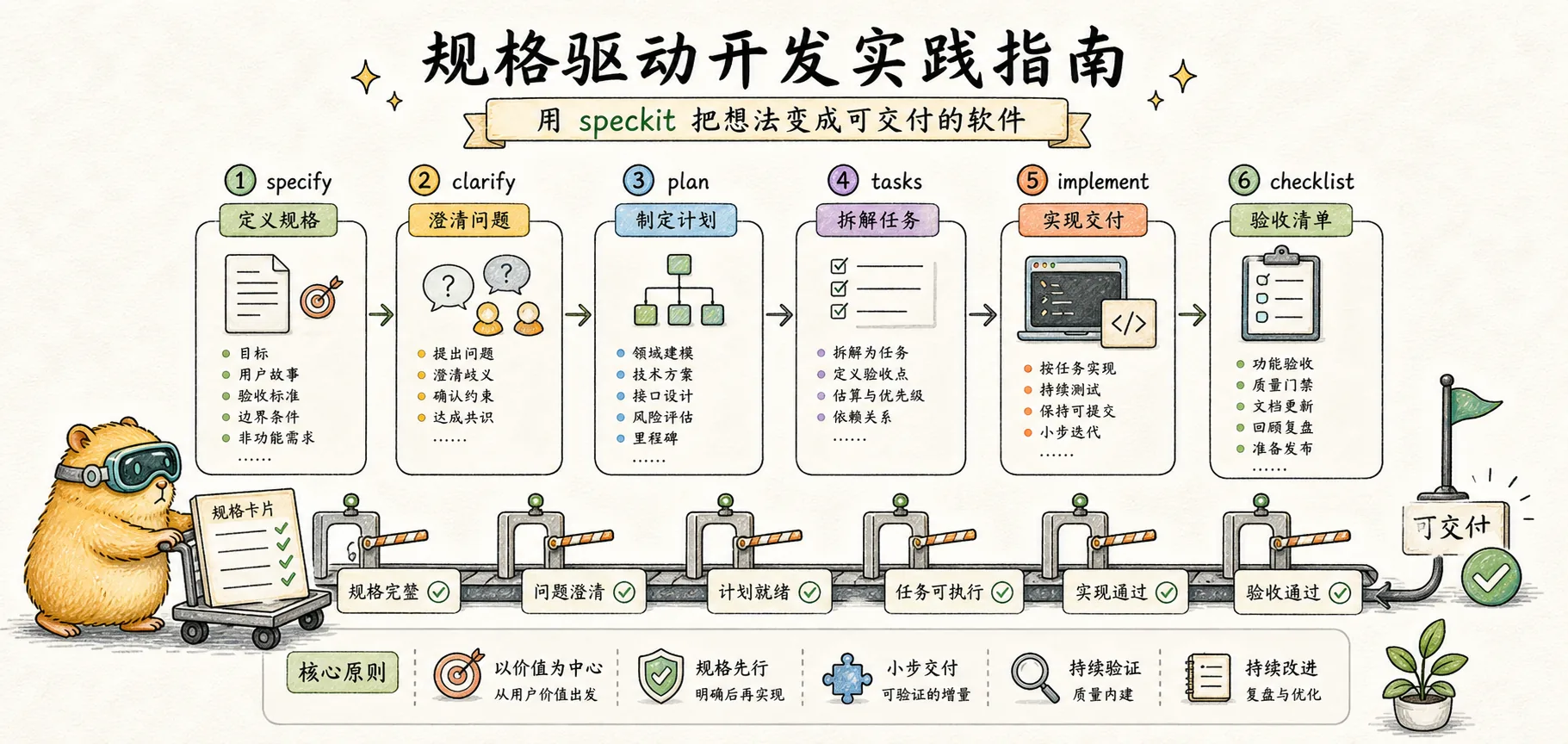
실전 가이드
speckit 명령어로 스펙에서 코드까지의 완전한 워크플로를 익히세요 - 명령어 상세 설명, 전체 사례 시연 및 모범 사례
서론
이전 글에서 스펙 주도 개발의 이념을 알아보았습니다 — 먼저 '무엇을 할 것인지'를 정의하고, 그 다음에 '어떻게 할 것인지'를 고려하는 방식입니다. 얼핏 불필요해 보이는 이 프로세스는 실제로 AI 프로그래밍에서 재작업과 커뮤니케이션 비용을 크게 줄여줍니다.
이번 글에서는 직접 실습해 보겠습니다. speckit 명령어 시리즈를 사용하여 요구사항 기술에서 코드 구현까지의 전체 프로세스를 완성하는 방법을 배우게 됩니다.
설치 및 구성
Speckit 명령어는 GitHub 공식 Spec Kit 프로젝트에서 제공됩니다. 사용 시나리오에 따라 몇 가지 다른 통합 방식이 있습니다.
새 프로젝트 초기화
새 프로젝트의 경우, 공식 specify-cli 도구를 사용하여 초기화하는 것을 권장합니다:
# uv로 specify-cli 설치
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
# 새 프로젝트 초기화, Claude를 AI 어시스턴트로 지정
specify init my-project --ai claude이 명령은 .specify/ 구성 디렉토리와 관련 템플릿 파일을 포함한 프로젝트 디렉토리 구조를 자동으로 생성합니다.
기존 프로젝트 통합
Speckit 명령어를 사용하려면 구성 파일이 필요합니다. 기존 프로젝트에 speckit을 통합할 때는 specify-cli를 사용하는 것을 권장합니다:
cd your-existing-project
specify init . --ai claude # .은 현재 디렉토리를 의미합니다이 명령은 프로젝트에 다음을 생성합니다:
your-project/
├── .specify/
│ ├── templates/ # 스펙, 계획 등의 템플릿
│ ├── scripts/ # 보조 스크립트
│ └── memory/ # constitution.md
├── .claude/
│ └── commands/ # Claude Code 명령어 구성
│ ├── speckit.specify.md
│ ├── speckit.plan.md
│ └── ...
└── specs/ # 기능 스펙 저장 디렉토리초기화 시 기존 파일을 덮어쓰지 않습니다. 완료 후 Claude Code에서 /speckit.* 시리즈 명령어를 사용할 수 있습니다.
주의: speckit 명령어는 Claude Code에 내장된 것이 아니므로, 반드시 위의 초기화 단계를 먼저 완료해야 합니다. 초기화 없이
/speckit.specify를 직접 실행하면 명령어가 존재하지 않는다는 메시지가 표시됩니다.
명령어 상세 설명
Speckit은 스펙 주도 개발의 각 단계를 지원하는 일련의 명령어를 제공합니다. 각 명령어는 명확한 입력과 출력을 가지며, 추적 가능한 체인을 형성합니다.
/speckit.specify — 기능 스펙 생성
이것은 전체 프로세스의 시작점입니다. 자연어로 원하는 기능을 설명하면, AI가 구조화된 스펙 문서로 정리해 줍니다.
기능: 자연어 설명에서 기능 스펙 문서 생성
입력: 기능 설명 (자연어)
출력:
specs/[번호]-[기능명]/spec.md— 기능 스펙 문서- 새 git 브랜치 (예:
001-user-auth)
사용 예시:
/speckit.specify 이메일 비밀번호 로그인을 지원하는 사용자 로그인 기능을 추가하고 싶습니다. 로그인 상태 유지 옵션이 필요합니다실행 후 AI는:
- 간단한 기능 이름을 생성합니다 (예:
user-auth) - 새 기능 브랜치를 생성합니다
- 사용자 스토리, 기능 요구사항, 성공 기준이 포함된 스펙 문서를 생성합니다
- 불명확한 부분에
[NEEDS CLARIFICATION]을 표시합니다
스펙 문서의 핵심 구조:
# Feature Specification: 사용자 로그인 기능
## User Scenarios & Testing
### User Story 1 - 사용자 로그인 (Priority: P1)
사용자가 이메일과 비밀번호로 시스템에 로그인합니다...
**Acceptance Scenarios**:
1. Given 사용자가 올바른 이메일과 비밀번호를 입력, When 로그인 클릭, Then 시스템에 성공적으로 진입
## Requirements
### Functional Requirements
- FR-001: 시스템은 이메일 비밀번호 로그인을 지원해야 합니다
- FR-002: 시스템은 "로그인 상태 유지" 옵션을 제공해야 합니다
## Success Criteria
- SC-001: 사용자가 30초 이내에 로그인 프로세스를 완료할 수 있어야 합니다스펙 문서는 어떤 기술적 세부사항도 포함하지 않습니다 — 어떤 프레임워크를 사용할지, 데이터베이스 구조를 어떻게 할지, API를 어떻게 정의할지 언급하지 않습니다. 이런 것들은 이후 단계에서 다룹니다.
/speckit.clarify — 모호한 부분 명확화
스펙 문서를 작성한 후에도 모호한 부분이 있을 수 있습니다. 이 명령어는 스펙을 검토하고, 핵심 질문을 통해 명확화를 도와줍니다.
기능: 스펙의 모호한 부분을 식별하고, 질의응답을 통해 스펙을 보완
입력: 기존 spec.md 문서
출력: 업데이트된 spec.md (명확화 기록 포함)
사용 예시:
/speckit.clarify실행 후 AI는:
- 스펙 문서의 모호한 부분을 스캔합니다
- 우선순위별로 정렬합니다 (범위 > 보안 > 사용자 경험 > 기술 세부사항)
- 하나씩 질문하며, 한 번에 하나의 질문만 합니다
- 답변에 따라 스펙 문서를 업데이트합니다
질의응답 예시:
## Question 1: 로그인 실패 처리
**Context**: 스펙에서 사용자 로그인을 언급했지만, 로그인 실패 시 처리 방식이 명시되어 있지 않습니다.
**Recommended:** Option B - 연속 5회 실패 후 계정 잠금은 보안 모범 사례입니다
| Option | Description |
|--------|-------------|
| A | 오류 메시지만 표시하고 제한 없음 |
| B | 연속 5회 실패 후 15분간 계정 잠금 |
| C | 캡차를 사용하여 무차별 대입 공격 방지 |
옵션 문자로 답변하거나(예: "B"), "yes"로 권장 사항을 수락하거나, 직접 답변을 제공할 수 있습니다.명확화할 때마다 스펙 문서가 자동으로 업데이트되고, 명확화 기록이 추가됩니다:
## Clarifications
### Session 2025-12-20
- Q: 로그인 실패 시 어떻게 처리하나요? → A: 연속 5회 실패 후 15분간 계정 잠금/speckit.plan — 기술 계획 생성
스펙이 명확해지면 기술 설계 단계로 진입합니다. 이 단계에서는 기술 계획과 조사 보고서가 산출됩니다.
기능: 스펙을 기반으로 기술 구현 계획 생성
입력: spec.md 문서
출력:
plan.md— 기술 계획 (아키텍처, 데이터 모델, API 설계)research.md— 조사 보고서 (기술 선택 결정)data-model.md— 데이터 모델 (해당되는 경우)contracts/— API 계약 (해당되는 경우)
사용 예시:
/speckit.plan 저는 Next.js + Prisma + PostgreSQL을 사용합니다명령어 뒤에 기술 스택 선호도를 추가할 수 있습니다. 실행 후 AI는:
- 스펙의 기능 요구사항을 분석합니다
- 관련 기술의 모범 사례를 조사합니다
- 데이터 모델과 API 구조를 설계합니다
- 완전한 기술 계획을 생성합니다
기술 계획의 핵심 내용:
# Implementation Plan: 사용자 로그인 기능
## Technical Context
**Language/Version**: TypeScript 5.x
**Primary Dependencies**: Next.js 15, Prisma, PostgreSQL
**Authentication**: NextAuth.js with credentials provider
## Project Structure
src/
├── app/
│ └── (auth)/
│ ├── login/
│ └── api/auth/
├── lib/
│ └── auth/
└── prisma/
└── schema.prisma
## Data Model
- User: id, email, passwordHash, createdAt, updatedAt
- Session: id, userId, expiresAt/speckit.tasks — 작업 분해
기술 계획이 완성되면, 이를 실행 가능한 작업 목록으로 분해합니다.
기능: 기술 계획을 실행 가능한 작업 목록으로 분할
입력: plan.md 문서
출력: tasks.md — 의존성 순서로 정렬된 작업 목록
사용 예시:
/speckit.tasks실행 후 AI는:
- plan.md에서 기술 방안을 추출합니다
- spec.md에서 사용자 스토리 우선순위를 추출합니다
- 사용자 스토리별로 그룹화하여 작업을 생성합니다
- 병렬 실행 가능한 작업에
[P]를 표시합니다 - 각 작업에 구체적인 파일 경로를 지정합니다
작업 목록 형식:
## Phase 1: Setup
- [ ] T001 프로젝트 구조 생성
- [ ] T002 [P] Prisma schema 구성
- [ ] T003 [P] NextAuth 구성
## Phase 2: User Story 1 - 사용자 로그인 (P1)
- [ ] T004 [US1] User 모델 생성 in prisma/schema.prisma
- [ ] T005 [US1] 로그인 API 구현 in src/app/api/auth/[...nextauth]/route.ts
- [ ] T006 [US1] 로그인 페이지 생성 in src/app/(auth)/login/page.tsx각 작업에는 다음이 포함됩니다:
- 작업 ID (T001, T002...) — 추적용
- [P] 표시 — 다른 [P] 작업과 병렬 실행 가능함을 표시
- [US] 태그 — 어떤 사용자 스토리에 속하는지 표시
- 파일 경로 — 어떤 파일을 조작할지 명확히 지정
/speckit.implement — 구현 실행
모든 준비가 완료되면 작업 목록 실행을 시작합니다.
기능: 작업 목록에 따라 순차적으로 구현 실행
입력: tasks.md 문서
출력: 실제 코드
사용 예시:
/speckit.implement실행 전에 AI는 체크리스트(있는 경우)를 확인합니다. 실행 시:
- 단계 순서대로 작업을 실행합니다
- 각 작업 완료 시
[X]로 표시합니다 - 작업 의존성 관계를 준수합니다
- 병렬 작업은 동시에 진행할 수 있습니다
실행 과정 예시:
Phase 1: Setup
✓ T001 프로젝트 구조 생성
✓ T002 Prisma schema 구성
✓ T003 NextAuth 구성
Phase 2: User Story 1
✓ T004 User 모델 생성
T005 실행 중...구현 후 검토
/speckit.implement 완료 후, 코드를 바로 병합하지 마십시오. AI가 생성한 코드는 사람이 검토해야 합니다:
반드시 수행해야 하는 검증 단계:
-
테스트 스위트 실행
npm test # 또는 사용 중인 테스트 명령어AI가 기존 기능을 손상시키지 않았는지 확인합니다.
-
코드 리뷰 포인트
- 스펙의 의도에 부합하는지 (spec.md 대조)
- 프로젝트의 코드 스타일을 따르는지
- 잠재적 보안 문제가 있는지
-
경계 테스트 AI가 놓칠 수 있는 경계 케이스를 수동으로 테스트합니다:
- 빈 값 처리
- 극단적 입력
- 동시성 시나리오
- 오류 경로
-
성능 점검 데이터베이스 작업이나 API 호출이 관련된 경우, N+1 쿼리 등의 성능 문제가 없는지 확인합니다.
팁: 스펙을 아무리 상세하게 작성하더라도, AI는 구현 세부사항에서 편차가 발생할 수 있습니다. 검토는 스펙 주도 개발을 불신하는 것이 아니라, 엔지니어링 규율의 일부입니다.
/speckit.analyze — 일관성 분석
이것은 선택적인 품질 검사 단계로, 스펙, 계획, 작업 간의 일관성을 검증하는 데 사용됩니다.
기능: 문서 간 일관성 및 품질 분석
입력: spec.md, plan.md, tasks.md
출력: 분석 보고서 (어떤 파일도 수정하지 않음)
사용 예시:
/speckit.analyze실행 후 다음을 검사합니다:
- 모든 요구사항에 대응하는 작업이 있는지
- 작업이 모든 사용자 스토리를 커버하는지
- 용어가 일관적인지
- 누락이나 중복이 있는지
기타 명령어 (선택 사항)
위의 핵심 명령어 외에도, speckit은 몇 가지 보조 명령어를 제공합니다. 이 명령어들은 주요 프로세스에 포함되지 않지만, 특정 시나리오에서 유용합니다.
/speckit.constitution — 프로젝트 헌법 생성
프로젝트의 개발 원칙과 규범을 정의하는 데 사용됩니다. 팀 프로젝트에 적합하며, 모든 구성원이 통일된 개발 표준을 따르도록 보장합니다.
- 입력: 대화형 질의응답 또는 원칙 직접 제공
- 출력:
.specify/constitution.md프로젝트 헌법 파일 - 시나리오: 새 팀 프로젝트 초기화, 코드 스타일 및 아키텍처 결정 통일
/speckit.checklist — 품질 검사 체크리스트 생성
기능 스펙을 기반으로 맞춤형 품질 검사 체크리스트를 생성하여, 구현 전 품질 기준을 확인하는 데 사용됩니다.
- 입력: spec.md 문서
- 출력:
checklists/디렉토리에 검사 체크리스트 - 시나리오: 중요 기능 출시 전 품질 점검, 코드 리뷰 참고
/speckit.taskstoissues — 작업을 GitHub Issues로 변환
tasks.md의 작업을 자동으로 GitHub Issues로 변환하여, 팀 협업과 작업 배정을 편리하게 합니다.
- 입력: tasks.md 문서
- 출력: GitHub Issues (gh CLI를 통해 생성)
- 시나리오: 팀 협업 개발, Sprint 계획, 작업 추적
도구 생태계
이 글에서 소개한 speckit 명령어는 GitHub Spec Kit 프로젝트에서 제공됩니다. 이 외에도 2025년에 여러 주요 AI 프로그래밍 도구들이 유사한 스펙 주도 워크플로를 지원하기 시작했습니다:
| 도구 | 특징 | 적용 시나리오 |
|---|---|---|
| GitHub Spec Kit | 이 글에서 사용한 도구, MIT 오픈소스, Claude Code / Copilot / Gemini CLI 지원 | 명령줄 선호자, 크로스 도구 협업 |
| AWS Kiro | VS Code 포크, 시각화 워크플로, EARS 표기법 | GUI 선호자, AWS 생태계 사용자 |
| JetBrains Junie | IntelliJ 생태계 통합, Think More 추론 모드 | JetBrains IDE 사용자 |
| Cursor Plan Mode | 내장 계획 단계, 실행 계획 자동 생성 | 이미 Cursor를 사용 중인 개발자 |
선택 방법:
- Claude Code, GitHub Copilot 또는 Gemini CLI를 사용한다면 GitHub Spec Kit을 권장합니다
- 그래픽 인터페이스와 시각화 워크플로를 선호한다면 AWS Kiro를 시도해 볼 수 있습니다
- JetBrains 사용자라면 Junie가 IDE와의 통합이 더 자연스럽습니다
- 이미 Cursor를 사용 중이라면 Plan Mode가 유사한 계획 기능을 제공합니다
핵심 이념은 동일합니다 — 도구는 단지 수단일 뿐이며, 중요한 것은 스펙을 먼저, 코드는 나중에라는 사고방식입니다.
전체 사례 시연
실제 사례를 통해 speckit의 전체 프로세스를 진행해 보겠습니다.
시나리오: 블로그 시스템에 글 북마크 기능 추가
Step 1: 스펙 생성
/speckit.specify 블로그에 글 북마크 기능을 추가하고 싶습니다. 사용자가 좋아하는 글을 북마크하고 개인 센터에서 북마크 목록을 볼 수 있어야 합니다AI가 스펙 문서 specs/002-article-bookmark/spec.md를 생성합니다:
# Feature Specification: 글 북마크 기능
## User Scenarios & Testing
### User Story 1 - 글 북마크 (Priority: P1)
사용자가 글을 읽을 때 북마크 버튼을 클릭하여 글을 북마크 목록에 추가합니다.
**Acceptance Scenarios**:
1. Given 사용자가 로그인한 상태, When 북마크 버튼 클릭, Then 글이 북마크 목록에 추가됨
2. Given 사용자가 로그인하지 않은 상태, When 북마크 버튼 클릭, Then 로그인 안내
### User Story 2 - 북마크 목록 조회 (Priority: P2)
사용자가 개인 센터에서 자신이 북마크한 모든 글을 조회합니다.
## Requirements
- FR-001: 사용자는 글을 북마크/북마크 해제할 수 있어야 합니다
- FR-002: 북마크 버튼은 현재 북마크 상태를 표시해야 합니다
- FR-003: 개인 센터에 북마크 목록이 표시되어야 합니다
## Success Criteria
- SC-001: 북마크 작업이 500ms 이내에 완료되어야 합니다
- SC-002: 북마크 목록은 페이지네이션을 지원하며 페이지당 10개의 글을 표시합니다Step 2: 요구사항 명확화
/speckit.clarifyAI가 질문합니다: 「북마크 수에 상한이 있나요?」
답변: 「최대 100개까지 북마크할 수 있습니다」
스펙이 업데이트되어 다음이 추가됩니다:
- FR-004: 각 사용자는 최대 100개의 글을 북마크할 수 있습니다
- 상한에 도달하면 안내 메시지를 표시합니다
Step 3: 계획 생성
/speckit.plan Next.js + Prisma 사용다음을 포함한 기술 계획이 생성됩니다:
- Bookmark 모델 (userId, articleId, createdAt)
- API 라우트 설계 (POST/DELETE /api/bookmarks)
- 컴포넌트 설계 (BookmarkButton, BookmarkList)
Step 4: 작업 분해
/speckit.tasks작업 목록이 생성됩니다:
## Phase 1: Setup
- [ ] T001 Prisma schema에 Bookmark 모델 추가
## Phase 2: US1 - 글 북마크
- [ ] T002 [US1] 북마크 API 생성 in src/app/api/bookmarks/route.ts
- [ ] T003 [US1] BookmarkButton 컴포넌트 생성 in src/components/BookmarkButton.tsx
- [ ] T004 [US1] 글 페이지에 통합
## Phase 3: US2 - 북마크 목록
- [ ] T005 [US2] 북마크 목록 페이지 생성 in src/app/profile/bookmarks/page.tsx
- [ ] T006 [US2] 페이지네이션 로직 구현Step 5: 구현 실행
/speckit.implement작업 순서에 따라 실행하며, 각 작업 완료 시 [X]로 표시합니다.
모범 사례 및 주의사항
speckit을 사용해야 할 때
적합한 시나리오:
- 새 기능 개발 (3개 이상의 파일 관련)
- 요구사항이 완전히 명확하지 않을 때 (clarify로 명확화)
- 다인 협업 프로젝트 (스펙이 합의 기준 역할)
- 중요한 기능 (추적 가능성이 필요한 경우)
적합하지 않은 시나리오:
- 간단한 버그 수정
- 한 줄 코드 변경
- 긴급 핫픽스
- 순수 탐색적 실험
흔한 함정
speckit을 사용하는 과정에서 주의해야 할 몇 가지 흔한 함정이 있습니다:
함정 1: 스펙이 너무 모호함
증상: AI가 생성한 코드가 기대와 크게 다르며, 대량의 재작업이 필요합니다.
# ❌ 모호한 스펙
사용자가 글을 검색할 수 있음
# ✓ 명확한 스펙
- FR-001: 사용자가 제목 키워드로 글을 검색할 수 있음
- FR-002: 검색 결과는 관련도순으로 정렬, 페이지당 10개 표시
- FR-003: 검색어가 결과에서 하이라이트 표시됨
- FR-004: 검색어가 비어있으면 인기 글을 표시해결 방법: /speckit.clarify를 실행하거나, 기능 요구사항과 성공 기준을 수동으로 보충합니다.
함정 2: 스펙이 너무 상세함
증상: AI가 제한되어 능력을 발휘하지 못하고, 생성된 코드가 지나치게 경직되거나, 일부 지시를 무시합니다.
# ❌ 과도하게 상세 (구현 세부사항 지정)
lodash의 debounce 함수를 사용하고, 300ms 지연,
useCallback으로 감싸고, 의존성은 [searchTerm]...
# ✓ 적절한 수준의 상세도 (무엇을 할지만 기술)
검색 입력에 디바운스를 적용하여 빈번한 요청을 방지해결 방법: 스펙은 '무엇을 할지' 수준을 유지하고, '어떻게 할지'는 Plan 단계에 맡깁니다.
함정 3: Plan 단계 건너뛰기
증상: Tasks가 너무 대략적이거나 너무 세분화되어, 구현 시 빈번한 재작업이 발생하고, 작업 간 의존성 관계가 혼란스럽습니다.
해결 방법: 복잡한 기능은 반드시 Plan 단계를 완료합니다. Plan은 기술 방안을 산출할 뿐만 아니라 잠재적 아키텍처 문제를 식별하는 데도 도움이 됩니다.
함정 4: 검토 없이 바로 병합
증상: 출시 후 경계 케이스 미처리, 보안 취약점, 성능 문제가 발견됩니다.
해결 방법: 위의 '구현 후 검토' 섹션을 참고하여, 병합 전에 항상 테스트와 코드 리뷰를 수행합니다.
자주 묻는 질문
Q: 모든 기능에 대해 전체 프로세스를 거쳐야 하나요?
아닙니다. 간단한 변경은 바로 코딩할 수 있으며, 복잡한 기능은 최소한 specify + plan을 완료하는 것을 권장합니다.
Q: 스펙을 매우 상세하게 작성했는데도 AI가 기대에 맞지 않는 코드를 생성했습니다.
스펙이 정말 '상세'한지 확인하십시오. 많은 경우 명확하게 설명했다고 생각하지만 실제로는 모호한 부분이 남아있습니다. /speckit.clarify를 실행하여 누락된 부분이 없는지 확인해 보십시오.
Q: 일부 단계를 건너뛸 수 있나요?
가능합니다. 최소 프로세스는 specify → tasks → implement입니다. 그러나 clarify와 plan을 건너뛰면 후반 재작업 위험이 증가할 수 있습니다.
Q: 이미 생성된 스펙을 수정하려면 어떻게 하나요?
spec.md 파일을 직접 편집하면 됩니다. 수정 후에는 일관성을 유지하기 위해 plan과 tasks를 다시 생성하는 것을 권장합니다.
Q: AI가 생성한 코드가 완전히 잘못되었을 때 어떻게 디버깅하나요?
몇 가지 단계로 원인을 파악합니다:
- 스펙 확인: 스펙이 정말 명확한가요?
/speckit.clarify를 실행하여 누락이 없는지 확인합니다 - 계획 확인: plan.md의 기술 방안이 합리적인가요? 합리적이지 않다면 직접 편집한 후 tasks를 다시 생성합니다
- 범위 축소: AI에게 하나의 작업만 실행하게 하고, 출력이 기대에 부합하는지 관찰합니다
- 제약 조건 추가: constitution.md에 더 명확한 기술 선호도를 추가합니다
Q: Plan과 Tasks가 일치하지 않으면 어떻게 하나요?
/speckit.analyze를 실행하면 불일치를 감지할 수 있습니다. 일반적인 원인:
- Plan을 업데이트한 후 Tasks를 다시 생성하는 것을 잊은 경우
- Tasks를 수동으로 편집했지만 Plan을 업데이트하지 않은 경우
- 스펙 변경 후 일부 문서만 업데이트한 경우
해결 방법: spec.md를 기준으로 삼아 plan.md와 tasks.md를 순차적으로 다시 생성합니다.
Q: 기능 간 의존성을 어떻게 처리하나요?
기능 B가 기능 A에 의존하는 경우, 두 가지 방법이 있습니다:
- 스펙 통합: A와 B를 하나의 spec.md에 작성하여 AI가 통합적으로 계획하도록 합니다
- 단계별 개발: A의 전체 프로세스를 먼저 완료한 후 B의 specify를 시작합니다
의존성이 있는 여러 기능을 동시에 개발하는 것은 권장하지 않습니다. 통합 문제를 야기하기 쉽습니다.
요약
Speckit의 핵심 가치는 프로세스를 추가하는 것이 아니라, 암묵적 지식을 명시적으로 만드는 것입니다. 사용자 스토리, 기능 요구사항, 성공 기준을 작성하도록 요구받으면, '말하지 않아도 당연한' 것이라고 생각했던 세부사항들이 수면 위로 떠오릅니다.
이 프로세스를 기억하십시오:
Specify → Clarify → Plan → Tasks → Implement
요구사항 명확화 설계 분해 실행각 단계는 다음 단계의 모호성을 줄여줍니다. 최종적으로 AI가 받는 것은 명확한 작업 목록이지, 모호한 의도 설명이 아닙니다.
이제 여러분의 프로젝트로 돌아가 /speckit.specify로 첫 번째 스펙 주도 개발 프로세스를 시작해 보십시오.
추가 읽을거리
- 《스펙 주도 개발이란 무엇인가》— 핵심 이념 복습
- 《GSD 심층 분석》— 스펙 주도 사고방식을 채택한 또 다른 컨텍스트 엔지니어링 시스템
- 《Claude Skills란 무엇인가》— Speckit 자체가 하나의 Claude Skill입니다