Análisis en profundidad de Skill-Creator: utilice datos para impulsar el desarrollo de sus habilidades
Un análisis en profundidad del Skill-Creator de "metahabilidades" oficial de Anthropic: cómo crear, probar, evaluar y optimizar sistemáticamente las habilidades de Claude Code, transformando el desarrollo de habilidades de la intuición a los datos.
Introducción
Este artículo está basado en información de marzo de 2026 y corresponde a Claude Code v2.1+.
Si ha leído Concepto y Práctica, ya debería saber cómo escribir manualmente un archivo SKILL.md: defina frontmatter, escriba un comando, guárdelo en el directorio .claude/skills/ y listo.
Pero aquí hay una pregunta fundamental: **¿Cómo sabes que tus habilidades son realmente útiles? **
Es posible que haya cambiado la redacción de un párrafo y sienta que funciona mejor, pero ese es sólo su sentimiento subjetivo. Quizás con una palabra clave diferente, la nueva versión sería peor. Tal vez tus habilidades no mejoren en absoluto en comparación con no tener habilidades: Claude puede hacerlo igual de bien por sí solo.
En los capítulos conceptual y práctico, el proceso de desarrollo de habilidades es el siguiente: Escrito → Probado → Sentirse bien → En línea. Todo el proceso se basa en la intuición, no hay cuantificación y no hay forma de responder "¿Cuánto mejor es esta habilidad que ninguna habilidad en absoluto?" Y Skill-Creator convirtió esto en ingeniería: Escrito → Pruebas paralelas con/sin habilidades → Comparación de prueba ciega A/B → Puntuación cuantitativa → Iteración de retroalimentación → Verificación de datos.
The skill-creator turns skill creation from art into engineering — you can now test, measure, and systematically improve your skills instead of relying on intuition alone.
Por eso existe Skill-Creator. No solo le ayuda a "generar un SKILL.md", sino que también proporciona un conjunto completo de bucles crear → probar → evaluar → optimizar, lo que le permite dejar que sus datos hablen por sí mismos.
¿Qué es Skill-Creator?
La "metahabilidad" proporcionada oficialmente por Anthropic: una habilidad utilizada específicamente para crear, probar y optimizar otras habilidades . Tiene un marco de evaluación incorporado, comparación de pruebas ciegas, optimización de descripciones y otras capacidades, lo que mejora el desarrollo de habilidades de "escríbalo y pruébelo" a "ingeniería iterativa basada en datos".
Improving skill-creator: Test, measure, and refine Agent Skills
The official blog post announcing skill-creator improvements with eval, improve, and benchmark capabilities.
Skill-Creator en sí también es una habilidad: un archivo SKILL.md de 33 KB que además admite archivos de guía de subagente, secuencias de comandos Python y visores HTML. Su estructura de directorios se ve así:
skill-creator/
├── SKILL.md # 主指令文件(486 行)
├── agents/ # 子代理指导
│ ├── grader.md # 评分代理
│ ├── comparator.md # 盲测对比代理
│ └── analyzer.md # 分析代理
├── eval-viewer/ # 评估结果查看器
│ ├── generate_review.py
│ └── viewer.html
├── assets/
│ └── eval_review.html # 触发评估审查界面
├── scripts/ # Python 工具脚本
│ ├── run_eval.py # 运行触发评估
│ ├── run_loop.py # 优化循环
│ ├── improve_description.py # 描述优化
│ ├── aggregate_benchmark.py # 聚合基准测试
│ ├── package_skill.py # 打包为 .skill 文件
│ └── quick_validate.py # 快速校验
└── references/
└── schemas.md # JSON Schema 定义La instalación también es muy sencilla:
# 通过 Claude Code 插件市场
/plugins # 然后搜索 skill-creator 安装
# 或通过 skills.sh
npx skills add anthropics/skills -- skill skill-creatorSiga esto nuevamente: Evaluar y optimizar una habilidad existente
Repasemos el proceso completo de Skill-Creator usando las habilidades que realmente uso. Mantengo un mercado de complementos de Claude Code yux-claude-hub, en el que la habilidad yux-video-summary se usa para convertir subtítulos de video en resúmenes estructurados, lo que admite detección de idiomas chino e inglés, dos modos de salida DUAL_FILE/SINGLE_FILE, limpieza de palabras de relleno, etc. El SKILL.md de la habilidad tiene este aspecto:
---
name: yux-video-summary
description: Transform a video transcript file into a structured,
organized summary with key points, timeline, and cleaned transcript.
Use when the user has a transcript file and wants it summarized.
allowed-tools: Read, Write, Glob, Grep
---La habilidad ha sido escrita, pero ¿cómo sabes que es realmente útil? ** Aquí es donde Skill-Creator entra en escena.
Hay un principio de escritura importante en el código fuente de Skill-Creator: "Intenta explicar el por qué detrás de todo. Si te encuentras escribiendo SIEMPRE o NUNCA en mayúsculas, eso es una señal de alerta: reformula y explica el razonamiento". Significado: una buena habilidad debe explicar el por qué, en lugar de acumular reglas rígidas.
Paso 1: crear casos de prueba y ejecutar la evaluación
Pregunta central: **¿Es esta habilidad realmente mejor que ninguna habilidad? **
Abra Claude Code e ingrese directamente:
Use the skill creator to create evals for the yux-video-summary skillSkill-Creator primero leerá definiciones y esquemas de habilidades y luego generará automáticamente casos de prueba y afirmaciones cuantitativas. Mi ejecución generó 3 casos de prueba y 39 afirmaciones:

Tenga en cuenta que no compila casos de prueba de manera casual: comprende los dos modos de salida de DUAL_FILE y SINGLE_FILE definidos en la habilidad y diseña específicamente escenarios que cubren diferentes tipos de videos (tutoriales, entrevistas de podcasts, intercambio de tecnología) y combinaciones de idiomas. El diseño de Assertions también es muy particular, desde la detección de idioma, la selección del modo de salida hasta la calidad del contenido y la limpieza de palabras de relleno en chino e inglés, es mucho más completo de lo que quiero probar las dimensiones yo mismo.
En el contexto de Skill-Creator, Eval se refiere a la prueba sistemática de las habilidades . Cada evaluación contiene un mensaje de prueba (mensaje), una descripción del resultado esperado y afirmaciones cuantitativas (afirmaciones). El sistema ejecutará las versiones especializada y no especializada al mismo tiempo y luego comparará los resultados.
Luego, el sistema inicia dos subagentes independientes simultáneamente para cada caso de prueba: with_skill (cargando habilidades) y ** without_skill ** (línea base, no se cargan habilidades). Se iniciaron 6 agentes paralelos (3 casos de prueba × 2 versiones) al mismo tiempo, cada uno ejecutándose en un árbol de trabajo independiente sin interferir entre sí.
La habilidad PDF de Anthropic anteriormente tenía problemas para manejar formularios que no se pueden completar: Claude necesitaba colocar texto en coordenadas precisas sin definir campos. El punto de falla se aisló mediante Eval y posteriormente el equipo arregló la lógica de posicionamiento. Ese es el valor de Eval: convertir "algo que no se siente bien" en "qué es exactamente lo que está mal aquí".
Paso 2: tres subagentes retransmiten la puntuación
Una vez completadas todas las operaciones, los tres subagentes profesionales automáticamente aparecen en secuencia:
Calificador Verifica las afirmaciones una por una. Verificará si el resumen de la versión with_skill contiene la tabla de descripción general, si el modo DUAL_FILE está seleccionado correctamente, si la palabra de relleno se ha limpiado y luego registrará el aprobado/reprobado y la evidencia de cada elemento, generando grading.json:
{
"expectations": [
{ "text": "摘要包含 Overview 表格", "passed": true, "evidence": "Found overview table with Type, Duration, Language fields" },
{ "text": "正确选择 DUAL_FILE 模式", "passed": true, "evidence": "Generated separate summary and transcript files" },
{ "text": "filler 词已清理", "passed": false, "evidence": "Found 'you know' in transcript line 42" }
],
"summary": { "passed": 2, "failed": 1, "total": 3, "pass_rate": 0.67 }
}Comparador hace una comparación ciega A/B: recibe dos resúmenes, pero no sabe cuál es la versión de habilidad y cuál es la versión básica. Solo ve la "Salida A" y la "Salida B" y las juzga de forma independiente según sus propios estándares de calidad para determinar el ganador.
Cuando el subagente Comparador compara dos salidas, no sabe cuál es de la versión de habilidad y cuál es de la versión base . Solo ve la "Salida A" y la "Salida B" y las juzga de forma independiente en función de los estándares de calidad que genera, lo que finalmente determina un ganador o un empate. Este diseño elimina el sesgo de evaluación.
Analizador combina los resultados anteriores para hacer un diagnóstico: qué afirmaciones pasaron independientemente de las habilidades o no (lo que indica que esta afirmación no tiene diferenciación y debe ser reemplazada por una mejor afirmación), qué resultados tienen una alta variación (la prueba es inestable) y cuál es la compensación entre tiempo y token. Finalmente, se dan sugerencias de mejora.
Paso 3: Revisar los resultados en Eval Viewer
Una vez que se completa la puntuación, Skill-Creator abrirá automáticamente un visor HTML en su navegador.
Pestaña Resultados Puede ver el resultado de cada caso de prueba uno por uno. Hay un cuadro de texto de comentarios en la parte inferior: escriba lo que crea que no es lo suficientemente bueno, como "el resumen carece de una línea de tiempo" y "la palabra de relleno no está limpia". Después de leer todos los casos de uso, haga clic en Enviar todas las reseñas y los comentarios se guardarán en feedback.json.
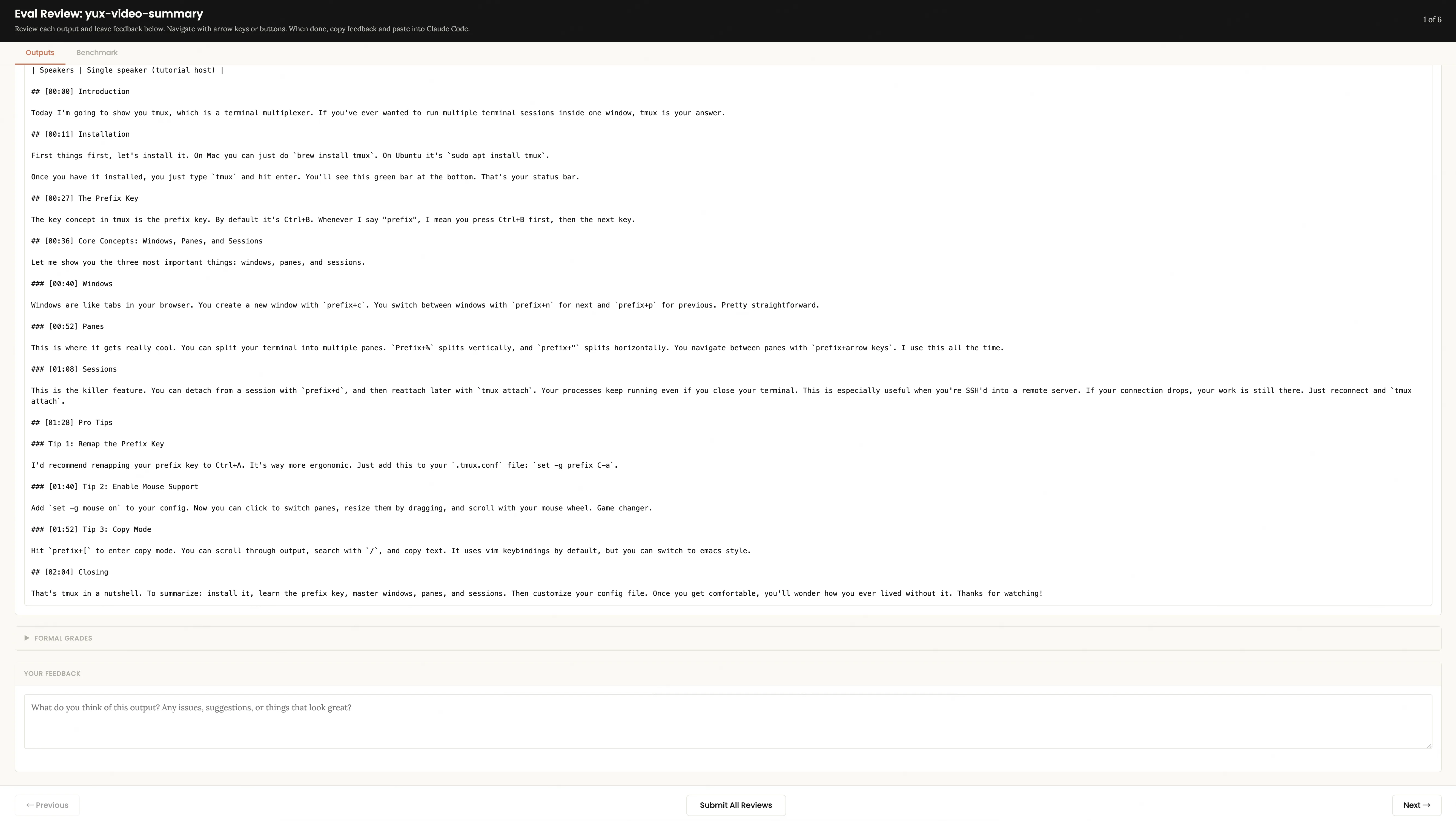
Pestaña Resultados de referencia Puede ver la comparación cuantitativa: la tasa de aprobación, el consumo de tiempo, el consumo de tokens de with_skill y without_skill, así como la comparación elemento por elemento de cada afirmación.
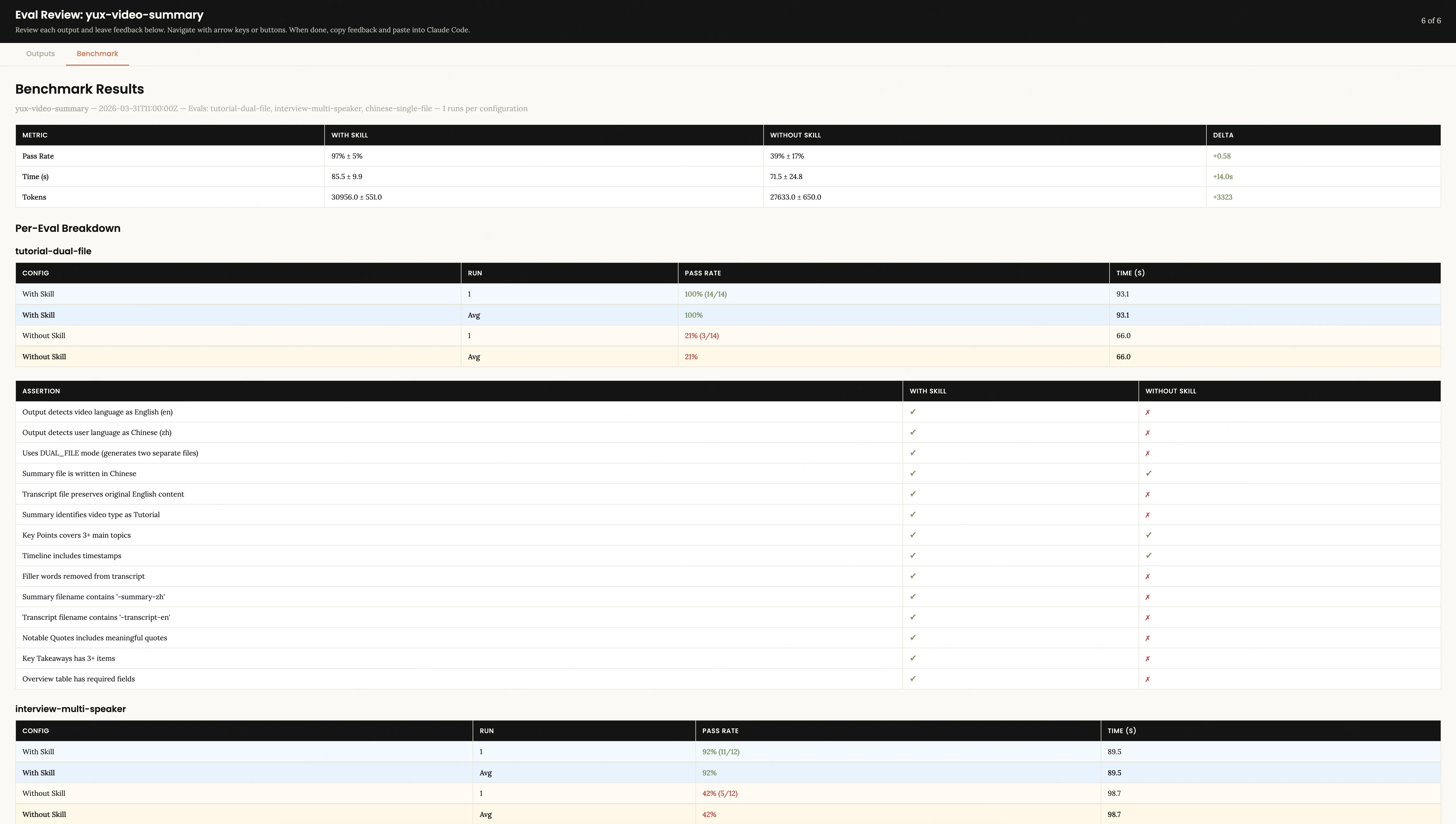
Paso 4: Iterar y mejorar hasta estar satisfecho
Vuelva a Claude Code y dígale que ha terminado de enviar comentarios. Skill-Creator leerá feedback.json y brindará análisis y sugerencias de mejora basadas en los datos de referencia:

Mi habilidad funcionó bien con una tasa de aprobación del 97%. Skill-Creator identificó con precisión un pequeño problema: el video de la entrevista carecía de párrafos de Citas notables e hizo sugerencias para solucionarlo.
La clave es que no parchea casos de prueba individuales: generaliza sus comentarios, comprende los requisitos detrás de ellos y ajusta la estructura general de la habilidad, luego reescribe SKILL.md, vuelve a ejecutar todas las pruebas en el directorio iteration-2/ y abre un nuevo Visor de evaluación para que pueda comparar el resultado de las dos rondas. Este ciclo continúa hasta que esté satisfecho.
Una filosofía de mejora notable en el código fuente de Skill-Creator: "Estamos tratando de crear habilidades que se puedan usar un millón de veces en muchos mensajes diferentes. En lugar de realizar cambios complicados y excesivos o DEBE opresivamente restrictivos, si hay algún problema persistente, intente diversificarse y usar diferentes metáforas". Idea central: Evitar el sobreajuste para probar casos y buscar capacidades de generalización.
Paso 5 (opcional): Optimice la descripción para que la habilidad se active en el momento adecuado
Se verifica la calidad de la habilidad, pero hay otra cuestión que fácilmente se pasa por alto: el campo description de la habilidad determina cuándo Claude la llamará.
Entrada:
Use the skill creator to optimize the description for yux-video-summarySkill-Creator genera automáticamente alrededor de 20 consultas de evaluación (la mitad debe activarse, la otra mitad no debe activarse) y la interfaz de revisión se abre en el navegador:
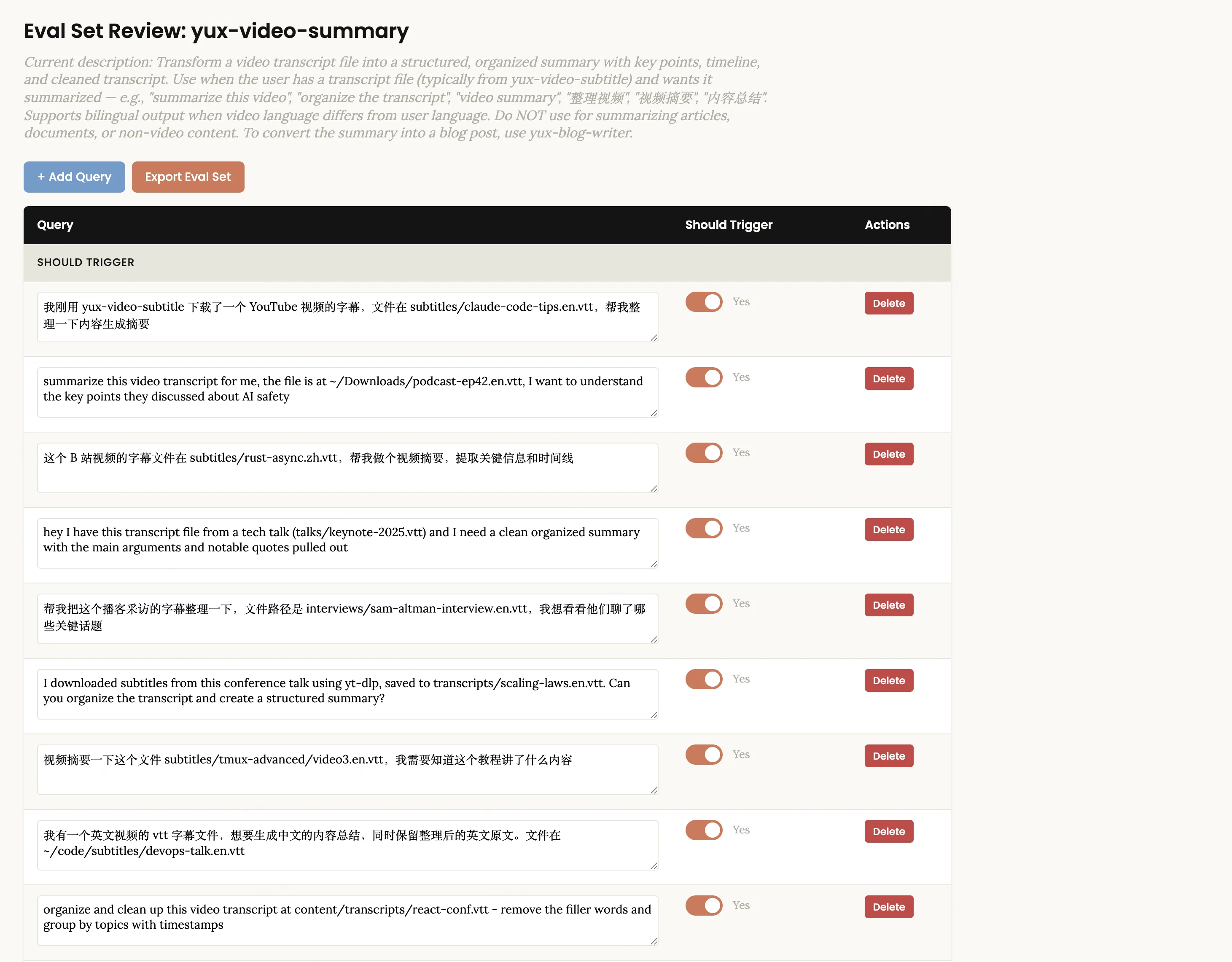
Tenga en cuenta que estas consultas están disponibles tanto en chino como en inglés y cubren una variedad de expresiones reales. Las consultas "No deberían activar" no deberían ser demasiado escandalosas; un buen contraejemplo es "Ayúdame a resumir las actas de esta reunión", que comparte la palabra clave "resumen" con el resumen en video, pero en realidad requiere habilidades de procesamiento de documentos en lugar de resumen en video.
Puede editar el texto de la consulta directamente en la página, hacer clic en + Agregar consulta para agregar nuevas consultas, usar el botón Eliminar para eliminar las inapropiadas y también puede alternar el interruptor Debería activar para cada consulta. Después de confirmar que es correcto, haga clic en Exportar conjunto de evaluación para exportar el archivo JSON. Vuelve a Claude Code y dile que lo has exportado. El sistema ejecutará automáticamente el ciclo de optimización en segundo plano:

Todo el proceso está completamente automatizado: divida la consulta en un conjunto de entrenamiento y un conjunto de prueba 60/40, optimice iterativamente la descripción en el conjunto de entrenamiento (hasta 5 rondas) y use los resultados del conjunto de prueba para seleccionar la mejor versión para evitar el sobreajuste. Después de ejecutar, se generará la comparación de descripciones antes y después de la optimización:

La descripción optimizada se vuelve más específica: aclara los tipos de archivos admitidos (.vtt/.srt), enfatiza las características de la canalización (limpieza de relleno, lógica DUAL/SINGLE_FILE) y utiliza MUST USE para excluir escenarios que no deberían activarse. Anthropic utilizó internamente este conjunto de optimizadores para ejecutar sus propias habilidades de creación de documentos. Como resultado, se mejoró la precisión de activación de 5 de 6 habilidades públicas.
Uso avanzado: inyección de contexto dinámico
Si desea que la habilidad inyecte contexto automáticamente al cargar, puede incrustar un comando de shell en SKILL.md usando la sintaxis ! de Skills 2.0:
## Project Context
File tree: !`find . -type f -not -path '*/node_modules/*' | head -50`
Package info: !`cat package.json 2>/dev/null || echo "No package.json"`
Recent commits: !`git log --oneline -10`Estos comandos se ejecutan antes de que Claude vea la habilidad y los datos se incrustan directamente en el mensaje. En comparación con dejar que Claude explore los archivos uno por uno, ahorra mucho tiempo y tokens.
Dos tipos de habilidades: ¿Cuál deberías crear?
Antes de utilizar Skill-Creator, es necesario comprender los dos tipos de habilidades definidos por Anthropic:
Tipo de mejora de habilidad: deja que el modelo haga cosas que antes no podía o no podía hacer bien. Por ejemplo:
- Habilidades de generación de imágenes: Claude no puede generar imágenes de forma nativa, pero puede lograrlo llamando a herramientas como nanobanner a través de habilidades.
- Habilidades de diseño front-end: los diseños de IA predeterminados suelen tener mucho "sabor a IA" y unas buenas habilidades de diseño pueden mejorar considerablemente la calidad.
Preferencia de codificación: solidifique su flujo de trabajo específico. El modelo ya tiene capacidades individuales, pero necesita un orden preciso de ejecución. Por ejemplo:
- Habilidades de revisión de relaciones públicas: verificar la seguridad del código de acuerdo con procedimientos fijos y generar informes de nivel de riesgo.
- Habilidades de resumen de vídeo: salida según una estructura de plantilla específica, detección automática de idioma y limpieza de palabras de relleno
Las razones por las que es necesario probar estos dos tipos de habilidades son diferentes: Tipo de mejora de capacidad puede volverse innecesario a medida que el modelo evoluciona: si la línea base (sin_skill) también puede pasar todas las afirmaciones, significa que el modelo es lo suficientemente nativo y esta habilidad se puede retirar; El tipo de codificación es más duradero, pero debes verificar si es realmente fiel a tu flujo de trabajo.
Las capacidades de evaluación de Skill-Creator le permiten verificar continuamente si una habilidad sigue siendo valiosa, en lugar de utilizar ciegamente una habilidad que puede estar desactualizada.
Lo que dice la comunidad
La actualización de Skill-Creator generó mucha discusión, desde X/Twitter hasta Reddit y blogs independientes, y los comentarios reales son más valiosos que la documentación oficial.
¿Es realmente útil? Los datos hablan
La pregunta más directa: ¿Es realmente mejor agregar habilidades que no agregar habilidades? ** Varias mediciones reales dan una respuesta clara.
Reddit u/hashpanak realizó una evaluación de la habilidad de generación de títulos y obtuvo una tasa de aprobación del 100 % con_skill y solo del 60 % sin_skill. Cuando se le preguntó si el costo del token valía la pena, respondió: "Por supuesto. Después de la optimización, las tareas repetidas se pueden convertir en scripts, lo que ahorrará tokens". u/spences10 es aún más extremo: ejecutó 250 evaluaciones de sandbox y aumentó la tasa de activación de habilidades del 84 % al 100 %. La sección de comentarios u/Manfluencer10kultra dijo: "Esto debería convertirse en una práctica estándar."
El blogger Nathan Onn comparó las habilidades de seguridad de WordPress: se aprobaron las 21 afirmaciones (la línea de base fue solo el 90,5%) y la velocidad fue un 9,9% más rápida. Su resumen: "Las habilidades solían ser arte, ahora son ingeniería".
@0zhuxiaofeng dio cifras más específicas desde la perspectiva del flujo de trabajo real: "Después de usarlo durante un mes, el mayor cambio es que run_eval permite que las habilidades se califiquen por sí mismas. El agente que ejecuto las operaciones de contenido ahora evalúa automáticamente el efecto después de cada lanzamiento, y las habilidades deficientes se eliminan y reescriben directamente. La intervención manual se ha reducido de 3 horas por día a media hora".
Punto ciego pasado por alto: Activador ≠ Calidad
El blogger Mager señaló un punto ciego que nadie mencionó: Las habilidades pueden pasar la evaluación de calidad pero fallan en la evaluación desencadenante: la calidad del resultado es muy buena, pero nunca será calificada. Después de tres rondas de optimización run_loop.py, activó la evaluación al 13/13. Información básica: "La descripción de una habilidad no son metadatos, sino un parámetro que se puede aprender; es necesario optimizar el comportamiento de enrutamiento real".
Esto coincide con la sugerencia de @DrWang5257: "No reescriba todo de una vez. Primero divídalo en tres secciones: condiciones de activación, plantillas de entrada y respaldo de fallas, e itere paso a paso. De esta manera, la velocidad de actualización es rápida y la tasa de renovación es baja".
Puntos débiles reales
Aunque el efecto es bueno, también existen muchos inconvenientes:
- el consumo de tokens es enorme. @konghao10 dijo sin rodeos que "el consumo de tokens es enorme": ejecutar 6 agentes paralelos al mismo tiempo no es realmente barato. Reddit u/munkymead también dijo que "es caro hacerse una prueba seria".
- Si tienes demasiadas habilidades, pelearás. El blogger de RoboRhythms, Noah Albert descubrió que empezar a tener problemas cuando las habilidades alcanzan 8-10: Claude se autocuestionará el resultado, generará prefacios más detallados y ocasionalmente tendrá conflictos de comando entre habilidades. Sin embargo, Reddit u/Specialist_Solid523 respondió: "Las habilidades mal escritas solo consumen contexto. Las habilidades bien escritas casi siempre hacen que el uso de tokens sea más eficiente."
- SKILL.md se alarga con más iteraciones. Reddit u/IulianHI señaló una contradicción: con mejoras iterativas, los archivos de habilidades continúan expandiéndose, ** pero desplazan la ventana de contexto para hacer las cosas realmente **. Los casos de prueba que solo cubren el camino feliz no alcanzan el 5% crítico.
- Falta la gestión de versiones. @fengqve se queja "¿Por qué Skill no tiene el concepto de versión? Se ha actualizado tantas veces que es difícil describir qué actualización es". Esto es especialmente doloroso después de múltiples rondas de iteraciones.
- El modo sin cabeza tiene un error. Hay un problema clave en GitHub: la habilidad nunca se activa en el modo
claude -p, lo que hace que la recuperación que describe el ciclo de optimización sea siempre del 0% (#36570).
Pensando más allá: superación personal recursiva
@vista8 compartió un artículo relacionado [Memento-Skills: Let Agents Design Agents] (https://github.com/Memento-Teams/Memento-Skills), y alguien en el área de comentarios lo resumió con precisión: "El principal cuello de botella de Skill es la iteración: es fácil escribir la primera versión, pero es difícil mejorarla y usarla mejor en escenarios reales. Si puedes automatizar este ciclo de 'usar → evaluar → mejorar', es equivalente a instalar un motor de autoevolución para Agent".
Un hilo similar al 104 en Reddit r/ClaudeAI también analiza esta dirección. Pero el comentario principal le echó agua fría: u/Tatrions dijo: "El bucle recursivo funciona, pero la parte difícil es saber cuándo confiar en las mejoras. Descubrimos que tenemos que buscar evidencia: no realizar cambios a menos que ocurra una falla al menos dos veces. De lo contrario, cada ciclo está 'arreglando' algo que no está roto en primer lugar, y termina siendo peor".
Instalación y Ecología
Skill-Creator, como una de las habilidades mantenidas oficialmente por Anthropic, está incluido en el almacén anthropics/skills, que contiene más de 17 habilidades de nivel de producción.
El ecosistema de habilidades más amplio también está creciendo rápidamente: skills.sh El mercado ofrece una experiencia conveniente de descubrimiento e instalación, y la comunidad ha mantenido más de 1234 habilidades de agentes.
The Complete Guide to Building Skills for Claude
A comprehensive 33-page guide covering skill fundamentals, planning, testing, distribution, and YAML frontmatter reference.
Claude Code Agent Skills 2.0: From Custom Instructions to Programmable Agents
A deep dive into Skills 2.0 architecture, context forking, and the programmable agent paradigm.
Escribe al final
El problema central que resuelve Skill-Creator es: **¿Cómo sabes que tus habilidades son realmente efectivas? **
En ausencia de ello, el desarrollo de habilidades se basa en "escribir → intentar → sentirse bien". Con Skill-Creator puedes:
- Prueba efectos tanto para expertos como para no expertos con Parallel Agent
- Elimine el sesgo de evaluación con Comparación ciega A/B
- Visualice resultados y deje comentarios con Eval Viewer
- Utilice Optimizador de descripciones para controlar con precisión el tiempo de activación de las habilidades.
- Utilice bucles iterativos para mejorar continuamente hasta que esté satisfecho
Esto está en línea con el concepto de desarrollo basado en pruebas en ingeniería de software: no "simplemente escribir el código y pensar que se puede ejecutar", sino "utilizar pruebas para demostrar que realmente funciona como se espera".
Anthropic presentó una perspectiva interesante en el blog oficial: a medida que las capacidades del modelo mejoran, SKILL.md puede evolucionar de un "plan de implementación" (decirle a Claude cómo) a una "descripción de la especificación" (decirle a Claude qué y dejar que el modelo lo resuelva por sí solo). El marco Eval es el primer paso en esta dirección: Eval describe "qué hacer". Si algún día esta descripción es suficiente para convertirse en una habilidad, entonces el sistema de prueba establecido por Skill-Creator será aún más importante.
Si ya utiliza Habilidades, intente usar /skill-creator para realizar una evaluación de sus habilidades más utilizadas. Es posible que se sorprenda al descubrir que algunas habilidades en realidad no son mejores que ninguna habilidad, y ahí es donde comienza la optimización.
Extend Claude with skills
Official documentation for Claude Code Skills — structure, frontmatter fields, and best practices.
Lectura relacionada:
- Qué son las Habilidades de Claude — Comprender los principios básicos de las Habilidades
- Guía Práctica — Crea tu primera Skill
Comentarios
Guía práctica
Cree Skills personalizados desde cero — compare las diferencias con MCP, Subagents, domine las mejores prácticas para habilitar, instalar y crear Skills
Introducción al Concepto
Comprensión profunda del mecanismo de plugins de Claude Code: cómo empaquetar y distribuir flujos de trabajo mediante Plugins para colaboración en equipo y uso compartido en la comunidad