Pi Agent 실천 가이드
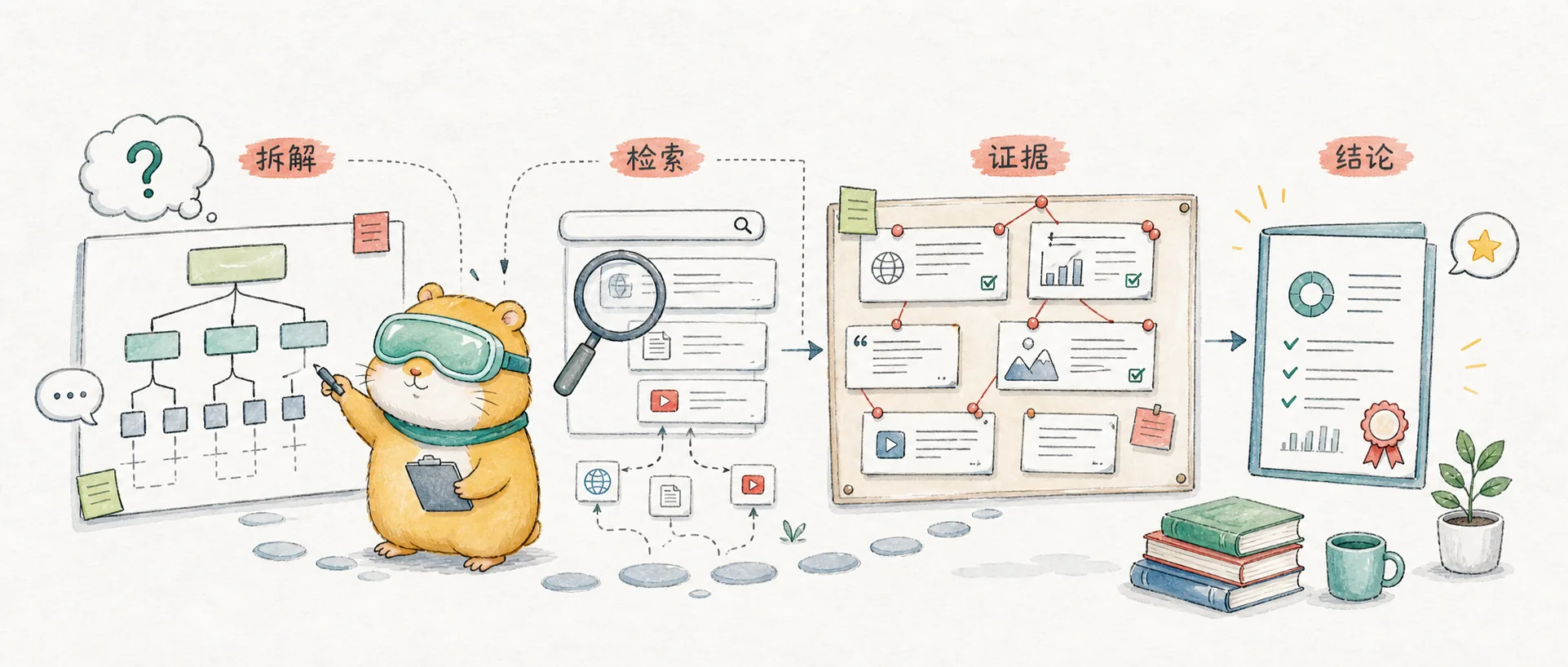
Pi Extension으로 DeepSearch 기능 구현하기: Pi가 문제를 분해하고, 자료를 검색하고, 증거를 정리하여 출처가 있는 연구 결론을 생성하도록 합니다.
빠른 요약
개념 편에서 저는 Pi Agent를 극도로 간소화된 Agent Harness로 이해했습니다. 이는 모델, 터미널, 파일 시스템, 셸, 세션 및 확장 시스템을 연결하지만, 무거운 워크플로우를 미리 설정하지는 않습니다.
따라서 실천 편에서는 일반적인 "Pi가 파일을 수정하도록 하는" 사례를 다루고 싶지 않습니다. 그 사례는 기본적인 루프를 설명할 수 있지만, Pi의 확장성을 충분히 보여주지는 못합니다.
Pi에 더 적합한 실전 사례는 Pi가 기본적으로 가지고 있지 않지만 많은 사람들이 실제로 필요로 하는 기능인 DeepSearch를 추가하는 것입니다.
여기서 DeepSearch는 단순한 웹 검색이 아니라 연구 기반 워크플로우입니다.
| 단계 | 수행할 작업 |
|---|---|
| 문제 분해 | 모호한 질문을 검색 가능한 몇 가지 하위 질문으로 분해 |
| 다중 검색 | 공식 문서, 코드 저장소, 블로그, 토론 포럼 또는 논문을 각각 검색 |
| 출처 필터링 | 중복 제거, 낮은 품질 결과 제외, 1차 출처 우선 유지 |
| 증거 정리 | 핵심 사실, 링크, 시간, 버전 및 불확실성 추출 |
| 종합 답변 | 결론 제시, 근거 및 제한 사항 설명 |
제 판단은 다음과 같습니다. DeepSearch는 Pi 본체에 작성되어서는 안 되며, 프롬프트만으로 해결해서도 안 됩니다. Pi Extension으로 만드는 것이 더 적합합니다.
이유는 간단합니다. DeepSearch는 네트워크 요청, 타사 검색 API, 출처 필터링, 결과 잘라내기, 인용 형식 및 보안 경계를 포함합니다. 이 모든 것은 코딩 에이전트의 최소 핵심이 아닌 워크플로우 기능에 속합니다.
설계 목표
이 사례는 완벽한 연구 시스템이 아닌, 실행 가능한 최소 버전을 구현하는 것을 목표로 합니다.
목표는 다음과 같습니다.
Pi에 deep_search 도구를 추가합니다.
이 도구는 다음을 받습니다.
- query: 사용자가 연구할 질문
- depth: 검색 깊이
- maxResults: 반환할 최대 후보 자료 수
이 도구는 다음을 출력합니다.
- 구조화된 검색 결과
- 각 결과의 제목, URL, 요약, 관련성
- 모델이 사용할 증거 힌트
Pi는 이 증거를 받은 후 현재 모델이 최종 결론을 생성합니다.저는 의도적으로 "검색"과 "종합"을 분리할 것입니다.
| 부분 | 누가 담당하는가 | 이유 |
|---|---|---|
| 검색 API 호출 | DeepSearch extension | 이는 확정적인 외부 기능입니다 |
| 결과 중복 제거 및 잘라내기 | DeepSearch extension | 컨텍스트가 노이즈로 가득 차는 것을 방지합니다 |
| 어떤 증거가 중요한지 판단 | Pi 현재 모델 | 추론 및 컨텍스트 이해가 필요합니다 |
| 최종 답변 작성 | Pi 현재 모델 | 사용자 질문 및 프로젝트 컨텍스트와 결합해야 합니다 |
이렇게 하는 것이 더 안정적입니다. Extension은 자체적으로 모델을 호출할 필요가 없으며, 중첩된 에이전트가 될 필요도 없습니다. 고품질 증거만 제공하여 Pi의 원래 모델이 계속 추론하도록 합니다.
준비 작업
Pi extension은 전역 디렉터리 또는 프로젝트 디렉터리에 배치할 수 있습니다. 여기서는 먼저 프로젝트 디렉터리에 배치하는 것을 권장합니다.
.pi/extensions/deepsearch/
package.json
index.ts프로젝트 로컬 extension의 장점은 경계가 명확하다는 것입니다. 이 DeepSearch 기능은 현재 프로젝트에서만 활성화되며, 모든 Pi 세션에 영향을 미치지 않습니다.
검색 서비스는 Tavily, Exa, Brave Search, SerpAPI 또는 자체 검색 백엔드를 선택할 수 있습니다. 첫 번째 버전에서는 서비스 제공업체에 얽매이지 말고, 먼저 searchWeb() 함수로 추상화하십시오.
예를 들어, 환경 변수에 API 키를 저장합니다.
export TAVILY_API_KEY=tvly-...타사 검색 API를 연결하고 싶지 않다면, 먼저 로컬 모의 데이터를 사용하여 extension을 실행할 수 있습니다. 도구 등록, 매개변수 전달 및 결과 형식이 안정화된 후 실제 검색 서비스를 연결하십시오.
Step 1: Extension 디렉터리 생성
먼저 디렉터리를 생성합니다.
mkdir -p .pi/extensions/deepsearchextension에 종속성이 필요한 경우 package.json을 배치할 수 있습니다.
{
"name": "pi-deepsearch-extension",
"private": true,
"dependencies": {
"typebox": "*",
"@earendil-works/pi-ai": "*",
"@earendil-works/pi-coding-agent": "*"
},
"pi": {
"extensions": ["./index.ts"]
}
}그런 다음 종속성을 설치합니다.
cd .pi/extensions/deepsearch
npm installPi의 extension은 TypeScript 모듈이므로 수동으로 컴파일할 필요가 없습니다. 이 경험은 도구 실험을 빠르게 수행하는 데 매우 적합합니다.
Step 2: deep_search 도구 등록
핵심 파일은 .pi/extensions/deepsearch/index.ts입니다.
첫 번째 버전은 다음과 같이 작성할 수 있습니다.
import type { ExtensionAPI } from "@earendil-works/pi-coding-agent";
import { StringEnum } from "@earendil-works/pi-ai";
import { Type } from "typebox";
type SearchResult = {
title: string;
url: string;
snippet: string;
score?: number;
};
export default function (pi: ExtensionAPI) {
pi.registerTool({
name: "deep_search",
label: "DeepSearch",
description: "Search the web for source-backed evidence about a question.",
promptSnippet: "Research a question with web search and return source-backed evidence.",
promptGuidelines: [
"Use deep_search when the user asks for current facts, external sources, comparison, investigation, or source-backed research.",
"After deep_search returns results, synthesize an answer with citations and clearly separate facts, inference, and uncertainty.",
"Do not treat deep_search results as final truth; inspect source quality and mention gaps."
],
parameters: Type.Object({
query: Type.String({
description: "The research question or search query."
}),
depth: Type.Optional(StringEnum(["quick", "normal", "deep"] as const)),
maxResults: Type.Optional(Type.Number({
minimum: 3,
maximum: 10,
default: 6
}))
}),
async execute(_toolCallId, params, signal) {
const depth = params.depth ?? "normal";
const maxResults = params.maxResults ?? 6;
const results = await searchWeb(params.query, depth, maxResults, signal);
return {
content: [
{
type: "text",
text: formatResultsForModel(params.query, results)
}
],
details: {
query: params.query,
depth,
results
}
};
}
});
}
async function searchWeb(
query: string,
depth: "quick" | "normal" | "deep",
maxResults: number,
signal: AbortSignal
): Promise<SearchResult[]> {
const apiKey = process.env.TAVILY_API_KEY;
if (!apiKey) {
throw new Error("Missing TAVILY_API_KEY. Set it before starting pi.");
}
const response = await fetch("https://api.tavily.com/search", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
api_key: apiKey,
query,
search_depth: depth === "quick" ? "basic" : "advanced",
max_results: maxResults,
include_answer: false,
include_raw_content: depth === "deep"
}),
signal
});
if (!response.ok) {
throw new Error(`Search failed: ${response.status} ${response.statusText}`);
}
const data = await response.json() as {
results?: Array<{
title?: string;
url?: string;
content?: string;
score?: number;
}>;
};
return dedupeByUrl((data.results ?? []).map((item) => ({
title: item.title ?? "Untitled",
url: item.url ?? "",
snippet: item.content ?? "",
score: item.score
}))).filter((item) => item.url);
}
function dedupeByUrl(results: SearchResult[]): SearchResult[] {
const seen = new Set<string>();
const deduped: SearchResult[] = [];
for (const result of results) {
const key = normalizeUrl(result.url);
if (seen.has(key)) continue;
seen.add(key);
deduped.push(result);
}
return deduped;
}
function normalizeUrl(url: string): string {
try {
const parsed = new URL(url);
parsed.hash = "";
parsed.searchParams.delete("utm_source");
parsed.searchParams.delete("utm_medium");
parsed.searchParams.delete("utm_campaign");
return parsed.toString();
} catch {
return url;
}
}
function formatResultsForModel(query: string, results: SearchResult[]): string {
if (results.length === 0) {
return `DeepSearch found no results for: ${query}`;
}
const lines = results.map((result, index) => {
return [
`## Source ${index + 1}`,
`Title: ${result.title}`,
`URL: ${result.url}`,
result.score === undefined ? undefined : `Score: ${result.score}`,
`Snippet: ${result.snippet}`
].filter(Boolean).join("\n");
});
return [
`DeepSearch query: ${query}`,
"",
"Use these sources as evidence. Cite URLs when making factual claims.",
"Separate confirmed facts from inference and uncertainty.",
"",
...lines
].join("\n\n");
}이 코드는 가장 중요한 작업만 수행합니다.
| 코드 위치 | 역할 |
|---|---|
pi.registerTool() | deep_search를 모델 호출에 노출 |
parameters | 모델에 도구가 어떤 매개변수를 필요로 하는지 알림 |
promptGuidelines | 모델에 언제 사용하고, 사용 후 어떻게 처리해야 하는지 알림 |
searchWeb() | 실제 검색 서비스 호출 |
dedupeByUrl() | 중복 URL 제거 |
formatResultsForModel() | 검색 결과를 모델이 쉽게 참조할 수 있는 증거 블록으로 정리 |
첫 번째 버전에서는 너무 복잡하게 만들지 마십시오. DeepSearch의 진정한 어려움은 검색 요청을 작성하는 것이 아니라, 출처 품질, 컨텍스트 길이, 인용 형식 및 불확실성을 제어하는 것입니다.
Step 3: /deepsearch 명령 추가
도구는 모델이 호출하도록 되어 있지만, 사용자에게도 직접적인 진입점이 필요합니다.
사용자 입력을 더 명확한 연구 작업으로 다시 작성하는 명령을 추가로 등록할 수 있습니다.
export default function (pi: ExtensionAPI) {
pi.registerCommand("deepsearch", {
description: "Run a source-backed DeepSearch task",
handler: async (args, ctx) => {
const query = String(args ?? "").trim();
if (!query) {
ctx.ui.notify("Usage: /deepsearch <question>", "warning");
return;
}
pi.sendUserMessage(
[
"아래 질문에 대해 DeepSearch를 수행해 주세요.",
"",
`질문: ${query}`,
"",
"요구 사항:",
"1. 먼저 deep_search를 호출해야 하는지 판단합니다.",
"2. 질문이 복잡하면 2-4개의 하위 질문으로 분해하여 각각 검색합니다.",
"3. 최종 답변에는 반드시 출처 링크가 포함되어야 합니다.",
"4. 사실, 추론 및 아직 불확실한 부분을 구분합니다.",
"5. 검색 결과를 그대로 나열하지 말고, 종합적인 판단을 제시합니다."
].join("\n"),
{ deliverAs: "followUp" }
);
}
});
pi.registerTool({
// deep_search tool definition...
});
}이제 사용자는 직접 다음과 같이 입력할 수 있습니다.
/deepsearch Pi Coding Agent의 extension 메커니즘은 어떤 기능에 적합한가요?/deepsearch는 직접 검색하지 않고, Pi에 더 완전한 작업 설명을 보냅니다. 모델은 설명에 따라 deep_search를 호출하고, 결과를 기반으로 종합적인 작업을 완료합니다.
저는 이러한 설계를 더 선호합니다. 에이전트의 판단 공간을 유지하기 때문입니다. 검색 도구는 증거의 진입점일 뿐, 최종 답변 생성기가 아닙니다.
Step 4: 시작 및 검증
프로젝트 로컬 extension이 준비되면 프로젝트 루트 디렉터리에서 Pi를 직접 시작할 수 있습니다.
TAVILY_API_KEY=tvly-... pi임시로 테스트하는 경우, extension을 명시적으로 지정할 수도 있습니다.
TAVILY_API_KEY=tvly-... pi -e ./.pi/extensions/deepsearch/index.tsPi에 들어간 후, 외부 사실이 필요한 질문을 먼저 합니다.
/deepsearch Pi Coding Agent 최신 버전의 extension 시스템은 어떤 기능을 지원하나요?허용 가능한 출력은 단순히 몇 가지 검색 결과가 아니라 다음을 포함해야 합니다.
| 체크포인트 | 적합한 성능 |
|---|---|
| 도구 호출 여부 | deep_search가 호출된 것을 볼 수 있음 |
| 출처 명확성 | 각 핵심 사실 뒤에 URL이 있음 |
| 중복 제거 여부 | 동일한 페이지를 중복 인용하지 않음 |
| 판단 여부 | 자료만 나열하지 않고, 적용 가능한 시나리오를 요약할 수 있음 |
| 불확실성 여부 | 버전 변경, 타사 API, 커뮤니티 확장에 대한 경계를 유지 |
결과가 단순히 "검색 결과 목록"이라면 promptGuidelines가 충분히 강력하지 않다는 의미입니다. 가이드라인을 더 명확하게 변경할 수 있습니다.
promptGuidelines: [
"Use deep_search to gather evidence, not to produce the final answer.",
"After deep_search, write a concise research brief with citations.",
"Prefer official documentation, source code, release notes, and primary sources.",
"Mention when sources disagree or when the evidence is incomplete."
]Step 5: DeepSearch를 연구 도구처럼 만들기
첫 번째 버전을 실행한 후, 세 가지 유형의 기능을 계속 추가할 수 있습니다.
하위 문제 분해
DeepSearch가 가장 실패하기 쉬운 부분은 큰 문제를 검색 API에 직접 던지는 것입니다.
예를 들어:
Pi Agent가 Claude Code를 대체할 수 있나요?이것은 좋은 검색 쿼리가 아닙니다. 적어도 다음으로 분해할 수 있습니다.
| 하위 문제 | 역할 |
|---|---|
| Pi Agent의 핵심 설계는 무엇인가 | 포지셔닝 찾기 |
| Pi Agent는 어떤 도구와 확장을 지원하는가 | 기능 경계 찾기 |
| Claude Code의 기본 기능은 무엇인가 | 비교 대상 찾기 |
| 둘의 권한, 보안, 확장성 차이는 무엇인가 | 판단 형성 |
첫 번째 버전에서는 모델이 스스로 분해하도록 할 수 있습니다. 두 번째 버전에서는 /deepsearch 명령이 모델에게 먼저 하위 질문을 나열한 다음 deep_search를 하나씩 호출하도록 강제할 수 있습니다.
출처 품질 계층화
DeepSearch의 출력은 검색 API의 점수 순서로만 정렬되어서는 안 됩니다. 실제 기술 문서를 작성할 때는 다음을 우선적으로 고려합니다.
| 우선순위 | 출처 |
|---|---|
| P0 | 공식 문서, 소스 코드, 릴리스 노트 |
| P1 | 저자 블로그, 유지 관리자 설명, 이슈 / PR |
| P2 | 고품질 튜토리얼, 기술 분석 |
| P3 | 커뮤니티 토론, Reddit, X, 포럼 |
Extension은 formatResultsForModel()에서 먼저 출처 유형을 표시할 수 있습니다.
function classifySource(url: string): "official" | "source" | "community" | "other" {
const host = new URL(url).hostname;
if (host === "pi.dev") return "official";
if (host === "github.com") return "source";
if (host.includes("reddit.com")) return "community";
return "other";
}이렇게 하면 모델이 종합할 때 커뮤니티 소문과 공식 문서를 동일한 증거 등급으로 취급하지 않습니다.
컨텍스트 잘라내기
검색 결과는 컨텍스트를 쉽게 오염시킬 수 있습니다. DeepSearch 도구 출력은 간결하고 정교해야 합니다.
제 제안은 다음과 같습니다.
| 내용 | 도구 출력에 포함 여부 |
|---|---|
| 제목 | 포함 |
| URL | 포함 |
| 200-500자 요약 | 포함 |
| 페이지 전체 텍스트 | 기본적으로 포함하지 않음 |
| 원본 HTML | 포함하지 않음 |
| 검색 API 원본 JSON | details에 포함, 본문에 포함하지 않음 |
전체 텍스트 읽기가 정말 필요한 경우, 두 번째 도구를 만들 수 있습니다.
fetch_source(url)이렇게 하면 DeepSearch는 첫 번째 단계에서 후보 출처를 찾고, 두 번째 단계에서는 가장 중요한 2-3개 페이지만 가져옵니다. 처음부터 수십 개의 웹 페이지 전체 텍스트를 모델에 모두 넣지 마십시오.
자주 묻는 질문
왜 bash로 검색 스크립트를 직접 실행하지 않나요?
가능하지만 extension만큼 안정적이지 않습니다.
bash를 사용하는 문제는 모델이 매번 명령, 매개변수, 출력 형식 및 오류 처리를 다시 결정해야 한다는 것입니다. Extension은 이러한 세부 사항을 고정하여 모델이 deep_search만 호출하면 되도록 합니다.
왜 요약도 extension에 작성하지 않나요?
첫 번째 버전에서는 권장하지 않습니다.
extension이 자체적으로 모델을 호출하여 요약하면 중첩된 모델 호출, 비용 계산, 컨텍스트 드리프트 및 인용 책임 문제가 발생합니다. 더 간단한 방법은 extension이 증거만 반환하고, Pi 현재 세션의 모델이 종합을 담당하는 것입니다.
이 DeepSearch는 MCP에 해당하나요?
아닙니다. 이는 Pi extension이 등록한 로컬 도구입니다.
이미 성숙한 MCP 검색 서버가 있다면 Pi의 MCP 관련 패키지 또는 extension을 통해 연결할 수도 있습니다. 하지만 이 사례는 Pi 자체의 확장 메커니즘을 이해하기 위해 직접 extension을 작성하는 것을 선택했습니다.
보안상 주의할 점은 무엇인가요?
적어도 네 가지 사항에 주의해야 합니다.
| 위험 | 조치 |
|---|---|
| API 키 유출 | 환경 변수에서만 읽고, 저장소에 작성하지 않음 |
| 신뢰할 수 없는 웹 페이지 내용 | 웹 페이지 내용을 시스템 명령으로 간주하지 않고, 검증할 증거로만 간주 |
| 검색 결과 오염 | 공식 및 소스 코드를 우선하고, 커뮤니티 결과의 가중치를 낮춤 |
| 컨텍스트 폭발 | 결과 수 및 요약 길이 제한 |
DeepSearch는 "검색 강화"처럼 보이지만, 본질적으로 외부 웹 페이지를 에이전트 컨텍스트로 가져오는 것입니다. 외부 내용이 컨텍스트로 들어오면 프롬프트 인젝션을 실제 위험으로 간주해야 합니다.
요약
저는 Pi Agent의 첫 번째 실전 사례를 DeepSearch Extension으로 정할 것입니다. 이는 Pi의 세 가지 핵심 특징을 동시에 보여줄 수 있기 때문입니다.
- Pi의 핵심은 기본적으로 작으며, 모든 워크플로우를 내장하지 않습니다.
- 실제로 유용한 기능은 extension을 통해 추가할 수 있습니다.
- Extension은 단순히 명령을 추가하는 것이 아니라, 모델이 외부 세계로 진입하는 경계를 정의하는 것입니다.
이 사례가 성공적으로 실행되면 Pi는 단순히 로컬 코드 편집 에이전트가 아니라, 제어 가능한 연구 진입점을 갖게 됩니다. 외부 자료가 필요한 문제에 직면했을 때, 먼저 검색하고, 필터링하고, 출처를 기반으로 답변할 수 있습니다.
이는 모델이 기억에 의존하여 답변하는 것보다 더 신뢰할 수 있으며, 매번 검색 명령을 수동으로 작성하는 것보다 더 재사용 가능합니다.
참고 문서
Pi Extensions 문서
공식 확장 문서, TypeScript를 사용하여 도구, 명령, UI 및 이벤트 훅을 등록하는 방법을 소개합니다.
Pi 사용 문서
공식 사용 문서, 대화형 모드, 슬래시 명령, 세션, 컨텍스트 파일, CLI 옵션 및 설계 원칙을 다룹니다.