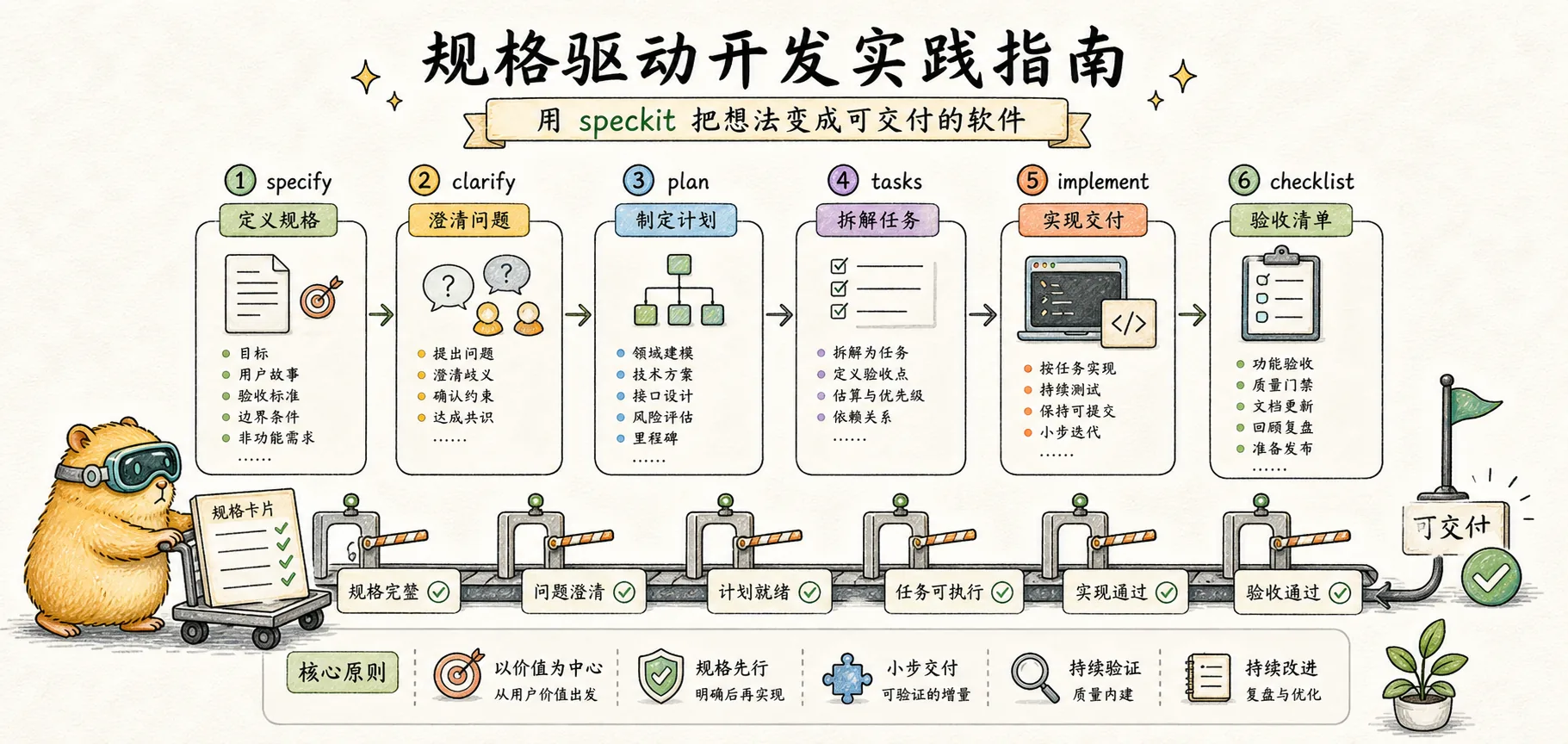
実践ガイド
speckit コマンドを使った仕様からコードまでの完全ワークフローをマスター — コマンドリファレンス、エンドツーエンドのウォークスルー、ベストプラクティス
はじめに
前回の記事では、仕様駆動開発の理念を紹介しました。「何を作るか」を先に定義してから「どう作るか」を考えるというアプローチです。一見遠回りに思えるこのプロセスですが、実際には AI プログラミングにおける手戻りやコミュニケーションコストを大幅に削減できます。
今回は実際に手を動かしていきます。speckit コマンドスイートを使って、要件定義からコード実装までの完全なワークフローを学びましょう。
インストールと設定
Speckit コマンドは GitHub 公式の Spec Kit プロジェクトに由来しています。使用シナリオに応じて、いくつかの導入方法があります。
新規プロジェクトの初期化
新規プロジェクトの場合は、公式の specify-cli ツールを使った初期化を推奨します。
# uv で specify-cli をインストール
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
# 新規プロジェクトを初期化し、AI アシスタントとして Claude を指定
specify init my-project --ai claudeこれにより、.specify/ 設定ディレクトリや関連テンプレートファイルを含むプロジェクトディレクトリ構造が自動的に作成されます。
既存プロジェクトへの導入
Speckit コマンドを使うには設定ファイルが必要です。既存プロジェクトに speckit を導入するには、specify-cli を使います。
cd your-existing-project
specify init . --ai claude # 注意:. はカレントディレクトリを意味しますこれにより、プロジェクトに以下が作成されます。
your-project/
├── .specify/
│ ├── templates/ # 仕様書、計画書などのテンプレート
│ ├── scripts/ # ヘルパースクリプト
│ └── memory/ # constitution.md
├── .claude/
│ └── commands/ # Claude Code コマンド設定
│ ├── speckit.specify.md
│ ├── speckit.plan.md
│ └── ...
└── specs/ # 機能仕様書の保存ディレクトリ初期化では既存ファイルは上書きされません。完了後、Claude Code で /speckit.* コマンドスイートが使用可能になります。
注意:speckit コマンドは Claude Code に組み込まれていません。上記の初期化手順を先に完了する必要があります。初期化せずに
/speckit.specifyを実行すると「コマンドが見つかりません」というエラーが表示されます。
コマンドリファレンス
Speckit は仕様駆動開発の各フェーズをサポートするコマンドセットを提供しています。各コマンドには明確な入力と出力があり、トレーサブルなチェーンを形成します。
/speckit.specify — 機能仕様書の作成
これはワークフロー全体の出発点です。実現したい機能を自然言語で記述すると、AI が構造化された仕様書に整理してくれます。
機能:自然言語の記述から機能仕様書を作成します
入力:機能の説明(自然言語)
出力:
specs/[番号]-[機能名]/spec.md— 機能仕様書- 新しい git ブランチ(例:
001-user-auth)
使用例:
/speckit.specify ユーザーログイン機能を追加したい。メール・パスワード認証と「ログイン状態を保持する」オプションが必要実行後、AI は以下を行います。
- 短い機能名を生成(例:
user-auth) - 新しい機能ブランチを作成
- ユーザーストーリー、機能要件、成功基準を含む仕様書を生成
- 不明確な箇所に
[NEEDS CLARIFICATION]マークを付与
仕様書の基本構造:
# Feature Specification: ユーザーログイン
## User Scenarios & Testing
### User Story 1 - ユーザーログイン (Priority: P1)
ユーザーがメールアドレスとパスワードでシステムにログインする...
**Acceptance Scenarios**:
1. Given 正しいメールアドレスとパスワードを入力, When ログインをクリック, Then システムに正常にログインできる
## Requirements
### Functional Requirements
- FR-001: システムはメール・パスワードによるログインをサポートすること
- FR-002: システムは「ログイン状態を保持する」オプションを提供すること
## Success Criteria
- SC-001: ユーザーが 30 秒以内にログインフローを完了できること仕様書には技術的な詳細は一切含まれないことに注意してください。フレームワークの指定も、データベーススキーマも、API 定義もありません。それらは後のフェーズで扱います。
/speckit.clarify — 曖昧点の解消
仕様書の作成後、まだ曖昧な部分が残っている場合があります。このコマンドは仕様書をレビューし、重要な質問をして曖昧点の解消を支援します。
機能:仕様書の曖昧点を特定し、Q&A を通じて仕様を洗練させます
入力:既存の spec.md ドキュメント
出力:更新された spec.md(明確化記録付き)
使用例:
/speckit.clarify実行後、AI は以下を行います。
- 仕様書の曖昧点をスキャン
- 優先度順に並び替え(スコープ > セキュリティ > UX > 技術詳細)
- 一度に一つずつ質問
- 回答に基づいて仕様書を更新
Q&A の例:
## Question 1: ログイン失敗の処理
**Context**: 仕様書にはユーザーログインについて記載されていますが、ログイン失敗時の処理方法が定義されていません。
**Recommended:** Option B - 5 回連続失敗後のアカウントロックはセキュリティのベストプラクティスです
| Option | Description |
|--------|-------------|
| A | エラーメッセージのみ表示、制限なし |
| B | 5 回連続失敗後、15 分間アカウントをロック |
| C | ブルートフォース攻撃防止のため CAPTCHA を使用 |
オプション文字(例:"B")で回答するか、"yes" で推奨案を受け入れるか、独自の回答を提供してください。各明確化の後、仕様書は自動的に更新され、明確化記録が追加されます。
## Clarifications
### Session 2025-12-20
- Q: ログイン失敗時の処理は? → A: 5 回連続失敗後、15 分間アカウントをロック/speckit.plan — 技術計画の生成
仕様が明確になったら、技術設計フェーズに進みます。このステップでは技術計画とリサーチレポートが作成されます。
機能:仕様書から技術実装計画を生成します
入力:spec.md ドキュメント
出力:
plan.md— 技術計画(アーキテクチャ、データモデル、API 設計)research.md— リサーチレポート(技術選定の判断根拠)data-model.md— データモデル(該当する場合)contracts/— API コントラクト(該当する場合)
使用例:
/speckit.plan Next.js + Prisma + PostgreSQL を使用コマンドの後に技術スタックの希望を追加できます。実行後、AI は以下を行います。
- 仕様書の機能要件を分析
- 関連技術のベストプラクティスを調査
- データモデルと API 構造を設計
- 完全な技術計画を作成
技術計画の主な内容:
# Implementation Plan: ユーザーログイン
## Technical Context
**Language/Version**: TypeScript 5.x
**Primary Dependencies**: Next.js 15, Prisma, PostgreSQL
**Authentication**: NextAuth.js with credentials provider
## Project Structure
src/
├── app/
│ └── (auth)/
│ ├── login/
│ └── api/auth/
├── lib/
│ └── auth/
└── prisma/
└── schema.prisma
## Data Model
- User: id, email, passwordHash, createdAt, updatedAt
- Session: id, userId, expiresAt/speckit.tasks — タスクの分解
技術計画ができたら、次はそれを実行可能なタスクリストに分解します。
機能:技術計画を実行可能なタスクリストに分割します
入力:plan.md ドキュメント
出力:tasks.md — 依存関係順にソートされたタスクリスト
使用例:
/speckit.tasks実行後、AI は以下を行います。
- plan.md から技術アプローチを抽出
- spec.md からユーザーストーリーの優先度を抽出
- ユーザーストーリーごとにグループ化されたタスクを生成
- 並列実行可能なタスクに
[P]マークを付与 - 各タスクに具体的なファイルパスを指定
タスクリストの形式:
## Phase 1: Setup
- [ ] T001 プロジェクト構造の作成
- [ ] T002 [P] Prisma schema の設定
- [ ] T003 [P] NextAuth の設定
## Phase 2: User Story 1 - ユーザーログイン (P1)
- [ ] T004 [US1] User モデルの作成 in prisma/schema.prisma
- [ ] T005 [US1] ログイン API の実装 in src/app/api/auth/[...nextauth]/route.ts
- [ ] T006 [US1] ログインページの作成 in src/app/(auth)/login/page.tsx各タスクには以下が含まれます。
- タスク ID(T001, T002...)— トラッキング用
- [P] マーカー — 他の [P] タスクと並列実行可能であることを示す
- [US] タグ — 所属するユーザーストーリーを示す
- ファイルパス — 作業対象のファイルを明示
/speckit.implement — 実装の実行
すべての準備が整いました。タスクリストの実行に移りましょう。
機能:タスクリストに従って順番にタスクを実行します
入力:tasks.md ドキュメント
出力:実際のコード
使用例:
/speckit.implement実行前に、AI はチェックリスト(存在する場合)を確認します。実行時は以下のように進みます。
- フェーズ順にタスクを実行
- 完了したタスクを
[X]でマーク - タスクの依存関係を遵守
- 並列タスクは同時に実行可能
実行の例:
Phase 1: Setup
✓ T001 プロジェクト構造の作成
✓ T002 Prisma schema の設定
✓ T003 NextAuth の設定
Phase 2: User Story 1
✓ T004 User モデルの作成
T005 実行中...実装後のレビュー
/speckit.implement の完了後、コードを直接マージしないでください。AI が生成したコードには人間によるレビューが必要です。
必須の検証ステップ:
-
テストスイートの実行
npm test # またはプロジェクトのテストコマンドAI が既存の機能を壊していないことを確認します。
-
コードレビューのチェックポイント
- コードが仕様の意図に沿っているか(spec.md と照合)
- プロジェクトのコーディングスタイルに従っているか
- セキュリティ上の潜在的な問題がないか
-
境界テスト AI が見落とした可能性のあるエッジケースを手動でテストします。
- null 値の処理
- 極端な入力
- 並行処理のシナリオ
- エラーパス
-
パフォーマンスチェック データベース操作や API コールが関係する場合、N+1 クエリなどのパフォーマンス問題を確認します。
ヒント:仕様書が十分に詳細であっても、AI は実装の細部で逸脱する可能性があります。レビューは仕様駆動開発への不信ではなく、エンジニアリング規律の一環です。
/speckit.analyze — 一貫性分析
これはオプションの品質チェックステップで、仕様書・計画書・タスク間の一貫性を検証します。
機能:ドキュメント間の一貫性と品質の分析
入力:spec.md, plan.md, tasks.md
出力:分析レポート(ファイルは変更されません)
使用例:
/speckit.analyze実行後、以下を確認します。
- すべての要件に対応するタスクがあるか
- タスクがすべてのユーザーストーリーをカバーしているか
- 用語が統一されているか
- 抜け漏れや重複がないか
その他のコマンド(オプション)
上記のコアコマンドに加えて、speckit にはいくつかの補助コマンドがあります。メインワークフローには含まれませんが、特定のシナリオで役立ちます。
/speckit.constitution — プロジェクト憲章の作成
プロジェクトの開発原則や規約を定義するために使用します。チーム全員が統一された開発標準に従うことを保証するのに最適です。
- 入力:インタラクティブな Q&A または直接提供される原則
- 出力:
.specify/constitution.mdプロジェクト憲章ファイル - ユースケース:新規チームプロジェクトの初期化、コーディングスタイルやアーキテクチャ判断の統一
/speckit.checklist — 品質チェックリストの生成
機能仕様書に基づいてカスタマイズされた品質チェックリストを生成し、実装前の品質保証に使用します。
- 入力:spec.md ドキュメント
- 出力:
checklists/ディレクトリ内のチェックリスト - ユースケース:重要な機能リリース前の品質ゲート、コードレビューの参考
/speckit.taskstoissues — タスクを GitHub Issues に変換
tasks.md のタスクを自動的に GitHub Issues に変換し、チームコラボレーションとタスク割り当てを容易にします。
- 入力:tasks.md ドキュメント
- 出力:GitHub Issues(gh CLI 経由で作成)
- ユースケース:チーム開発、スプリント計画、タスクトラッキング
ツールエコシステム
本記事で紹介した speckit コマンドは GitHub Spec Kit プロジェクトに由来しています。これに加えて、2025 年には複数の主要 AI コーディングツールが同様の仕様駆動ワークフローをサポートし始めました。
| ツール | 特徴 | 適した用途 |
|---|---|---|
| GitHub Spec Kit | 本記事で使用したツール、MIT ライセンス、Claude Code / Copilot / Gemini CLI をサポート | コマンドライン派、クロスツール連携 |
| AWS Kiro | VS Code フォーク、ビジュアルワークフロー、EARS 表記法 | GUI 派、AWS エコシステムユーザー |
| JetBrains Junie | IntelliJ エコシステム統合、Think More 推論モード | JetBrains IDE ユーザー |
| Cursor Plan Mode | 組み込みの計画フェーズ、実行計画の自動生成 | Cursor を既に使用している開発者 |
選び方:
- Claude Code、GitHub Copilot、または Gemini CLI を使用している場合は、GitHub Spec Kit を推奨します
- グラフィカルなインターフェースやビジュアルワークフローを好む場合は、AWS Kiro をお試しください
- JetBrains ユーザーの場合は、Junie の方が IDE との統合が自然です
- 既に Cursor を使用している場合は、Plan Mode が同様の計画機能を提供しています
核心的な思想は共通です。ツールはあくまで手段であり、重要なのは仕様ファースト、コードセカンドという考え方です。
エンドツーエンドのウォークスルー
実際の事例を使って、speckit の完全なワークフローを一通り見ていきましょう。
シナリオ:ブログシステムに記事ブックマーク機能を追加する
Step 1: 仕様書の作成
/speckit.specify ブログに記事ブックマーク機能を追加したい。ユーザーがお気に入りの記事を保存して、プロフィールで閲覧できるようにしたいAI が仕様書 specs/002-article-bookmark/spec.md を生成します。
# Feature Specification: 記事ブックマーク機能
## User Scenarios & Testing
### User Story 1 - 記事をブックマーク (Priority: P1)
記事を閲覧中に、ユーザーがブックマークボタンをクリックしてブックマークリストに追加する。
**Acceptance Scenarios**:
1. Given ユーザーがログイン済み, When ブックマークボタンをクリック, Then 記事がブックマークリストに追加される
2. Given ユーザーが未ログイン, When ブックマークボタンをクリック, Then ログインプロンプトが表示される
### User Story 2 - ブックマークリストの閲覧 (Priority: P2)
ユーザーがプロフィールで自分のブックマークした記事をすべて閲覧する。
## Requirements
- FR-001: ユーザーは記事をブックマーク/ブックマーク解除できること
- FR-002: ブックマークボタンは現在のブックマーク状態を反映すること
- FR-003: プロフィールにブックマークリストを表示すること
## Success Criteria
- SC-001: ブックマーク操作が 500ms 以内に完了すること
- SC-002: ブックマークリストはページネーションをサポートし、1 ページあたり 10 件表示することStep 2: 要件の明確化
/speckit.clarifyAI が質問します:「ブックマーク数に上限はありますか?」
回答:「ユーザーあたり最大 100 件のブックマーク」
仕様書が更新されます。
- FR-004: 各ユーザーのブックマークは最大 100 件まで
- 上限に達した場合に通知を表示
Step 3: 計画の生成
/speckit.plan Next.js + Prisma を使用生成された技術計画には以下が含まれます。
- Bookmark モデル(userId, articleId, createdAt)
- API ルート設計(POST/DELETE /api/bookmarks)
- コンポーネント設計(BookmarkButton, BookmarkList)
Step 4: タスクの分解
/speckit.tasks生成されたタスクリスト:
## Phase 1: Setup
- [ ] T001 Prisma schema に Bookmark モデルを追加
## Phase 2: US1 - 記事のブックマーク
- [ ] T002 [US1] ブックマーク API の作成 in src/app/api/bookmarks/route.ts
- [ ] T003 [US1] BookmarkButton コンポーネントの作成 in src/components/BookmarkButton.tsx
- [ ] T004 [US1] 記事ページへの統合
## Phase 3: US2 - ブックマークリスト
- [ ] T005 [US2] ブックマークリストページの作成 in src/app/profile/bookmarks/page.tsx
- [ ] T006 [US2] ページネーションロジックの実装Step 5: 実装の実行
/speckit.implementタスクが順番に実行され、完了するごとに [X] でマークされます。
ベストプラクティスと注意事項
Speckit を使うべきタイミング
適しているケース:
- 新機能の開発(3 つ以上のファイルに関わる場合)
- 要件が完全には明確でない場合(clarify で解消)
- 複数人での共同プロジェクト(仕様書が共通認識として機能)
- 重要な機能(トレーサビリティが必要な場合)
適していないケース:
- 単純なバグ修正
- 1 行のコード変更
- 緊急のホットフィックス
- 純粋な探索的実験
よくある落とし穴
speckit を使う際に注意すべき一般的な落とし穴がいくつかあります。
落とし穴 1:仕様が曖昧すぎる
症状:AI が生成したコードが期待と大きくかけ離れ、大幅な手戻りが必要になります。
# ❌ 曖昧な仕様
ユーザーが記事を検索できる
# ✓ 明確な仕様
- FR-001: ユーザーはタイトルのキーワードで記事を検索できること
- FR-002: 検索結果は関連度順にソートされ、1 ページあたり 10 件表示すること
- FR-003: 検索結果内で検索キーワードがハイライト表示されること
- FR-004: 検索キーワードが空の場合、トレンド記事を表示すること解決策:/speckit.clarify を実行するか、手動で機能要件と成功基準を追加してください。
落とし穴 2:仕様が詳細すぎる
症状:AI が過度に制約されて力を発揮できず、硬直したコードを生成するか、指示の一部を無視してしまいます。
# ❌ 過度に詳細(実装の詳細を指定)
lodash の debounce 関数を使用し、遅延 300ms、
useCallback でラップし、依存配列は [searchTerm]...
# ✓ 適切な詳細レベル(何をするかだけを記述)
検索入力はデバウンスし、過剰なリクエストを避けること解決策:仕様は「何をするか」のレベルに留め、「どうするか」は Plan フェーズに委ねてください。
落とし穴 3:Plan フェーズのスキップ
症状:タスクが粗すぎるか細かすぎ、実装中に頻繁な手戻りが発生し、タスク間の依存関係が混乱します。
解決策:複雑な機能では必ず Plan フェーズを完了してください。Plan は技術アプローチを策定するだけでなく、潜在的なアーキテクチャ上の問題を特定するのにも役立ちます。
落とし穴 4:レビューなしでマージ
症状:デプロイ後にエッジケースの未処理、セキュリティ脆弱性、パフォーマンス問題が発見されます。
解決策:上記の「実装後のレビュー」セクションを参照してください。マージ前に必ずテストとコードレビューを実施してください。
よくある質問
Q: すべての機能でワークフロー全体を実行する必要がありますか?
いいえ、必ずしもそうではありません。シンプルな変更はそのままコーディングに進んで構いません。複雑な機能の場合は、少なくとも specify + plan を完了することを推奨します。
Q: 仕様書はとても詳細なのに、AI が期待どおりのコードを生成しない場合は?
仕様が本当に「詳細」かどうかを確認してください。明確に書いたつもりでも、実際には曖昧な点が残っていることが多いです。/speckit.clarify を実行して、見落としがないか確認してみてください。
Q: 一部のステップをスキップできますか?
はい、可能です。最小ワークフローは specify → tasks → implement です。ただし、clarify と plan をスキップすると、後から手戻りが発生するリスクが高まります。
Q: 既に生成された仕様書を修正するには?
spec.md ファイルを直接編集するだけで大丈夫です。変更後は、一貫性を保つために plan と tasks を再実行することを推奨します。
Q: AI が生成したコードが全く間違っている場合、どうデバッグしますか?
段階的にトラブルシューティングしてください。
- 仕様を確認:仕様が本当に明確ですか?
/speckit.clarifyを実行して見落としがないか確認します - 計画を確認:plan.md の技術アプローチは妥当ですか?妥当でなければ、直接編集してタスクを再生成します
- スコープを絞る:AI にタスクを一つだけ実行させ、出力が期待に沿っているか観察します
- 制約を追加:constitution.md により明確な技術プリファレンスを追加します
Q: Plan と Tasks の間に不整合がある場合は?
/speckit.analyze を実行すると不整合を検出できます。よくある原因は以下の通りです。
- Plan を更新した後、Tasks を再生成していない
- Tasks を手動で編集したが、Plan を更新していない
- 仕様変更後、一部のドキュメントしか更新していない
解決策:spec.md を信頼できる唯一の情報源として、plan.md と tasks.md を順番に再生成してください。
Q: 機能間の依存関係はどう扱いますか?
機能 B が機能 A に依存している場合、2 つのアプローチがあります。
- 仕様を統合:A と B を同じ spec.md に記述し、AI に一括で計画させる
- 段階的に開発:まず機能 A のワークフローを完了してから、機能 B の specify を開始する
依存関係のある複数の機能を同時に開発することは推奨しません。インテグレーションの問題が発生しやすくなります。
まとめ
Speckit の核心的な価値は、プロセスを増やすことではなく、暗黙知を形式知に変えることにあります。ユーザーストーリー、機能要件、成功基準を書き出すことを求められると、「言わなくても分かる」と思っていた細部が自然と浮かび上がってきます。
このワークフローを覚えておいてください。
Specify → Clarify → Plan → Tasks → Implement
定義 明確化 設計 分解 実行各ステップが次のステップの曖昧さを減らしていきます。最終的に AI が受け取るのは、曖昧な意図の記述ではなく、明確なタスクリストです。
さあ、あなたのプロジェクトに戻って、/speckit.specify で最初の仕様駆動開発ワークフローを始めてみましょう。
参考資料
- 《仕様駆動開発とは》— 核心理念を振り返る
- 《GSD 詳細解説》— 仕様駆動の考え方を採用したもう一つのコンテキストエンジニアリングシステム
- 《Claude Skills とは》— Speckit 自体が Claude Skill の一つ