snarktank/ralph 実践ガイド
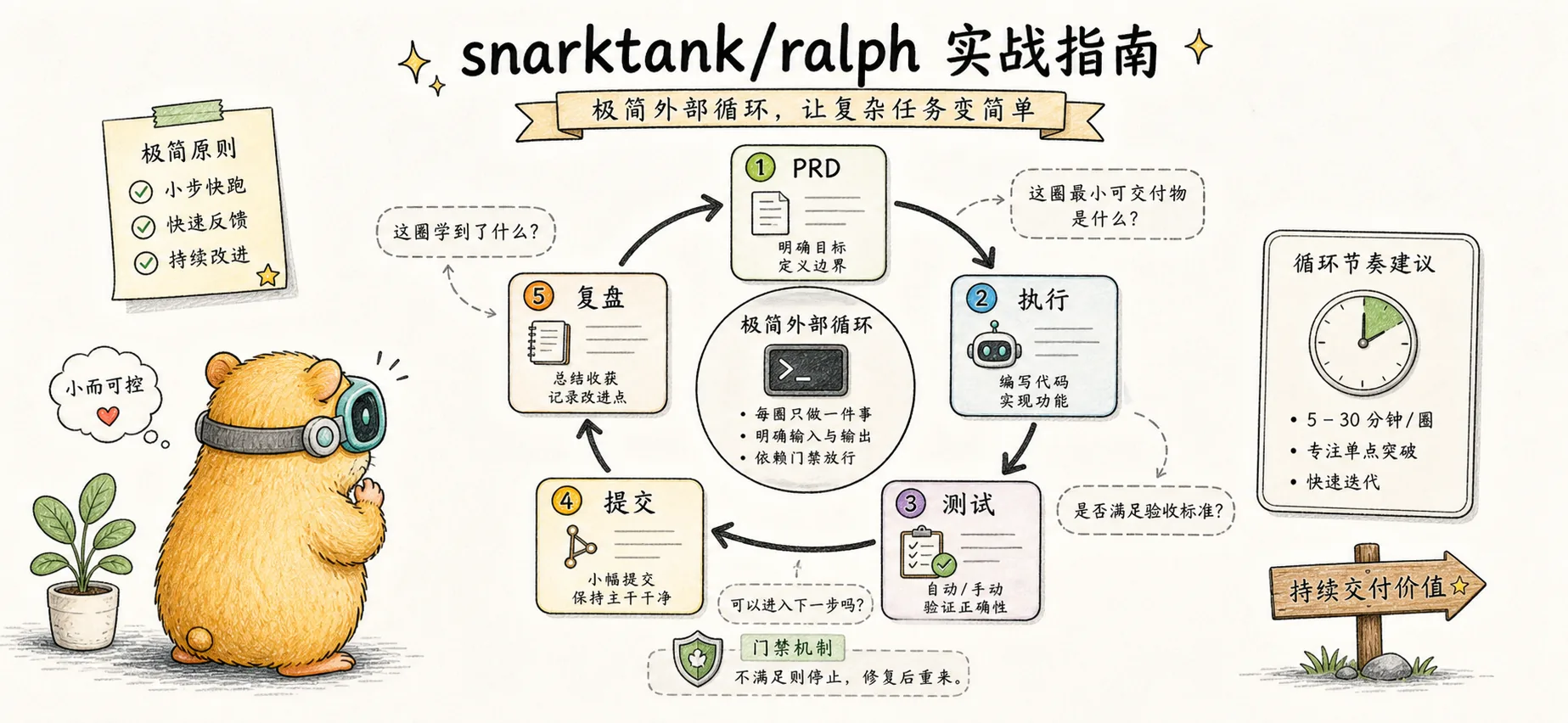
極めてシンプルな外部ループ実装:PRD作成、ループ実行、品質ゲートと経験の振り返り
はじめに
前回の記事では、Ralph のコア原理——無限ループ + 毎回新しいコンテキスト + ファイルを唯一の真実の情報源とすること——を学びました。3つの柱はシンプルに聞こえますが、理解から実際に動かすまでには多くの細かなポイントがあります。
今回は実際に手を動かしていきます。snarktank/ralph は Ralph メソドロジーの外部ループ実装です。各イテレーションで新しい Claude プロセスを起動し、Context Rot 問題を根本的に解決します。コミュニティで最も完成度の高い Ralph 実装の一つ(10k+ stars)で、Claude Code と Amp の両プラットフォームに対応し、PRD 生成、JSON 変換、自動実行のフルツールチェーンを提供しています。
もう一つの実装は frankbria/ralph-claude-code で、完全なエンジニアリングツールチェーン(モニタリングダッシュボード、サーキットブレーカー、レート制限)を提供し、制御性と安全メカニズムに重点を置いています。両者の比較はそちらの記事をご覧ください。
前提条件
始める前に、以下の環境要件を満たしていることを確認してください:
| 依存関係 | 説明 |
|---|---|
| AI プログラミングツール | Claude Code (npm install -g @anthropic-ai/claude-code) または Amp CLI |
| jq | JSON 処理ツール(macOS: brew install jq) |
| Git | プロジェクトが Git リポジトリである必要があります |
# 依存関係の確認
claude --version # Claude Code CLI
jq --version # JSON 処理
git --version # Gitインストールと設定
最も簡単な方法は、Claude Code の会話で GitHub リンクを直接貼り付けることです:
帮我安装这个 skill:https://github.com/snarktank/ralphClaude Code が自動的にリポジトリをクローンし、skill ファイルを正しい場所にコピーします。インストール完了後、/prd と /ralph コマンドが使用可能になります。
snarktank/ralph は Marketplace インストール、手動での skill ファイルコピー、プロジェクトレベルのインストールなど他の方法にも対応しています。詳しくは GitHub リポジトリの説明 をご覧ください。
コアファイル構成
Ralph の記憶は完全にファイルシステムに依存しています。各ファイルの役割を理解することが、Ralph を使いこなすための前提です。
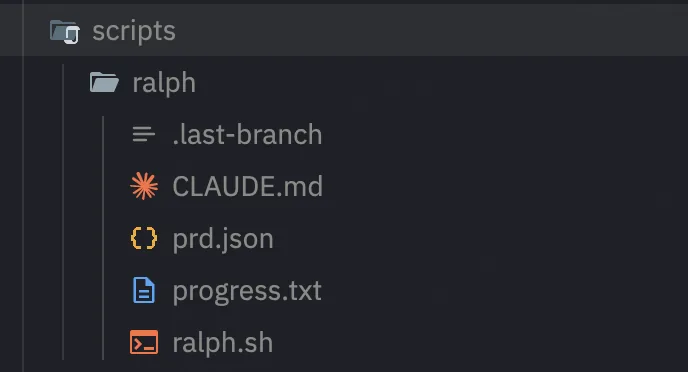
ralph.sh — ループエンジン
これが Ralph の中核です。新しい AI インスタンスを繰り返し起動する bash スクリプトです。
# 基本的な使い方
./scripts/ralph/ralph.sh [max_iterations] # デフォルトは Amp を使用
./scripts/ralph/ralph.sh --tool claude [iterations] # Claude Code を使用各イテレーションで ralph.sh は以下のことを行います:
- 機能ブランチを作成(prd.json の
branchNameに基づく) - 最も優先度の高い未完了の story を選択(
passes: false) - その story を実装するために完全に新しい AI インスタンスを起動
- 品質チェックを実行(型チェック、テスト)
- チェック通過 → git commit、失敗 → 次のイテレーションに持ち越し
- prd.json を更新し、story を
passes: trueとしてマーク - progress.txt に今回学んだ経験を追記
- すべての story が完了するかイテレーション上限に達するまで繰り返し
デフォルトのイテレーション上限は10回です。プロジェクトの複雑さに応じて調整してください:
# シンプルなプロジェクト
./scripts/ralph/ralph.sh --tool claude 10
# 複雑なプロジェクト
./scripts/ralph/ralph.sh --tool claude 50prd.json — タスク定義
これが Ralph の「頭脳」です。すべてのタスクがここで定義されます。フォーマットはフラットな JSON ファイルです:
{
"projectName": "ブログ i18n 翻訳",
"branchName": "ralph/i18n-translation",
"userStories": [
{
"id": "US-001",
"title": "トップページのメタデータを翻訳",
"description": "content/docs/meta.en.json を作成し、すべてのナビゲーション項目の英語翻訳を含める",
"acceptanceCriteria": [
"meta.en.json ファイルが存在し JSON 形式が正しい",
"すべてのナビゲーションタイトルが英語に翻訳されている",
"pnpm types:check が通過する"
],
"priority": 1,
"passes": false,
"dependsOn": [],
"notes": "既存の meta.json の構造を参考にする"
},
{
"id": "US-002",
"title": "ブログ記事 hello-world を翻訳",
"description": "content/blog/hello-world.en.mdx を作成し、中国語から英語に翻訳する",
"acceptanceCriteria": [
"hello-world.en.mdx ファイルが存在する",
"すべての QuoteCard コンポーネントに defaultLang='en' が設定されている",
"内部リンクに /en/ プレフィックスが使用されている",
"コードブロックは翻訳されていない",
"pnpm types:check が通過する"
],
"priority": 2,
"passes": false,
"dependsOn": ["US-001"],
"notes": "MDX コンポーネントの props フォーマットを維持すること"
}
]
}フィールド説明:
| フィールド | 説明 |
|---|---|
projectName | プロジェクト名、ログとブランチ命名に使用 |
branchName | Git ブランチ名、Ralph が自動作成 |
id | Story の一意識別子、US-001 形式を推奨 |
title | 簡潔なタイトル |
description | 詳細な説明、具体的であるほど良い |
acceptanceCriteria | 受け入れ基準リスト——最も重要なフィールド |
priority | 優先度の数値、小さいほど先に実行 |
passes | 完了しているかどうか、Ralph が自動更新 |
dependsOn | 依存する story ID のリスト |
notes | 追加の備考やヒント |
progress.txt — 経験ログ
これが Ralph の「長期記憶」です。各イテレーション終了後、AI がここに今回学んだ内容を追記します:
=== Iteration 1 (US-001) ===
- Discovered: typecheck command is `pnpm types:check`, not `pnpm typecheck`
- Discovered: meta.en.json needs to mirror exact structure of meta.json
- Pattern: fumadocs i18n uses `.en.` suffix convention
=== Iteration 2 (US-002) ===
- Discovered: QuoteCard requires both `quote` and `quoteZh` props
- Gotcha: internal links must use /en/ prefix for English pages
- Pattern: code blocks should never be translated次のイテレーションの新しい Claude インスタンスがこのファイルを読み取り、これまでのすべての経験を即座に取得します。これが Ralph がイテレーションを重ねるごとにスムーズに動くようになる理由です——知識はイテレーション間で蓄積されますが、コンテキストはクリーンに保たれます。
AGENTS.md — 永続化ナレッジベース
progress.txt に加えて、Ralph はプロジェクト内の AGENTS.md ファイル(または CLAUDE.md)も更新します。Claude Code と Amp はどちらも起動時にこれらのファイルを自動的に読み取ります。
progress.txt とは異なり、AGENTS.md には安定した、プロジェクト横断で汎用的な知識が記録されます:
# AGENTS.md
## Codebase Conventions
- Use fumadocs for documentation framework
- MDX files use custom components: QuoteCard, BlogImage, GlossaryCard
- i18n files use `.en.mdx` suffix
## Gotchas
- Always run `pnpm types:check` after modifying MDX files
- QuoteCard: set `defaultLang='en'` in English translationsPRD の作成
PRD(Product Requirements Document)の品質が Ralph の実行効果を直接左右します。うまく書ければ Ralph はスムーズに進みますが、書き方が悪いと同じ story で繰り返し失敗することになります。
Skill を使った PRD 生成
snarktank/ralph の skill をインストールしていれば、インタラクティブに PRD を生成できます:
# Claude Code または Amp で
/prd 我想为博客系统添加 i18n 支持,需要将所有中文内容翻译成英文AI がいくつかの確認質問(対象ファイル、技術スタックの制約、品質基準など)を行い、その後構造化された PRD ドキュメントを生成します。
生成後、/ralph コマンドで PRD を prd.json 形式に変換します:
/ralph # PRD を prd.json に変換手動での PRD 作成
prd.json を直接作成することもできます。以下が重要な設計原則です。
原則1:Story の粒度を適切にする
各 story は1回のイテレーションで完了できる程度に小さく、独立した成果物として意味がある程度に大きくすべきです。
// ❌ 大きすぎる:1回のイテレーションで完了できない
{
"id": "US-001",
"title": "完全なユーザー認証システムを構築",
"description": "登録、ログイン、パスワード忘れ、OAuth、権限管理を実装..."
}
// ❌ 小さすぎる:独立した価値がない
{
"id": "US-001",
"title": "User テーブルの email フィールドを作成",
"description": "User モデルに email フィールドを追加"
}
// ✅ 適切:1回で完了でき、独立した価値がある
{
"id": "US-001",
"title": "メール・パスワードログインを実装",
"description": "ログイン API とログインページを作成し、メール・パスワード認証に対応",
"acceptanceCriteria": [
"POST /api/auth/login が email + password を受け付ける",
"JWT token を返す",
"ログインページのフォームが送信可能",
"すべてのテストが通過する"
]
}経験則:1つの story は1〜3ファイルの修正を含み、3〜5個の受け入れ基準を持ちます。
原則2:受け入れ基準は自動検証可能であること
Ralph は story の完了を判断する必要があるため、受け入れ基準は客観的に判定できるものでなければなりません:
// ❌ 曖昧な基準
"acceptanceCriteria": [
"コード品質が良い",
"パフォーマンスが良い",
"ユーザー体験がスムーズ"
]
// ✅ 検証可能な基準
"acceptanceCriteria": [
"pnpm types:check が通過する",
"pnpm test が通過する",
"API レスポンス時間 < 200ms",
"ファイル src/auth/login.ts が存在し loginHandler 関数をエクスポートしている"
]原則3:dependsOn で順序を制御する
story 間に依存関係がある場合、dependsOn フィールドで Ralph が正しい順序で実行することを保証します:
{
"userStories": [
{
"id": "US-001",
"title": "データベーススキーマを作成",
"dependsOn": []
},
{
"id": "US-002",
"title": "ユーザー登録 API を実装",
"dependsOn": ["US-001"]
},
{
"id": "US-003",
"title": "ログインページを実装",
"dependsOn": ["US-002"]
}
]
}原則4:notes でコンテキストを提供する
notes フィールドは AI への追加ヒントです。あなたが知っていて AI が知らない可能性のある情報をここに書きましょう:
{
"notes": "プロジェクトは fumadocs フレームワークを使用。i18n ファイルの命名規則は .en.mdx サフィックス。content/docs/notes/speckit/concept.en.mdx の翻訳スタイルを参考にすること。"
}Ralph Loop の実行
PRD の準備ができたら、ループを開始しましょう。
実行の開始
# Claude Code を使用、デフォルト10回のイテレーション
./scripts/ralph/ralph.sh --tool claude
# イテレーション回数を指定
./scripts/ralph/ralph.sh --tool claude 30
# Amp を使用(デフォルト)
./scripts/ralph/ralph.sh 20実行プロセス
起動すると、以下のような出力が表示されます:
Starting Ralph - Tool: claude - Max iterations: 35
===============================================================
Ralph Iteration 1 of 35 (claude)
===============================================================
## US-001 Complete
**Summary of what was done:**
1. Created meta.en.json with all navigation items translated
2. Ran pnpm types:check — PASSED
3. Committed: feat: [US-001] - Translate homepage metadata
There are still **15 user stories with `passes: false`** remaining.
The next story is **US-002: 翻译博客文章 hello-world**.
Iteration 1 complete. Continuing...
===============================================================
Ralph Iteration 2 of 35 (claude)
===============================================================各イテレーションは完全に新しい Claude インスタンスです。prd.json を読み取って現在何をすべきかを把握し、progress.txt を読み取ってこれまでに学んだことを把握します。
完了シグナル
すべての story が passes: true としてマークされると、Ralph は完了シグナルを出力して終了します:
All stories completed!
<promise>COMPLETE</promise>モニタリングとデバッグ
Ralph の実行中、以下のコマンドで進捗を確認できます:
# 各 story の完了状態を確認(アイコン付きで直感的)
cat tasks/prd.json | python3 -c "
import json,sys
for s in json.load(sys.stdin)['userStories']:
print(f'{\"✅\" if s[\"passes\"] else \"⬜\"} {s[\"id\"]}: {s[\"title\"]}')"
# または jq で確認
cat tasks/prd.json | jq '.userStories[] | {id, title, passes}'
# 経験ログを確認
cat progress.txt
# 最近の git コミットを確認
git log --oneline -10
# Ralph の出力をリアルタイムで確認
tail -f progress.txt
# 完了後、メインブランチとの差分全体を確認
git diff main...ralph/your-branch-name --stat中断と再開
Ralph の実行は長時間になることがありますが、途中での中断は完全に安全です:
- 中断:
Ctrl+Cで直接中断できます。完了した story(passes: true)は失われません。すでに commit され prd.json に書き込まれています - 再開:同じコマンドを再度実行するだけで、Ralph は最初の
passes: falseの story から自動的に続行します
# 中断後の再開は、同じコマンドを再度実行するだけ
./scripts/ralph/ralph.sh --tool claude 35特定の story が繰り返し失敗してブロックされている場合は、手動でスキップできます。prd.json を編集して該当 story の passes フィールドを true に変更し、再度実行すると、Ralph はそれをスキップして後続の story の処理を続行します。
自動アーカイブ
新しい branchName で別の機能を開始すると、Ralph は前回の実行ファイルを archive/YYYY-MM-DD-feature-name/ ディレクトリに自動的にアーカイブし、作業ディレクトリを整理された状態に保ちます。
フィードバックループと品質ゲート
Ralph の「自己修正」能力は完全にフィードバックループの品質に依存しています。フィードバックループのない Ralph は盲目的にループするスクリプトに過ぎません。コードを生成し続けますが、そのコードが正しいかどうかを判断できないのです。
品質チェックの設定
CLAUDE.md(または prompt.md)で品質チェックコマンドを定義します:
## Quality Commands
After implementing each story, run these checks IN ORDER:
1. `pnpm types:check` — TypeScript type checking
2. `pnpm test` — Unit tests
3. `pnpm build` — Full build verification
If any check fails:
- DO NOT commit
- Fix the issue
- Re-run all checks
- Only commit when all checks pass品質ゲートの階層
| 階層 | ツール | 検出される問題 |
|---|---|---|
| 即時フィードバック | TypeScript compiler | 型エラー、構文エラー |
| 機能検証 | ユニットテスト | ロジックエラー、エッジケース |
| 統合検証 | Build コマンド | 依存関係の問題、設定エラー |
| ランタイム検証 | dev-browser skill | UI レンダリングの問題(フロントエンドプロジェクト) |
フロントエンドの story では、Ralph は受け入れ基準に「Verify in browser using dev-browser skill」を追加することを推奨しています——AI に実際にブラウザを開いてページのレンダリングが正しいことを確認させます。
品質チェックが失敗した場合
特定の story の品質チェックが繰り返し失敗しても、Ralph は同じ story を無限にリトライしません。イテレーション上限に達すると停止し、現在の状態を残します。その場合は以下の対応ができます:
- progress.txt を確認して AI がどこで詰まっているかを確認
- 手動で問題を修正してから再実行
- story の粒度を調整(大きすぎる可能性がある)
- notes に追加のコンテキストを補足
Prompt のカスタマイズ
Ralph の prompt テンプレート(CLAUDE.md または prompt.md)が AI の動作を制御する主要な手段です。インストール後、自分のプロジェクトに合わせてカスタマイズしましょう。主なカスタマイズの方向性:
コーディングスタイルの制約
## Code Conventions
- Use TypeScript strict mode
- Prefer named exports over default exports
- Use fumadocs components for MDX content
- Follow existing file naming patterns (kebab-case)よくある落とし穴
## Known Gotchas
- MDX files: always import components at the top
- i18n: English files use `.en.mdx` suffix
- Links: English pages must use `/en/` prefix
- QuoteCard: set `defaultLang` to match the file language詰まった場合の対処方法
## When Stuck
If you cannot complete a story after 3 attempts within the same iteration:
1. Document what's blocking in progress.txt
2. Move to the next story if possible
3. Do NOT modify files unrelated to the current story実践事例:Ralph でブログの i18n 翻訳を完了する
Ralph が実際のプロジェクトでどのように動作するかを示すために、ここで実際の事例を紹介します:Ralph スタイルの自律 agent を使って、ブログ全体を中国語から英語に翻訳したケースです。
プロジェクトの設定
プロジェクトでは22以上のコンテンツファイル(ブログ記事、ドキュメント、ナビゲーションメタデータ)を中国語から英語に翻訳する必要がありました。目標は fumadocs ベースの Next.js ブログでの i18n 対応です。タスクは prd.json ファイルに定義されており、16個の user story が含まれ、それぞれに明確な受け入れ基準がありました:
scripts/ralph/
├── prd.json # 16個の user story、受け入れ基準付き
└── progress.txt # 経験ログ、各 story 完了後に更新各 user story は一貫したパターンに従っています:
- 明確な成果物:"Create content/blog/xxx.en.mdx"
- 検証可能な基準:"Typecheck passes"、"Internal links use /en/ prefix"
- 技術的な制約:"Keep code blocks untranslated"、"Set defaultLang='en' on QuoteCard"
実行パターン
Agent は Ralph メソドロジーのコア原則に従いました:
-
ファイルが唯一の真実の情報源:
prd.jsonが各 story のステータス(passes: true/false)を追跡。progress.txtがイテレーション間で経験を蓄積——例えば「Typecheck コマンドはpnpm types:checkであり、pnpm typecheckではない」など -
自動化された品質ゲート:翻訳完了ごとに
pnpm types:checkを実行して MDX ファイルが正しくコンパイルされることを検証。typecheck が失敗した場合は、問題を修正してからコミット -
インクリメンタルな前進:各 story を独立してコミットし、説明的なコミットメッセージを使用(
feat: [US-003] - Translate blog/claude-code-quality-control.mdx)。必要な場合にロールバックしやすくなります -
並列実行:長い記事の場合、複数の subagent が同時に翻訳を実行——例えば US-010(claude-skills concept + practice)、US-011(speckit concept + practice)、US-012(claude-architecture + claude-subagent)が同時並行で実行
重要な学び
| 学び | 詳細 |
|---|---|
| 知識の蓄積が重要 | 初期の story で発見したパターン(QuoteCard の defaultLang、リンクプレフィックスのルール)が後続の story をより速く完了させた |
| フィードバックループとしての Typecheck | 問題が積み重なる前に、欠落した import やフォーマット不正の MDX をキャッチ |
| 並列化はスケールする | 6つの翻訳 agent が同時に実行され、完了時間は1つの場合とほぼ同じ |
| PRD の粒度が極めて重要 | 各 story を1〜2ファイルに限定——確実に完了できる程度に小さく、意味がある程度に大きく |
| 進捗ログが同じミスの繰り返しを防ぐ | progress.txt の "Codebase Patterns" セクションがナレッジベースとなり、同じ落とし穴を再び踏むことを防止 |
成果
16個の user story がすべて単一セッションで完了しました:8個の meta.en.json ナビゲーションファイルの作成、3つのブログ記事の翻訳、12個のドキュメントページの翻訳、完全なサイトビルドの検証通過。受け入れ基準が明確で、フィードバックループ(typecheck)が問題を即座に検出できたため、各翻訳は一貫した品質を維持しました。
このプロジェクトは Ralph の**完全実装モード(Full Implementation Mode)**を示しています——明確なタスク定義、明確な成功基準、自動化された検証、そしてファイルシステムを通じたインクリメンタルなデリバリーです。
ベストプラクティスとよくある質問
コスト管理
Ralph の自動実行は API コストが継続的に発生することを意味します。いくつかの制御手段があります:
- 常に
max_iterationsを設定する:これが最も基本的なセーフティネットです - Story の粒度を合理的にする:大きすぎる story は複数回のイテレーションを消費し、細かすぎる story は起動オーバーヘッドを増加させます
- まず小規模でテストする:新しいプロジェクトではまず3〜5回のイテレーションで試行し、prompt と品質ゲートが正常に機能することを確認してから本格的に実行しましょう
よくある落とし穴
落とし穴1:Story が大きすぎる
症状:1つの story が繰り返し失敗し、イテレーション回数がすぐに尽きる。
解決策:2〜3個のより小さな story に分割する。「完全な認証システムを構築」を「ログイン API の実装」+「ログインページの作成」+「JWT ミドルウェアの追加」に分割する。
落とし穴2:フィードバックループがない
症状:Ralph が story 完了を報告するが、実際にはコードに問題がある。
解決策:受け入れ基準に実行可能なチェックコマンドを含める。「コードが書けた」は受け入れ基準ではなく、「pnpm test がすべて通過する」が受け入れ基準です。
落とし穴3:progress.txt が活用されていない
症状:同じエラーが異なるイテレーションで繰り返し発生する。
解決策:prompt テンプレートに「progress.txt を読み取り、その中の経験に従う」という明確な指示があることを確認する。AI が自動的に学習内容を追記しない場合は、prompt に「After each story, append learnings to progress.txt」を追加する。
落とし穴4:依存関係の順序が間違っている
症状:ある story が依存するコードがまだ存在せず、実装が失敗する。
解決策:dependsOn フィールドを正しく設定し、インフラストラクチャの story が先に来るようにする。
よくある質問
Q: 実行中に prd.json を手動で修正して介入できますか?
できます。Ralph は各イテレーション開始時に prd.json を再読み込みします。イテレーションの合間に story の説明を修正したり、新しい story を追加したり、特定の story を手動で passes: true にマーク(スキップ)したりできます。
Q: Ralph が1つの story で繰り返し失敗する場合はどうすればいいですか?
- progress.txt で失敗の原因を確認する
- notes に追加のコンテキストを補足する
- story を分割する(粒度が大きすぎる可能性がある)
- ブロックしている問題を手動で修正してから再実行する
Q: Ralph の実行中に他のことをしても大丈夫ですか?
大丈夫です。Ralph は「Human on the Loop」として設計されています——ずっと監視している必要はありません。AFK モードで、退社前に起動して翌日結果を確認するだけで OK です。実行中は Ralph が操作しているファイルを変更しないようにしましょう。
Q: コストをどう管理すればいいですか?
3つの方法があります:合理的な max_iterations の設定、適切な story の粒度の維持(無駄なイテレーションの削減)、そしてまず小規模で試行してフローが正しいことを確認すること。一般的に、10〜20個の story のプロジェクトは $50〜100 の API コスト範囲内に収まります。
まとめ
Ralph の使用フローは5つのステップに要約できます:
インストール → PRD 作成 → 品質ゲートの設定 → ループ実行 → 成果の確認コアの考え方は常に変わりません:ファイルを唯一の真実の情報源とし、各イテレーションを完全に新しいスタートとし、品質ゲートにチェックを任せる。
さあ、自分のプロジェクトに戻って、prd.json を準備し、./scripts/ralph/ralph.sh --tool claude を実行して、コーヒーでも飲みに行きましょう。
関連記事
- 《Ralph Wiggum 詳細解説》— Ralph のコア原理を振り返る
- 《frankbria/ralph-claude-code 実践ガイド》— エンジニアリング指向の Ralph 実装:モニタリング、サーキットブレーカーと安全メカニズム
- 《GSD 詳細解説》— Ralph の上に構築された完全なコンテキストエンジニアリングシステム
- 《Claude Skills とは》— Ralph の PRD skill は Claude Skill の一つ
- 《Speckit 実践ガイド》— もう一つの構造化 AI プログラミングワークフロー