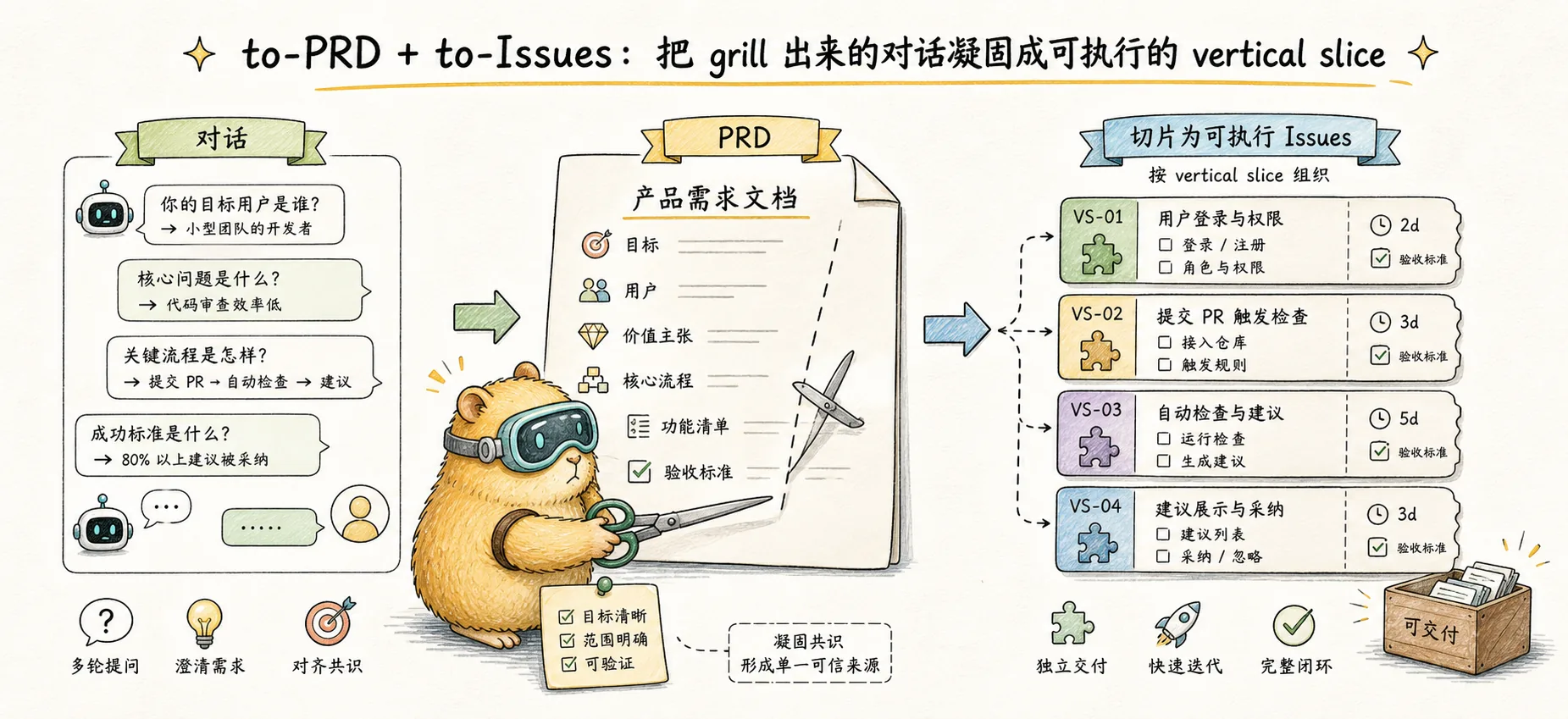
to-PRD + to-Issues:把 grill 出来的对话凝固成可执行的 vertical slice
Matt Pocock 工作流的中段——/to-prd 把对话变 PRD,/to-issues 把 PRD 切成可独立领取的纵向切片 issue。深入解读「tracer bullet」「vertical slice」这两个老概念在 AI 时代的新作用
每个 issue 都是一条贯穿所有集成层的端到端纵向切片,而不是某一层的横向切片。
这一段在工作流里的位置
回到 Matt 的工作流图:
/grill-me 或 /grill-with-docs ← 谈清楚
↓
/to-prd ← 凝固成 PRD(你在这里)
↓
/to-issues ← 切成可领取的 vertical slice(你在这里)
↓
/tdd ← 一个 slice 一个 slice 跑红绿
↓
/improve-codebase-architecture/to-prd 和 /to-issues 是承上启下的一段:把抽象的对话决策翻译成可执行的工作单元。我把它们合并讲,因为在 Matt 的实际使用里它们就是连续两步。
失败模式:grill 完之后没事干
不少人用完 /grill-me 后会卡住:拿到一段长长的对话,里面有一堆决策,但怎么开始写代码?
直接喂给 Claude「请实现」是错的——因为:
- 一次实现完整功能 = AI 输出 1000+ 行 = 很难 review、很难测、bug 难定位
- AI 失忆后下一个 session 没有上下文
- 没有 tracking——没法知道做到哪、还剩多少
正确做法是把决策冻结成 artifact(PRD),再把 PRD 切成小到可独立完成的工作包(issues)。这是软件工程 30 年的常识,但在 AI 时代有了新意义:
切得够细,才能让 AFK agent(你不在场时跑的 agent)独立领取并完成。
/to-prd:把对话压缩成 PRD
Skill 的关键约束
/to-prd 的 SKILL.md 开头写了一句很重要的话:
"This skill takes the current conversation context and codebase understanding and produces a PRD. Do NOT interview the user — just synthesize what you already know."
不再问问题。这是 grill-me 阶段做的事,to-prd 只做合成。所以不要清 context 再跑 to-prd——它依赖前面 grill 出来的全部对话。
Skill 的处理流程
- 探索代码库(如果还没探过)—— 用项目的 CONTEXT.md 词汇,尊重已有 ADR
- 草拟模块—— 主动找可以提取为 deep module 的机会,让接口可独立测
- 和用户对齐模块—— 「这些模块对吗?哪些要写测试?」
- 按模板生成 PRD,发到 issue tracker,打
needs-triage标签
PRD 模板
Matt 给的模板是这样:
## Problem Statement
The problem that the user is facing, from the user's perspective.
## Solution
The solution to the problem, from the user's perspective.
## User Stories
A LONG, numbered list:
1. As a <actor>, I want a <feature>, so that <benefit>
2. ...
## Implementation Decisions
- The modules that will be built/modified
- The interfaces of those modules
- Technical clarifications from the developer
- Architectural decisions
- Schema changes / API contracts / Specific interactions
(NO specific file paths or code snippets — they rot fast.)
## Testing Decisions
- What makes a good test (test external behavior, not internals)
- Which modules will be tested
- Prior art (similar tests in the codebase)
## Out of Scope
What's NOT in this PRD.
## Further Notes几个关键设计:
- User Stories 占大头:要求 LONG, numbered list——逼你穷举完整的功能点。这避免了「我以为说清楚了」的盲点
- Implementation 不写文件路径或代码:Matt 直接说 "they may end up being outdated very quickly"。这是 LLM 时代特有的考量——具体路径在重构后立刻过时,但「模块边界」「接口契约」生命周期更长
- 必须有 Out of Scope:这个段落在大多数 PRD 模板里被忽略,但它是后续切 issue 时的边界保险
/to-issues:把 PRD 切成 vertical slice
Vertical Slice 是什么
这是 Matt 整套方法论里最重要的概念之一。SKILL.md 直接说:
Each issue is a thin vertical slice cutting through ALL integration layers end-to-end, NOT a horizontal slice of one layer.
举例最清楚:要做「评论功能」。
横向切片(错的方式):
- Issue 1: 数据库 schema
- Issue 2: API 端点
- Issue 3: UI 组件
- Issue 4: 测试
纵向切片(Tracer Bullet 方式):
- Issue 1: 「访客可以提交一条匿名评论」(schema + API + UI + test 全在内,但范围小到只能匿名)
- Issue 2: 「登录用户的评论关联到账户」
- Issue 3: 「评论可以被回复」
- Issue 4: 「管理员可以删除评论」
横向切片的问题:每个切片单独验不了。Issue 1 完成后没有可演示的东西,要等到 Issue 4 才能跑通整个链路——直到那时才发现 schema 设计错了。
纵向切片每完成一个就是端到端可用的功能子集——用 Pragmatic Programmer 里的话叫 tracer bullet(曳光弹),一发先打过去看准星,再调整下一发。
HITL vs AFK
/to-issues 还会给每个 slice 标一个标签:
- HITL(Human in the Loop)—— 需要人参与决策。比如架构决策、设计审查
- AFK(Away From Keyboard)—— agent 可以独立做完,你回来看结果
"Prefer AFK over HITL where possible."(能 AFK 就别 HITL)
这是 Matt 的工作流里一个很激进的设想:你切完 issue,直接派给跑在你不在场时的 agent(比如夜里、周末),第二天回来 PR 已经躺在那等 review 了。HITL 的部分留在白天和 agent 配合干。
切片确认环节
/to-issues 不会一上来就生成 issue——它会先把切片方案以编号列表的方式给你看:
1. Title: 访客提交匿名评论
Type: AFK
Blocked by: None
User stories covered: #1, #2
2. Title: 评论关联到登录账户
Type: AFK
Blocked by: #1
User stories covered: #3
3. Title: 评论审核流程
Type: HITL(需要确认审核 UI 设计)
Blocked by: #1
User stories covered: #4, #5然后问你:
- 粒度对吗?太粗 / 太细?
- 依赖关系对吗?
- 哪些应该合并 / 拆分?
- HITL/AFK 标对了吗?
迭代到你点头之后才真正发到 issue tracker,按依赖顺序发(先发 blocker),这样后发的 issue 可以引用先发的真实 issue ID。
Issue 模板
## Parent
A reference to the parent issue (if any).
## What to build
A concise description. Describe end-to-end behavior, NOT layer-by-layer
implementation.
## Acceptance criteria
- [ ] Criterion 1
- [ ] Criterion 2
- [ ] Criterion 3
## Blocked by
- A reference to the blocking ticket
(or "None - can start immediately")注意 "describe end-to-end behavior" 这条——和 vertical slice 的精神一致。Acceptance criteria 是验收清单,Claude 在 /tdd 阶段会逐条转成测试。
怎么用:完整流程示例
假设你要给博客加评论功能。完整流程:
你: 我想给博客加评论功能
↓
/grill-me → Claude 问 30 个问题(要不要登录?匿名?嵌套?审核?……)
↓
你回答完毕,达成共识
↓
/to-prd → Claude 生成结构化 PRD,提交到 GitHub Issues #42
↓
/to-issues → Claude 提议切成 4 个 vertical slice
让你确认粒度和依赖
你点头
按依赖顺序发布到 GitHub Issues #43~#46
↓
你回家睡觉
↓
夜里 AFK agent 抓 #43(无依赖),跑 /tdd 完成 → 提 PR
你早上 review、merge
↓
agent 抓 #44 / #45 ……整套流程不需要你坐在屏幕前看着每个细节,关键决策都在 grill-me 阶段做完了。
安装与前置条件
npx skills@latest add mattpocock/skills勾选 to-prd、to-issues、setup-matt-pocock-skills。
必须先跑 /setup-matt-pocock-skills——它会把你的 issue tracker(GitHub / GitLab / 本地 markdown)和 triage label 词汇写到 AGENTS.md/CLAUDE.md,否则 to-prd 和 to-issues 不知道往哪发 issue。
支持的 issue tracker:
- GitHub Issues(默认,用
ghCLI) - GitLab Issues(用
glabCLI) - 本地 markdown(在
.scratch/<feature>/下创建文件)—— 适合个人项目或没有远程的项目 - 其他(Jira、Linear 等)—— 用一段 prose 描述工作流,skill 会按你的描述调用
常见问题
Q: 已经有现成 PRD 了,能跳过 to-prd 直接 to-issues 吗?
A: 可以。/to-issues 接受 issue 引用作为参数("Break down issue #42 into vertical slices"),它会去 fetch issue 内容再切。
Q: 我的项目没用 issue tracker,能用吗?
A: 能。setup 时选「本地 markdown」,所有 issue 会变成 .scratch/<feature>/001-foo.md 这样的本地文件。
Q: PRD 太长,AI 自己也搞不定怎么办? A: 这是切片粒度的信号——PRD 应该被切成多个独立 PRD 而不是一个巨型 PRD。在 grill 阶段就该感觉到:如果聊到第 50 个问题还在引入新功能,先停下来切成两个 PRD 分批做。
Q: AFK agent 怎么自动抓 issue?
A: 这部分 Matt 的 repo 没提供,要配合你自己的 agent 编排(比如 GitHub Actions 触发 Claude Code 跑 issue)。最简单的做法是 cron 每小时检查 is:open no:assignee label:agent-ready。
这套流程的真正价值
/to-prd 和 /to-issues 看起来像「自动化项目管理」,但 Matt 把它放在工作流核心位置的原因更深:
它强迫你思考「什么是一个完整的小事」。当你被迫把功能切成 vertical slice,你就在做一件软件工程里最难的事——找接缝。这个思维本身比这两个 skill 更值钱。
而且 vertical slice 的尺寸就是 AI 一次能搞定的尺寸。让任务大小匹配 AI 的能力上限——这是和 LLM 协作的根本节奏。
参考资源
to-prd Skill 源文件
完整 PRD 模板和合成指令。
to-issues Skill 源文件
纵向切片规则、HITL/AFK 区分、完整 issue 模板。
用 Claude Code 真实构建一个功能:每一步详解
Matt 演示完整 grill → PRD → issues → TDD 流程的真实案例。
下一篇:TDD:用红绿重构强迫 AI 走小步——issue 切完了,怎么让 AI 真的小步实现。