Skill-Creator 심층 분석: 데이터를 사용하여 기술 개발을 촉진합니다.
Anthropic의 공식 "메타 기술" Skill-Creator에 대한 심층 분석 - Claude Code 기술을 체계적으로 생성, 테스트, 평가 및 최적화하여 기술 개발을 직관 중심에서 데이터 중심으로 전환하는 방법
소개
이 문서는 2026년 3월 정보를 기반으로 하며 Claude Code v2.1+에 해당합니다.
개념과 연습을 읽었다면 SKILL.md 파일을 수동으로 작성하는 방법을 이미 알고 있어야 합니다. 머리말을 정의하고 명령을 작성하고 .claude/skills/ 디렉터리에 저장하면 끝입니다.
하지만 여기에 근본적인 질문이 있습니다. **당신의 기술이 정말 유용하다는 것을 어떻게 알 수 있나요? **
단락의 문구를 변경하여 더 잘 작동한다고 느낄 수도 있지만 이는 주관적인 느낌일 뿐입니다. 어쩌면 다른 프롬프트 단어를 사용하면 새 버전이 더 나쁠 수도 있습니다. 어쩌면 당신의 기술은 미숙련에 비해 전혀 향상되지 않을 수도 있습니다. Claude는 혼자서도 잘 할 수 있습니다.
개념장과 실무장에서는 기술 개발 과정을 작성 → 시도 → 느낌 있음 → 온라인 순으로 진행합니다. 모든 과정은 직관에 의존하고, 정량화도 없고, "이 기술이 전혀 기술이 없는 것보다 얼마나 더 나은가?"라고 답할 방법이 없습니다. 그리고 Skill-Creator는 이것을 엔지니어링으로 전환했습니다. 작성 → 스킬 유무 병렬 테스트 → 블라인드 테스트 A/B 비교 → 정량 채점 → 피드백 반복 → 데이터 검증.
The skill-creator turns skill creation from art into engineering — you can now test, measure, and systematically improve your skills instead of relying on intuition alone.
이것이 Skill-Creator가 존재하는 이유입니다. "SKILL.md 생성"에 도움이 될 뿐만 아니라 생성 → 테스트 → 평가 → 최적화 루프의 전체 세트를 제공하여 데이터가 스스로 말할 수 있도록 해줍니다.
스킬크리에이터란?
Anthropic에서 공식적으로 제공하는 "메타 스킬" - 다른 스킬 을 생성, 테스트 및 최적화하는 데 특별히 사용되는 스킬 입니다. 내장된 평가 프레임워크, 블라인드 테스트 비교, 설명 최적화 및 기타 기능을 갖추고 있으며 기술 개발을 "작성하고 시도"에서 "데이터 기반 반복 엔지니어링"으로 업그레이드합니다.
Improving skill-creator: Test, measure, and refine Agent Skills
The official blog post announcing skill-creator improvements with eval, improve, and benchmark capabilities.
Skill-Creator 자체도 스킬입니다. 33KB SKILL.md 파일과 하위 에이전트 지침 파일, Python 스크립트 및 HTML 뷰어를 지원합니다. 디렉토리 구조는 다음과 같습니다:
skill-creator/
├── SKILL.md # 主指令文件(486 行)
├── agents/ # 子代理指导
│ ├── grader.md # 评分代理
│ ├── comparator.md # 盲测对比代理
│ └── analyzer.md # 分析代理
├── eval-viewer/ # 评估结果查看器
│ ├── generate_review.py
│ └── viewer.html
├── assets/
│ └── eval_review.html # 触发评估审查界面
├── scripts/ # Python 工具脚本
│ ├── run_eval.py # 运行触发评估
│ ├── run_loop.py # 优化循环
│ ├── improve_description.py # 描述优化
│ ├── aggregate_benchmark.py # 聚合基准测试
│ ├── package_skill.py # 打包为 .skill 文件
│ └── quick_validate.py # 快速校验
└── references/
└── schemas.md # JSON Schema 定义설치도 매우 간단합니다.
# 通过 Claude Code 插件市场
/plugins # 然后搜索 skill-creator 安装
# 或通过 skills.sh
npx skills add anthropics/skills -- skill skill-creator이것을 다시 따르십시오: 기존 기술을 평가하고 최적화하십시오.
내가 실제로 사용하는 스킬을 활용하여 Skill-Creator의 전체 과정을 살펴보겠습니다. 저는 Claude Code 플러그인 마켓 yux-claude-hub을 운영하고 있습니다. 여기서는 yux-video-summary 스킬을 사용하여 비디오 자막을 구조화된 요약으로 변환합니다. 이는 중국어 및 영어 언어 감지, DUAL_FILE/SINGLE_FILE 두 가지 출력 모드, 필러 단어 정리 등을 지원합니다. 스킬의 SKILL.md는 다음과 같습니다.
---
name: yux-video-summary
description: Transform a video transcript file into a structured,
organized summary with key points, timeline, and cleaned transcript.
Use when the user has a transcript file and wants it summarized.
allowed-tools: Read, Write, Glob, Grep
---스킬은 작성되어 있지만 실제로 유용한지 어떻게 알 수 있나요? ** Skill-Creator가 등장하는 곳입니다.
Skill-Creator 소스 코드에는 중요한 작성 원칙이 있습니다. "모든 것 뒤에 있는 이유를 설명하기 위해 열심히 노력하십시오. ALWAYS 또는 NEVER를 모두 대문자로 쓴다면 이는 노란색 플래그입니다. 추론을 재구성하고 설명하십시오." 의미: 좋은 스킬은 엄격한 규칙을 쌓기보다는 이유를 설명해야 합니다**.
1단계: 테스트 케이스 생성 및 평가 실행
핵심 질문: **이 기술이 전혀 기술이 없는 것보다 정말 나은가요? **
Claude Code를 열고 다음을 직접 입력하세요.
Use the skill creator to create evals for the yux-video-summary skillSkill-Creator는 먼저 스킬 정의와 스키마를 읽은 다음 자동으로 테스트 케이스와 정량적 주장을 생성합니다. 내 실행에서는 3개의 테스트 사례와 39개의 어설션이 생성되었습니다.

테스트 케이스를 임의로 컴파일하지 않는다는 점에 유의하십시오. 스킬에 정의된 DUAL_FILE 및 SINGLE_FILE의 두 가지 출력 모드를 이해하고 특히 다양한 비디오 유형(자습서, 팟캐스트 인터뷰, 기술 공유) 및 언어 조합을 다루는 시나리오를 설계합니다. Assertions의 디자인도 매우 특별합니다. 언어 감지, 출력 모드 선택, 콘텐츠 품질, 중국어 및 영어 필러 단어 정리에 이르기까지 제가 직접 테스트하려는 것보다 훨씬 더 포괄적입니다.
Skill-Creator의 맥락에서 Eval은 기술의 체계적인 테스트 을 참조합니다. 각 평가에는 테스트 프롬프트(프롬프트), 예상 출력 설명 및 정량적 주장(어설션)이 포함되어 있습니다. 시스템은 숙련된 버전과 비숙련 버전을 동시에 실행한 다음 결과를 비교합니다.
그런 다음 시스템은 각 테스트 사례에 대해 with_skill(스킬 로딩) 및 without_skill(기준, 스킬이 로드되지 않음)에 대해 두 개의 독립적인 하위 에이전트를 동시에 시작합니다. 6개의 병렬 에이전트(3개의 테스트 사례 × 2개의 버전)가 동시에 시작되었으며, 각각은 서로 간섭하지 않고 독립적인 작업 트리에서 실행되었습니다.
Anthropic의 PDF 기술은 이전에 채울 수 없는 양식을 처리하는 데 문제가 있었습니다. Claude는 필드를 정의하지 않고 정확한 좌표에 텍스트를 배치해야 했습니다. 오류 지점은 Eval을 통해 격리되었으며, 이후 팀에서는 위치 지정 로직을 수정했습니다. 이것이 Eval의 가치입니다. "무언가 옳지 않다고 느껴지는 것"을 "여기서 정확히 잘못된 것"으로 바꾸는 것입니다.
2단계: 하위 에이전트 3명 릴레이 점수 매기기
모든 작업이 완료되면 세 명의 전문 하위 에이전트가 자동으로 순서대로 나타납니다.
Grader 어설션을 하나씩 확인합니다. with_skill 버전의 요약에 개요 테이블이 포함되어 있는지, DUAL_FILE 모드가 올바르게 선택되었는지, 필러 단어가 정리되었는지 여부를 확인한 다음 각 항목의 통과/실패 및 증거를 기록하여 grading.json을 생성합니다.
{
"expectations": [
{ "text": "摘要包含 Overview 表格", "passed": true, "evidence": "Found overview table with Type, Duration, Language fields" },
{ "text": "正确选择 DUAL_FILE 模式", "passed": true, "evidence": "Generated separate summary and transcript files" },
{ "text": "filler 词已清理", "passed": false, "evidence": "Found 'you know' in transcript line 42" }
],
"summary": { "passed": 2, "failed": 1, "total": 3, "pass_rate": 0.67 }
}비교기는 블라인드 A/B 비교를 수행합니다. 두 개의 요약을 수신하지만 어느 것이 스킬 버전이고 어느 것이 기준 버전인지 알 수 없습니다. 'Output A'와 'Output B'만 보고 자체 품질 기준에 따라 독립적으로 판단하여 승자를 결정합니다.
Comparator 하위 에이전트가 두 출력을 비교할 때 은(는) 어느 것이 스킬 버전의 것인지, 어느 것이 기준 버전 의 것인지 알 수 없습니다. "Output A"와 "Output B"만 보고 생성된 품질 기준에 따라 독립적으로 판단하여 최종적으로 승자와 동점을 결정합니다. 이 설계는 평가 편향을 제거합니다.
Analyzer는 위의 결과를 결합하여 진단을 내립니다. 기술 여부에 관계없이 어떤 주장이 통과되었는지(이 주장은 차별화가 없으며 더 나은 주장으로 대체되어야 함을 나타냄), 어떤 결과가 높은 분산을 가지고 있는지(테스트가 불안정함), 시간과 토큰 간의 균형이 무엇인지 진단합니다. 마지막으로 개선을 위한 제안을 제시합니다.
3단계: 평가 뷰어에서 결과 검토
채점이 완료되면 Skill-Creator가 자동으로 브라우저에서 HTML 뷰어를 엽니다.
출력 탭 각 테스트 사례의 출력을 하나씩 볼 수 있습니다. 하단에 피드백 텍스트 상자가 있습니다. "요약에 타임라인이 부족합니다", "필러 단어가 정리되지 않았습니다" 등 충분하지 않다고 생각되는 내용을 적어보세요. 모든 사용 사례를 읽은 후 모든 리뷰 제출을 클릭하면 피드백이 feedback.json에 저장됩니다.
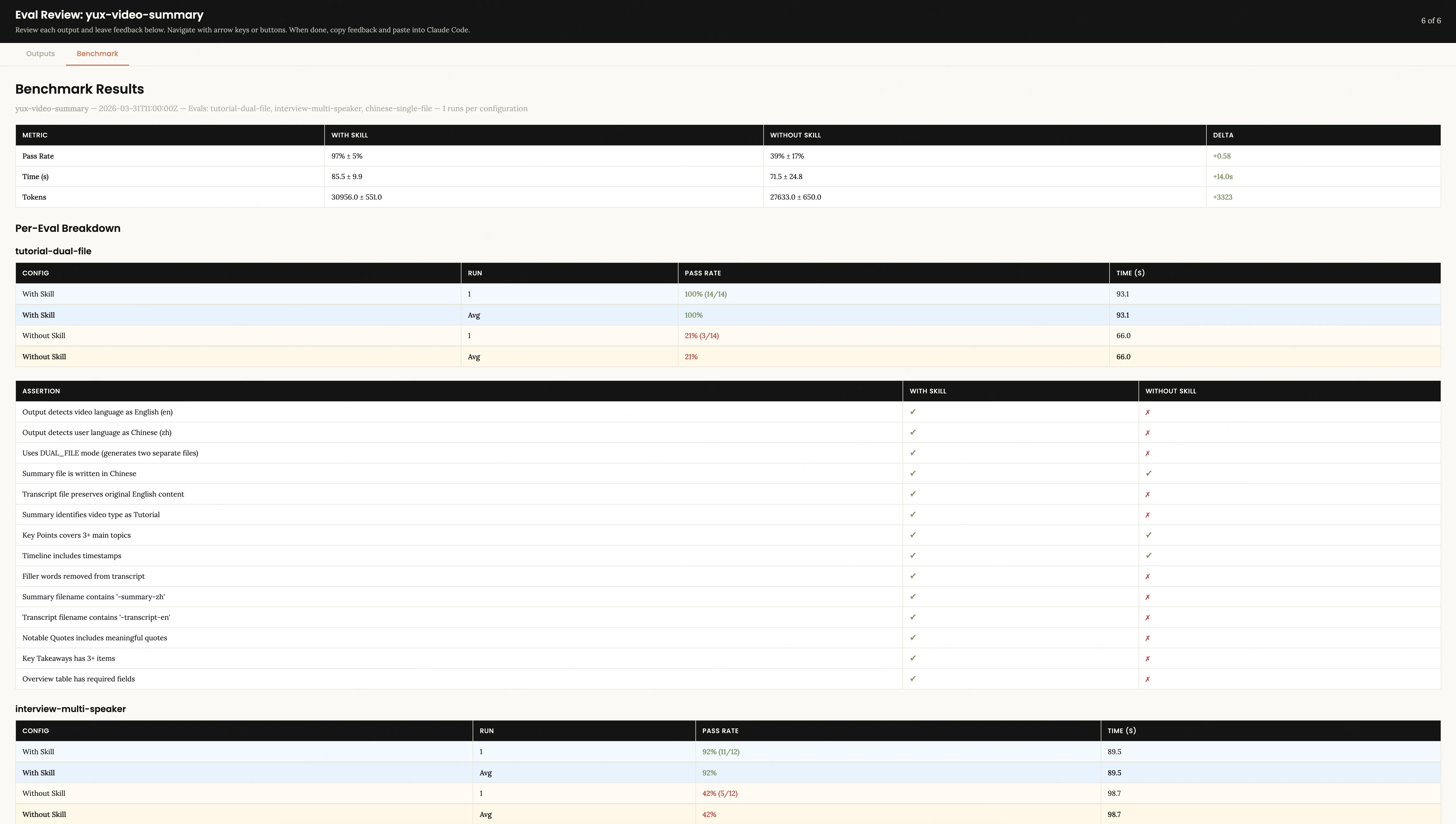
벤치마크 결과 탭 with_skill과 Without_skill의 합격률, 시간 소모량, 토큰 소모량, 각 Assertion의 항목별 비교 등 정량적 비교를 확인할 수 있습니다.
4단계: 만족할 때까지 반복 및 개선
Claude Code로 돌아가서 피드백 제공을 마쳤다고 알려주세요. Skill-Creator는 feedback.json을 읽고 벤치마크 데이터를 기반으로 분석 및 개선 제안을 제공합니다.

제 실력은 97%의 합격률로 좋은 성적을 거두었습니다. Skill-Creator는 작은 문제를 정확하게 식별했습니다. 인터뷰 영상에 주목할만한 인용문 단락이 부족하여 수리를 제안했습니다.
핵심은 개별 테스트 사례를 패치하지 않는다는 것입니다. 피드백을 일반화하고, 그 뒤에 있는 요구 사항을 이해하고, 기술의 전체 구조를 조정한 다음 SKILL.md를 다시 작성하고, 모든 테스트를 iteration-2/ 디렉터리에 다시 실행하고, 두 라운드의 출력을 비교할 수 있도록 새 Eval Viewer를 엽니다. 이 주기는 귀하가 만족할 때까지 계속됩니다.
Skill-Creator 소스 코드의 주목할 만한 개선 철학: "우리는 다양한 프롬프트에서 백만 번 사용할 수 있는 기술을 만들려고 노력하고 있습니다. 까다로운 문제가 있는 경우에는 지나치게 과적합된 변경 사항이나 억압적으로 제한하는 MUST를 적용하는 대신 분기하고 다른 비유를 사용해 보십시오." 핵심 아이디어: 과적합을 방지하여 테스트 사례를 피하고 일반화 기능을 추구합니다.
5단계(선택 사항): 스킬이 적시에 발동되도록 설명을 최적화합니다.
스킬의 품질은 검증되었지만 간과하기 쉬운 또 다른 문제가 있습니다. 스킬의 description 필드에 따라 Claude가 언제 호출할지 결정됩니다.
입력:
Use the skill creator to optimize the description for yux-video-summarySkill-Creator는 약 20개의 평가 쿼리를 자동으로 생성하고(절반은 트리거되어야 하고 나머지 절반은 트리거되지 않아야 함) 브라우저에서 검토 인터페이스가 열립니다.
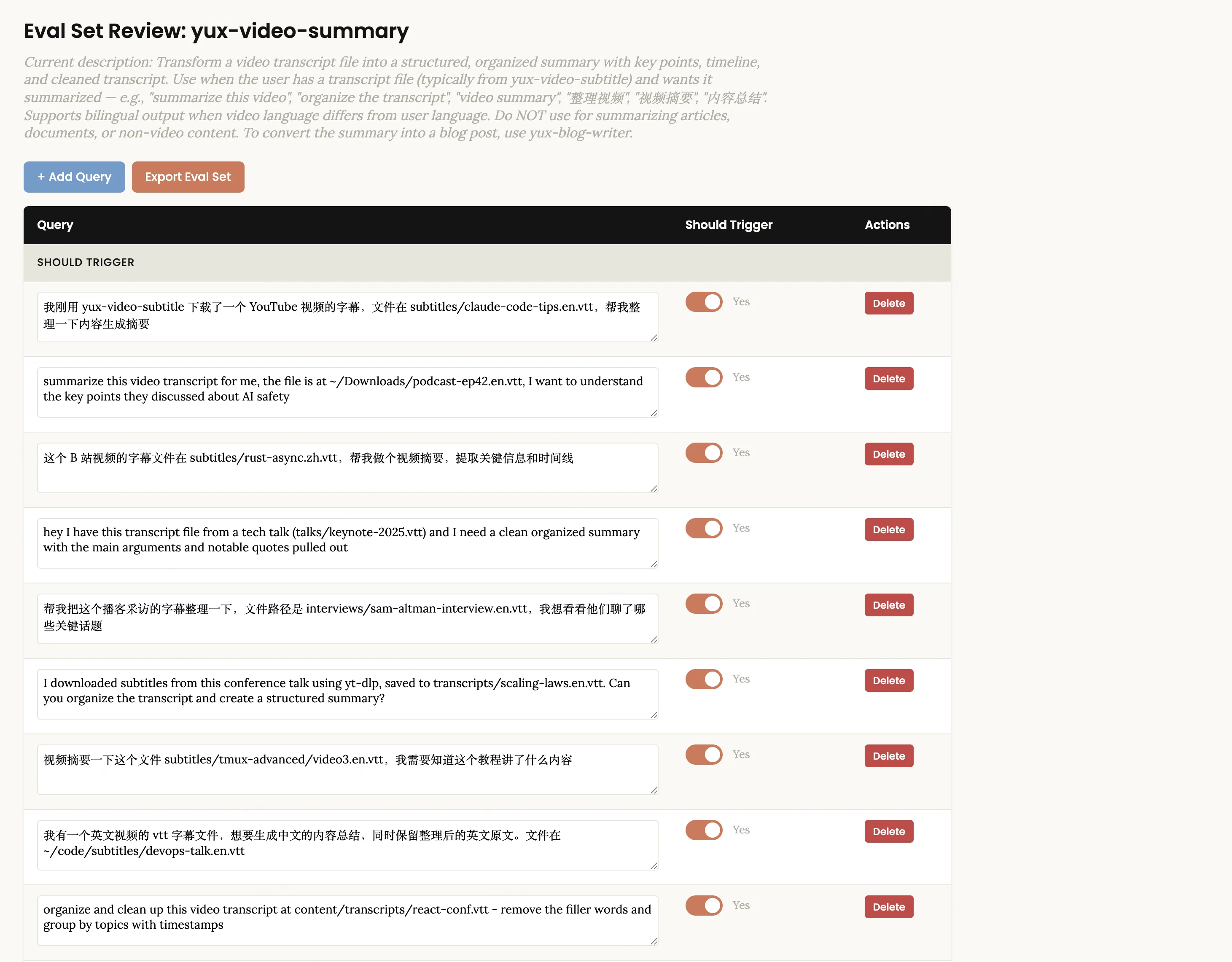
이러한 쿼리는 중국어와 영어로 제공되며 다양한 실제 표현을 포괄합니다. "트리거하면 안 됩니다"라는 쿼리는 너무 터무니없어서는 안 됩니다. 좋은 반례로는 "이 회의록을 요약하는 데 도움을 주세요."가 있는데, 이는 비디오 요약과 "요약"이라는 키워드를 공유하지만 실제로는 비디오 요약보다는 문서 처리 기술이 필요합니다.
페이지에서 직접 쿼리 텍스트를 편집할 수 있고, + 쿼리 추가를 클릭하여 새 쿼리를 추가하고, 삭제 버튼을 사용하여 부적절한 텍스트를 삭제하고, 각 쿼리에 대해 트리거해야 함 스위치를 전환할 수도 있습니다. 올바른지 확인한 후 Export Eval Set을 클릭하여 JSON 파일을 내보냅니다. Claude Code로 돌아가서 내보냈다고 알려주세요. 시스템은 백그라운드에서 최적화 루프를 자동으로 실행합니다.

전체 프로세스는 완전히 자동화되어 있습니다. 쿼리를 훈련 세트와 테스트 세트 60/40으로 분할하고, 훈련 세트에 대한 설명을 반복적으로 최적화하고(최대 5라운드), 테스트 세트 결과를 사용하여 과적합을 방지하는 최상의 버전을 선택합니다. 실행 후 최적화 전후의 설명 비교가 출력됩니다.

최적화된 설명은 더욱 구체적입니다. 즉, 지원되는 파일 형식(.vtt/.srt)을 명확하게 하고 파이프라인 기능(필러 정리, DUAL/SINGLE_FILE 논리)을 강조하고 MUST USE를 사용하여 트리거되어서는 안 되는 시나리오를 제외합니다. Anthropic은 내부적으로 이 최적화 도구 세트를 사용하여 자체 문서 생성 기술을 실행했습니다. 그 결과, 퍼블릭 스킬 6개 중 5개 발동 정확도가 향상되었습니다.
고급 사용법: 동적 컨텍스트 주입
스킬을 로드할 때 자동으로 컨텍스트를 삽입하려면 Skills 2.0의 ! 구문을 사용하여 SKILL.md에 셸 명령을 포함할 수 있습니다.
## Project Context
File tree: !`find . -type f -not -path '*/node_modules/*' | head -50`
Package info: !`cat package.json 2>/dev/null || echo "No package.json"`
Recent commits: !`git log --oneline -10`이러한 명령은 Claude가 스킬을 보기 전에 실행되며 데이터는 프롬프트에 직접 포함됩니다. Claude가 파일을 하나씩 탐색하도록 하는 것과 비교하면 많은 시간과 토큰이 절약됩니다.
두 가지 유형의 스킬: 어떤 것을 만들어야 할까요?
Skill-Creator를 사용하기 전에 Anthropic이 정의한 두 가지 스킬 유형을 이해하는 것이 필요합니다.
능력향상형 - 이전에는 모델이 할 수 없거나 잘 할 수 없었던 일을 모델이 하게 하세요. 예를 들면:
- 이미지 생성 스킬 : 클로드는 기본적으로 이미지를 생성할 수 없지만, 스킬을 통해 나노배너 등의 도구를 호출하면 달성할 수 있습니다.
- 프론트 엔드 디자인 기술: 기본 AI 디자인은 종종 매우 "AI 취향"이며, 좋은 디자인 기술은 품질을 크게 향상시킬 수 있습니다.
코딩 기본 설정 - 특정 작업 흐름을 강화하세요. 모델에는 이미 개별 기능이 있지만 정확한 실행 순서가 필요합니다. 예를 들면:
- PR 리뷰 스킬: 정해진 절차에 따라 코드 보안을 점검하고 위험도 보고서 출력
- 영상 요약 스킬 : 특정 템플릿 구조에 따른 출력, 자동 언어 감지 및 필러 단어 정리
이 두 가지 유형의 기술을 테스트해야 하는 이유는 다릅니다. 역량 개선 유형은 모델이 발전함에 따라 불필요해질 수 있습니다. - 기준(without_skill)도 모든 어설션을 통과할 수 있다면 모델이 충분히 기본적이며 이 기술이 폐기될 수 있음을 의미합니다. 코딩 유형은 내구성이 더 좋지만 실제로 작업 흐름에 충실한지 확인해야 합니다.
Skill-Creator의 평가 기능을 사용하면 오래되었을 수 있는 기술을 맹목적으로 사용하는 대신 기술이 여전히 가치가 있는지 지속적으로 확인할 수 있습니다.
커뮤니티의 의견
Skill-Creator 업데이트는 X/Twitter에서 Reddit, 독립 블로그에 이르기까지 많은 논의를 촉발시켰으며 실제 피드백은 공식 문서보다 더 가치가 있습니다.
정말 유용할까요? 데이터가 말한다
가장 직접적인 질문: 기술을 추가하는 것이 기술을 추가하지 않는 것보다 정말 나은가요? ** 몇 가지 실제 측정을 통해 명확한 답을 얻을 수 있습니다.
Reddit u/hashpanak은 타이틀 생성 기술에 대한 평가를 실행했으며 _skill이 있는 경우 100% 합격률을 보였고 60%가 없는 경우에만 60%의 합격률을 보였습니다. 토큰 비용이 그만한 가치가 있는지 묻는 질문에 그는 "물론입니다. 최적화 후에 반복되는 작업을 스크립트로 변환하여 토큰을 절약할 수 있습니다."라고 대답했습니다. u/spences10은 훨씬 더 극단적입니다. 그는 250개의 샌드박스 평가를 실행하고 스킬 활성화 비율을 84%에서 100%로 높였습니다. u/Manfluencer10kultra의 댓글 섹션에서는 "이것이 표준 관행이 되어야 합니다."라고 말했습니다.
Blogger Nathan Onn이 WordPress 보안 기술을 벤치마킹했습니다. 21개의 주장이 모두 통과되었으며(기준은 90.5%에 불과) 속도가 9.9% 더 빨랐습니다. 그의 요약: "기술은 예술이었지만 지금은 공학입니다."
@0zhuxiaofeng은 실제 워크플로우의 관점에서 보다 구체적인 수치를 제공했습니다. "한 달 동안 사용한 후 가장 큰 변화는 run_eval을 통해 스킬이 스스로 점수를 매길 수 있다는 것입니다. 이제 콘텐츠 작업을 실행하는 에이전트가 각 릴리스 후 자동으로 효과를 평가하고, 불량한 스킬은 직접 제거하고 다시 작성합니다. 수동 개입이 하루 3시간에서 30분으로 단축되었습니다."
간과된 맹점: 트리거 ≠ 품질
Blogger Mager는 아무도 언급하지 않은 사각지대를 지적했습니다. 스킬은 품질 평가를 통과하지만 트리거 평가에서 실패할 수 있습니다 - 출력 품질은 매우 좋지만 결코 호출되지 않습니다. run_loop.py 최적화 3라운드 후에 그는 13/13에 대한 평가를 트리거했습니다. 핵심 통찰력: "기술 설명은 메타데이터가 아니라 학습 가능한 매개변수입니다. 실제 라우팅 동작을 최적화해야 합니다."
이는 @DrWang5257의 제안과 일치합니다. "모든 것을 한 번에 다시 작성하지 마십시오. 먼저 이를 트리거 조건, 입력 템플릿 및 실패 폴백의 세 섹션으로 나누고 단계별로 반복합니다. 이렇게 하면 업데이트 속도가 빠르고 롤오버 비율이 낮습니다."
실제 문제점
효과는 좋지만 함정도 많습니다.
- 토큰 소비량이 엄청납니다. @konghao10은 "토큰 소비가 엄청나다"고 솔직하게 말했습니다. 동시에 6개의 병렬 에이전트를 실행하는 것은 실제로 저렴하지 않습니다. Reddit u/munkymead도 "심각한 테스트를 받는 데 비용이 많이 든다"고 말했습니다.
- 스킬이 너무 많으면 싸우게 됩니다. RoboRhythms 블로거 Noah Albert는 기술이 8-10에 도달하면 문제가 발생하기 시작합니다: Claude가 출력에 대해 스스로 질문하고 더 자세한 서문을 생성하며 때때로 기술 간에 명령 충돌이 발생한다는 사실을 발견했습니다. 그러나 Reddit u/Specialist_Solid523은 다음과 같이 반박했습니다. "잘 작성되지 않은 기술은 컨텍스트만 잠식합니다. 잘 작성된 기술은 거의 항상 토큰 사용을 더 효율적으로 만듭니다."
- SKILL.md는 반복 횟수가 많아질수록 길어집니다. Reddit u/IulianHI는 반복적인 개선을 통해 스킬 파일이 계속 확장되지만 ** 실제로 작업을 수행하기 위한 컨텍스트 창을 밀어낸다**는 모순을 지적했습니다. Happy Path만 다루는 테스트 케이스는 Critical 5%를 놓치게 됩니다.
- 버전 관리가 누락되었습니다. @fengqve 님은 "스킬은 왜 버전 개념이 없나요? 너무 여러번 업데이트가 되어서 어떤 업데이트인지 설명하기 어렵습니다. "라고 불평합니다. 이는 여러 라운드의 반복 후에 특히 고통스럽습니다.
- 헤드리스 모드에는 버그가 있습니다. GitHub에는 주요 문제가 있습니다. 기술이
claude -p모드에서 트리거되지 않아 최적화 루프를 설명하는 회상이 항상 0%가 됩니다(#36570).
더 깊이 생각하기: 재귀적 자기 개선
@vista8은 관련 논문 Memento-Skills: Let Agents Design Agents를 공유했는데 댓글 영역의 누군가가 이를 정확하게 요약했습니다. "Skill의 핵심 병목 현상은 반복입니다. 첫 번째 버전을 작성하기는 쉽지만 실제 시나리오에서 더 좋게 사용하기는 어렵습니다. 이 '사용 → 평가 → 개선' 주기를 자동화할 수 있다면 Agent에 자체 진화 엔진을 설치하는 것과 같습니다."
Reddit r/ClaudeAI의 104와 유사한 스레드에서도 이 방향에 대해 논의합니다. 그러나 최고 댓글은 이에 대해 찬물을 끼얹었습니다. u/Tatrions는 다음과 같이 말했습니다. "재귀 루프는 작동하지만 어려운 부분은 언제 개선 사항을 신뢰할지 아는 것입니다. 우리는 증거 게이팅을 수행해야 한다는 것을 발견했습니다. 실패가 적어도 두 번 발생하지 않는 한 변경 사항을 커밋하지 마십시오. 그렇지 않으면 각 주기는 처음에 깨지지 않은 것을 '수정'하고 결국 더 악화됩니다."
설치 및 생태학
Skill-Creator는 Anthropic이 공식적으로 유지 관리하는 스킬 중 하나로 anthropics/skills 창고에 포함되어 있으며, 17개 이상의 생산 수준 스킬이 포함되어 있습니다.
더 넓은 Skills 생태계도 빠르게 성장하고 있습니다. skills.sh 시장은 편리한 검색 및 설치 경험을 제공하며 커뮤니티는 1,234개 이상의 에이전트 기술을 유지해 왔습니다.
The Complete Guide to Building Skills for Claude
A comprehensive 33-page guide covering skill fundamentals, planning, testing, distribution, and YAML frontmatter reference.
Claude Code Agent Skills 2.0: From Custom Instructions to Programmable Agents
A deep dive into Skills 2.0 architecture, context forking, and the programmable agent paradigm.
마지막에 쓰세요
Skill-Creator가 해결하는 핵심 문제는 다음과 같습니다. **당신의 기술이 실제로 효과적인지 어떻게 알 수 있습니까? **
그것이 없으면 기술 개발은 "쓰기 → 노력 → 괜찮은 느낌"에 의존합니다. Skill-Creator를 사용하면 다음을 수행할 수 있습니다.
- 병렬 에이전트를 사용하여 숙련된 효과와 비숙련된 효과를 모두 테스트합니다.
- 블라인드 A/B 비교를 통해 평가 편향 제거
- Eval Viewer를 통해 결과를 시각화하고 피드백을 남깁니다.
- 설명 최적화를 사용하여 스킬 발동 타이밍을 정확하게 제어
- 만족할 때까지 반복 루프를 사용하여 지속적으로 개선하세요.
이는 소프트웨어 엔지니어링의 테스트 중심 개발 개념과 일치합니다. 즉, "단순히 코드를 작성하고 실행할 수 있다고 생각하는 것"이 아니라 "테스트를 사용하여 실제로 예상대로 작동하는지 입증하는 것"입니다.
Anthropic은 공식 블로그에서 흥미로운 전망을 제시했습니다. 모델의 기능이 향상됨에 따라 SKILL.md는 "구현 계획"(Claude 방법 알려주기)에서 '사양 설명'(Claude 무엇을 알려주고 모델이 스스로 알아내도록 허용)으로 발전할 수 있습니다. Eval 프레임워크는 이 방향의 첫 번째 단계입니다. Eval은 "무엇을 해야 할지"를 설명합니다. 언젠가 이 기술 자체가 스킬이 되기에 충분하다면 Skill-Creator가 구축한 테스트 시스템은 더욱 중요해질 것입니다.
이미 기술을 사용하고 있다면 /skill-creator을(를) 사용하여 가장 많이 사용하는 기술을 평가해 보세요. 일부 기술은 실제로 전혀 기술이 없는 것보다 낫지 않다는 사실에 놀랄 수도 있습니다. 바로 여기에서 최적화가 시작됩니다.
Extend Claude with skills
Official documentation for Claude Code Skills — structure, frontmatter fields, and best practices.
관련 자료: