restricciones: Agregue preferencias técnicas más explícitas en constitution.md
P: ¿Qué hago si el Plan y las Tareas son inconsistentes?
Ejecute /speckit.analyze para detectar inconsistencias. Causas comunes:
- El Plan se actualizó pero las Tareas no se regeneraron
- Las Tareas se editaron manualmente sin actualizar el Plan
- La especificación cambió pero solo se actualizaron algunos documentos
Solución: Tome spec.md como fuente de verdad y regenere plan.md y tasks.md en secuencia.
P: ¿Cómo manejo las dependencias entre funcionalidades?
Si la Funcionalidad B depende de la Funcionalidad A, hay dos enfoques:
- Fusionar especificaciones: Escriba A y B en el mismo spec.md para que la IA las planifique juntas
- Desarrollar por fases: Complete primero el flujo completo de la Funcionalidad A, luego comience el specify de la Funcionalidad B
No se recomienda desarrollar simultáneamente múltiples funcionalidades con dependencias, ya que esto fácilmente conduce a problemas de integración.
Resumen
El valor central de speckit no es agregar proceso por sí mismo — se trata de hacer explícito el conocimiento implícito. Cuando se le requiere escribir historias de usuario, requisitos funcionales y criterios de éxito, los detalles que usted pensaba que eran "obvios" salen a la superficie naturalmente.
Recuerde este flujo de trabajo:
Specify → Clarify → Plan → Tasks → Implement
Definir Refinar Diseñar Descomponer EjecutarCada paso reduce la ambigüedad para el siguiente. Al final, la IA recibe una lista de tareas clara en lugar de una descripción vaga de intenciones.
Ahora, regrese a su proyecto e intente iniciar su primer flujo de trabajo de desarrollo dirigido por especificaciones con /speckit.specify.
Lectura adicional
- Qué es el desarrollo dirigido por especificaciones — Revisar la filosofía central
- Análisis profundo de GSD — Otro sistema de ingeniería de contexto basado en principios de especificaciones
- Qué son los Claude Skills — Speckit en sí mismo es un Claude Skill
Comentarios
Introducción conceptual
Del Vibe Coding al desarrollo basado en especificaciones: comprenda cómo la programación con IA evoluciona de la 'intuición' a la 'ingeniería', y domine el nuevo paradigma de escribir especificaciones antes del código
Ralph Wiggum: Análisis en Profundidad
Comprender los principios fundamentales de la técnica Ralph — por qué un simple bucle bash puede hacer que la IA escriba código mientras usted duerme