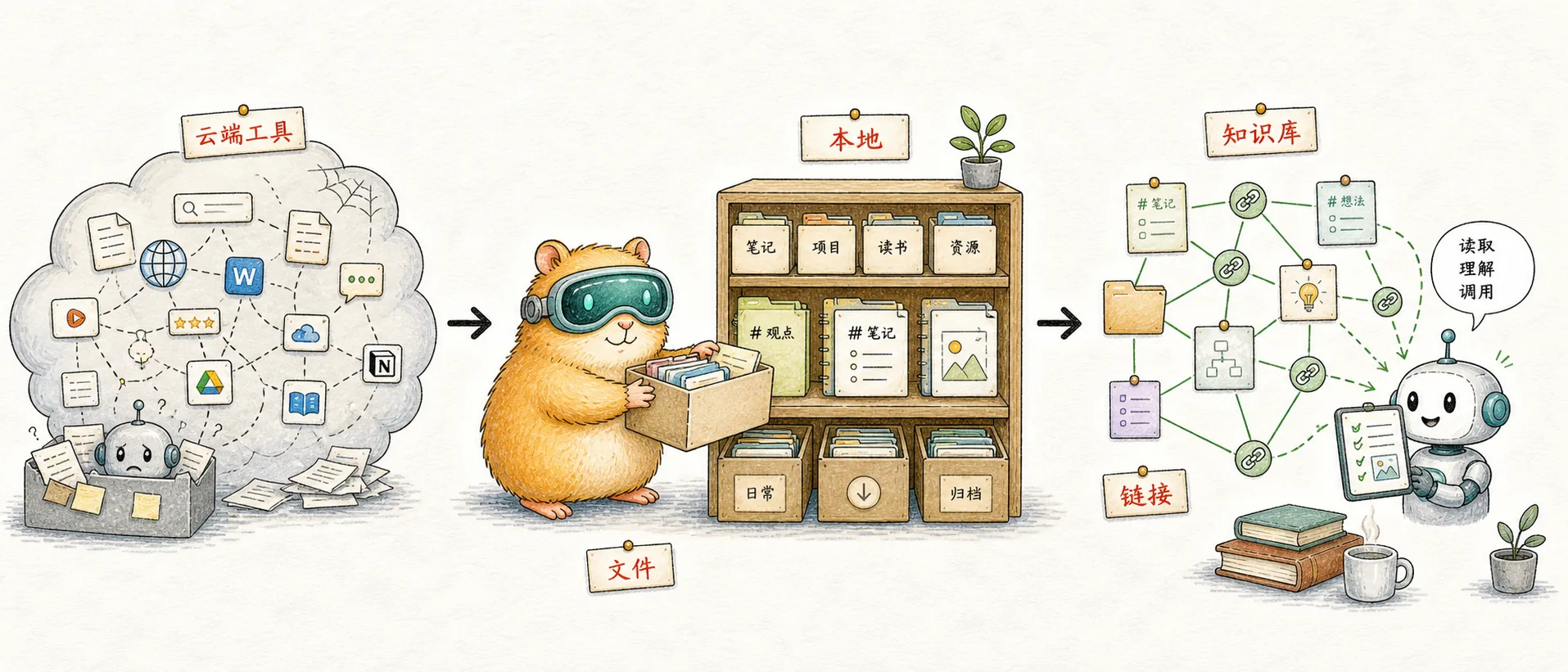
À quoi ressemble le deuxième cerveau à l’ère de l’IA ?
Le wolai que j'utilise depuis plusieurs années n'a pas été mis à jour depuis six mois et Notion ne peut pas se connecter à Claude - j'ai donc demandé à Claude Code de m'aider à construire un système de connaissances Obsidian à partir de zéro. Au bout d'un demi-mois, j'ai compris une chose : ce que Notion veut faire, c'est un système d'exploitation, et ce que je veux, c'est un système de fichiers. Ces deux choses ne sont pas le même produit en 2026.
En 2026, vos notes déterminent la quantité d'IA à laquelle vous pouvez faire appel - il ne s'agit plus seulement d'un mémo pour vous-même, mais de la mémoire à long terme de l'IA et de la « couche de contexte » entre vous et le modèle. La forme d'une note détermine si elle peut être lue, écrite, récupérée et catégorisée par Claude à vos côtés, si elle peut supporter la densité de dizaines de collaborations IA chaque jour et si elle peut continuer à s'accumuler au fil des années et des outils.
Mais les produits de prise de notes entre les mains de la plupart des gens ne sont pas conçus pour cette époque : soit le rythme ne peut pas suivre, soit les données sont enfermées dans une boîte noire SaaS, soit ils commencent à vous vendre une IA indépendante. Par conséquent, "À quoi devrait ressembler le deuxième cerveau à l'ère de l'IA" est une question qui mérite d'être repensée par tout grand utilisateur d'IA.
Voici la réponse que j'ai demandé à Claude Code de m'aider à construire à partir de zéro il y a un demi-mois. Jetons d’abord un coup d’œil à l’effet – après avoir couru pendant un demi-mois, il ressemble à ceci :
00-收件箱/ 待 triage 的临时落点
10-项目/ PARA:手头活跃的工作
20-领域/ PARA:长期关注的责任
30-资源/ PARA:参考资料库
40-原子笔记/ Zettelkasten:知识细胞(含 RAG/Agent 等主题子目录)
50-主题地图/ LYT/MOC:跨目录的主题入口
60-创作/ 创作管道:idea → outline → draft → ready → published
70-日志/ Periodic Notes:日记 / 周记 / 月记
90-归档/ 只读
99-系统/ CLAUDE.md / 模板 / 词典Le squelette n’est pas compliqué, mais il y a plusieurs motifs moins évidents cachés à l’intérieur :
- Trois ensembles de méthodologies sont fusionnés : PARA gère le temps, LYT/MOC gère l'espace et Zettelkasten gère la granularité atomique - ces trois éléments n'entrent pas en conflit et sont complets lorsqu'ils sont empilés ensemble.
- Minimal auto-construit : 1 CLAUDE.md + 2 compétences + 5 commandes slash + 6 modèles, les 95 % restants utilisent des plug-ins communautaires
- Collaboration à plusieurs niveaux avec l'IA : l'IA écrit la « couche de connaissances » (faits, collationnement) et les humains écrivent la « couche de jugement » (position, contre-exemples). Le champ
论证强度de chaque note atomique est le contrat de cette division du travail - Migration de statut = fichier mv : De l'inspiration d'une phrase à la sortie du compte public/Zhihu/Xiaohongshu, l'ensemble du processus repose sur le pilote de déplacement de fichiers entre les cinq sous-répertoires de
60-创作/ - l'approche ascendante émerge : l'ensemble de règles ci-dessus ne m'a pas été donné par Claude le premier jour de la construction - l'espace de noms
#归类/, le champ论证强度et les limites d'Auto Note Mover ont tous mis un demi-mois à se développer.
Quant à savoir pourquoi chaque note ressemble à ceci, pourquoi wolai et Notion ne m'ont pas attrapé et à quoi devraient ressembler les notes à l'ère de l'IA - l'histoire doit commencer à partir de la nuit de la mi-avril de cette année, lorsque j'étais hébété au bouton de renouvellement.
Le point de départ de l'histoire : Cette nuit d'avril
Une nuit de mi-avril, j'ai ouvert wolai – la version domestique de Notion que j'utilise depuis plusieurs années et que j'ai sauvegardé des centaines de milliers de mots – pour écrire un paragraphe de mes pensées de la journée. Le curseur a clignoté sur la page blanche plusieurs fois. Je ne me suis pas précipité pour taper. Au lieu de cela, j'ai accidentellement tiré la barre latérale jusqu'au bout et parcouru son journal de mise à jour :
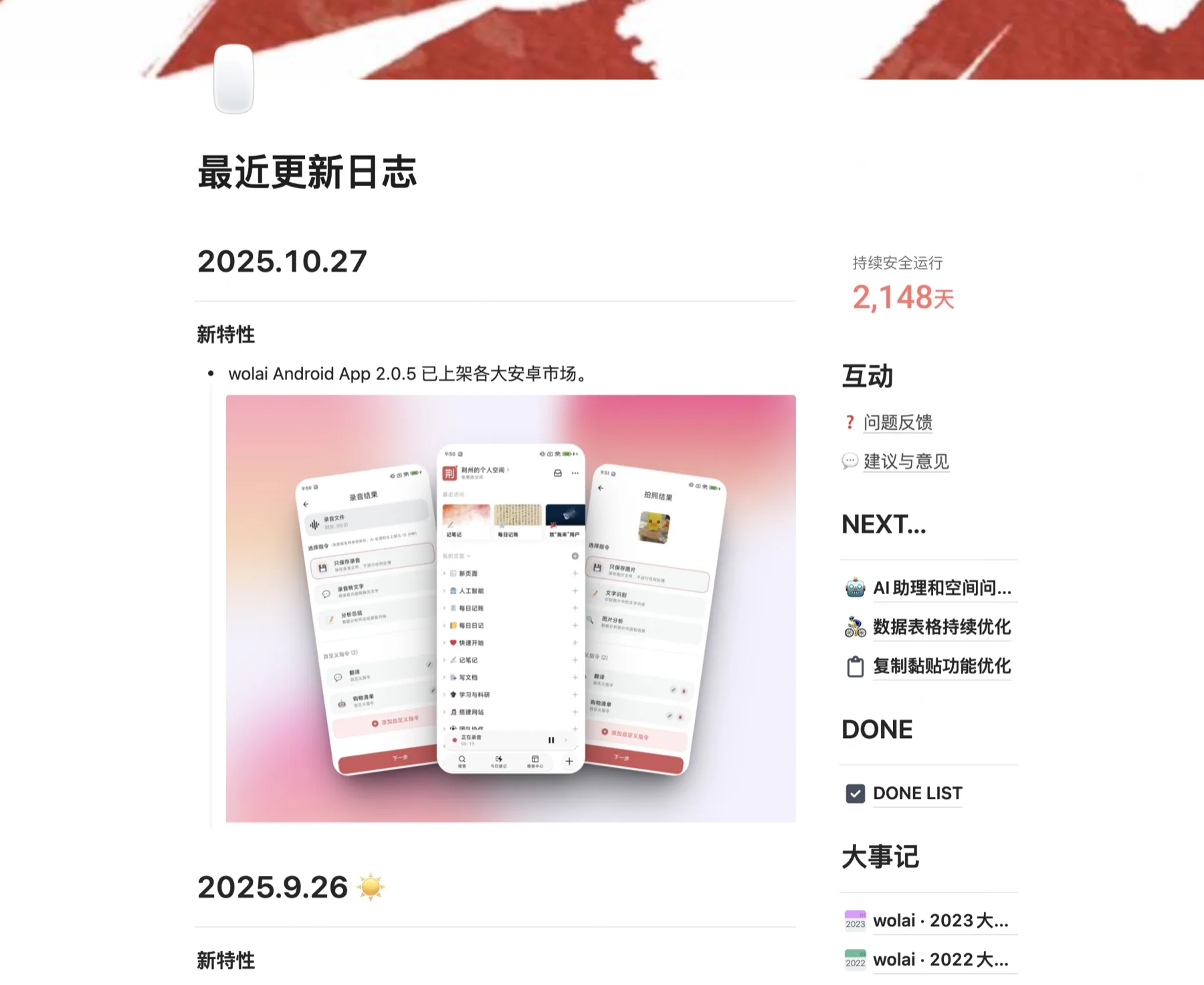
Non pas que ce soit mort – « 2 148 jours de fonctionnement continu et sûr » est vrai. Mais la dernière mise à jour s'est arrêtée en octobre 2025, et elle n'a pas été mise à jour depuis six mois ; à l'avenir, il n'y aura que quelques versions sporadiques pendant plus d'un an après mai 2024. L'ensemble du produit dégage une odeur de « sous maintenance ».
J'ai cliqué avec désinvolture sur ma page d'accueil personnelle et j'ai jeté un œil——
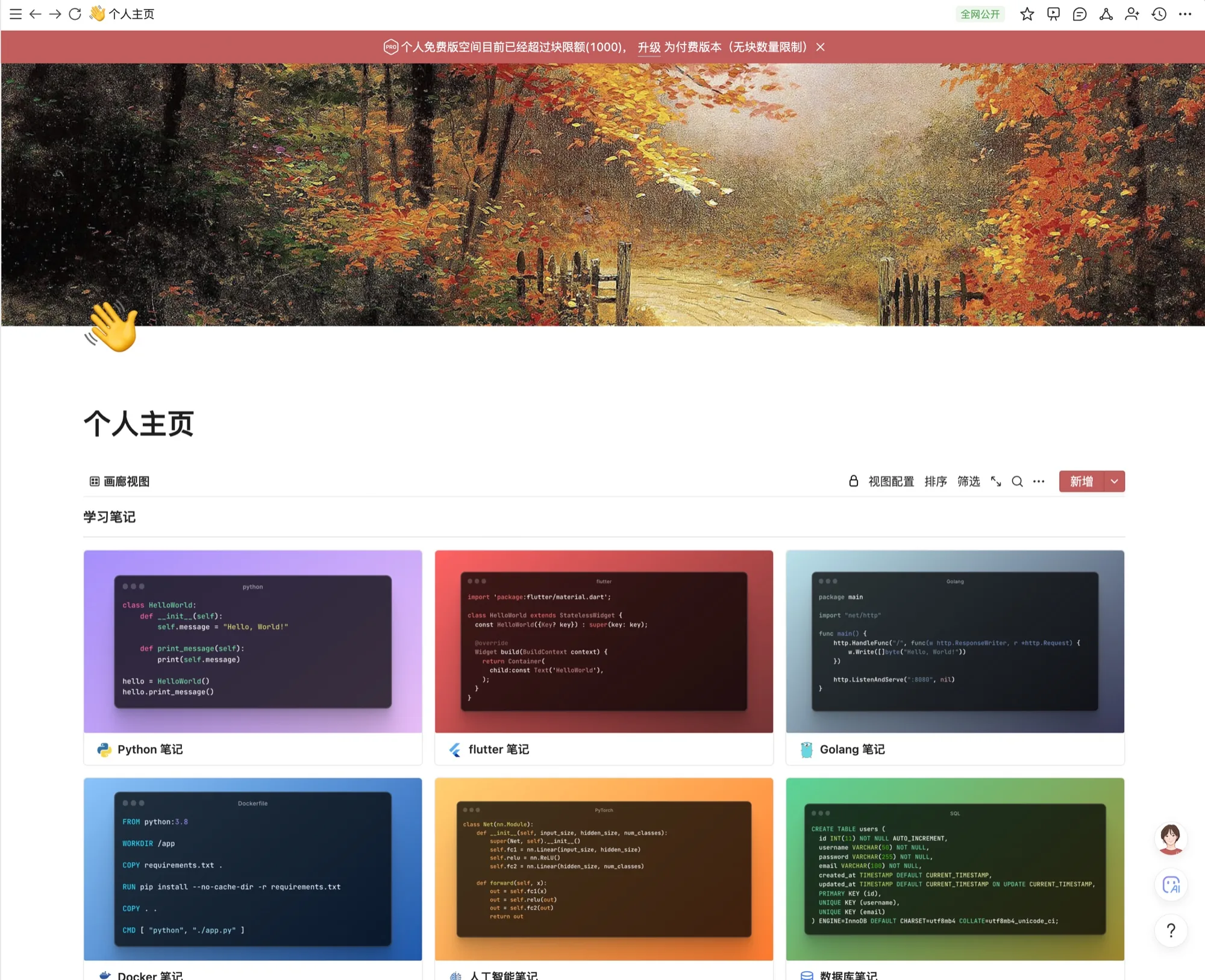
L'invite rouge en haut est suspendue - "L'espace personnel de la version gratuite dépasse actuellement la limite de blocage (1000)". La taille de mes notes a déjà dépassé le plafond de la version gratuite, mais ce qui est encore plus frappant, c'est que cette page était à l'origine "publique sur l'ensemble du réseau" - je pouvais envoyer le lien directement à mes amis il y a six mois, mais maintenant cette fonction la plus basique "partager une page publique" est également derrière un paywall.
Les mises à jour sont de plus en plus lentes et les fonctions essentielles initialement gratuites deviennent payantes : ce sont deux signaux de départ qui apparaissent côte à côte.
J'ai déplacé la souris sur le bouton de renouvellement et je l'ai éloigné.
Ce n'est pas une question d'argent. Mais je n’ai pas pris de décision immédiate ce soir-là : j’ai éloigné la souris, fermé le navigateur et suis allé prendre une douche et dormir comme d’habitude.
Ce qui m'a vraiment fait envisager sérieusement de changer d'outil, c'est une découverte qui a lentement émergé au cours de la semaine ou deux suivantes :
**Après être entré dans l'ère de l'IA, je me souviens de moins en moins de choses. **
Dans le passé, lorsque je rencontrais des détails techniques, que je marchais sur des pièges ou que je trouvais une solution non évidente lors de l'écriture de code, je l'écrivais et le laissais comme référence pour moi la prochaine fois. Bon nombre de mes centaines de milliers de mots de notes wolai ont été sauvegardés de cette façon.
Mais après avoir utilisé Claude Code, de telles notes ne sont presque plus générées - l'IA a résolu le problème et résoudra à nouveau un problème similaire la prochaine fois. Je n'ai plus besoin de « m'appuyer sur des notes pour me rappeler comment résoudre les bugs ». La nature de ce que j'ai mémorisé a tranquillement changé : des « détails de type manuel d'utilisation » à la pensée systématique, aux raisons de la prise de décision et à une ou deux idées auxquelles j'ai pensé après avoir lu un article.
Ce n’est qu’à ce moment-là que j’ai réalisé que la nature des billets avait changé, dois-je donc choisir à nouveau le support des billets ? **
J'ai décidé de ne pas renouveler le wolai lorsqu'il expirait et de trouver une base de carnet qui puisse durer dix ans. Et cette fois, j'ai demandé à Claude de m'aider à terminer ce truc - je n'ai pas l'intention de construire un système un par un tout seul, c'est trop fatigant, et je sais déjà que l'IA peut faire ce genre de chose plus vite et mieux que moi.
L'hésitation de cette nuit-là et les découvertes faites au cours de ces deux semaines m'ont poussé sur un chemin inattendu - une période d'un demi-mois pendant laquelle Claude Code m'a aidé à construire un nouveau système à partir de zéro, et une série de problèmes auxquels j'ai dû réfléchir à nouveau.
Notion ne peut pas m'attraper
Après vous être préparé à quitter le wolai, le prochain arrêt qui me vient naturellement à l’esprit est Notion. Le même montage au niveau bloc, le même multiplateforme et la même réputation auprès des programmeurs chinois. J'ai enregistré un espace de travail et je me suis préparé à le déplacer.
Le premier mur heurta rapidement. 70 % de mes notes actuelles sont écrites par Claude : je le laisse m'aider à organiser systématiquement un sujet, je le laisse transcrire une vidéo en notes structurées, je le laisse compresser un article en quelques idées de niveau atomique. Ce type de flux de travail nécessite que l’IA soit capable d’écrire des choses dans des notes aussi naturellement que d’écrire des documents. Notion a MCP, que j'ai repris avec beaucoup d'impatience.
Après l'avoir reçu, j'ai heurté le mur et j'ai atteint le troisième étage.
**Niveau 1 : lent et il faut toujours réautoriser. **
Notion MCP ne lit ni n'écrit les fichiers directement, mais regroupe chaque opération dans une requête API et l'envoie au serveur Notion, puis attend le retour de la réponse. Lorsque Claude écrit une note avec une structure légèrement plus complexe, elle doit être divisée en une douzaine d'appels d'ajout de bloc, dont chacun nécessite un aller-retour sur le réseau - presque tout le temps nécessaire à l'implémentation de la note entière est passé à attendre le serveur. Ce qui rend les gens encore plus impatients, c'est qu'il ne s'agit pas d'une autorisation unique pour une utilisation à vie. De temps en temps, une boîte de confirmation comme celle-ci apparaîtra, m'obligeant à cliquer manuellement dessus avant de pouvoir continuer :

Une tâche pour Claude consistant à trier un sujet peut être découpée en 3-4 sections, et je dois regarder l'écran et dire « D'accord, passe » pour chaque section. De plus, l'aller-retour précédent de l'API est déjà lent et l'ensemble du flux de travail est freiné par ces deux couches de friction. Obsidian n'a pas du tout ces deux couches : fichiers locaux, Claude directement Write un fichier .md, disque local IO, niveau milliseconde, pas d'intermédiaire pour hocher la tête. J'ai beau demander à Claude de modifier une dizaine de dossiers chaque jour, cet écart est infiniment amplifié.
**Niveau 2 : îlot d'abonnement IA. **
L'évolution de Notion au cours des deux dernières années est évidemment axée sur l'IA : l'écriture d'IA intégrée, les questions et réponses et les capacités de type agent se succèdent. Ouvrez notion.com et vous verrez en un coup d'œil :
Mais tout cela est redondant pour moi. Mon abonnement principal à l'IA est déjà avec Claude - Le forfait de 200 dollars de Claude Code est complet chaque jour, et les capacités, le contexte et la mémoire sont suffisants. Ce que je veux, c'est étendre les capacités existantes de Claude à la prise de notes, plutôt que de payer pour une IA indépendante pour le logiciel de prise de notes et de m'adapter à un nouveau style d'agent. Le flux de travail doit être contrôlable par moi et ne doit pas être piégé par un certain SaaS dans son écosystème d'IA.
**Niveau 3 : l'édition au niveau du bloc est obsolète. **
Notion est fier de son "édition au niveau des blocs" - il peut être glissé et déposé, intégré dans une base de données bidirectionnelle, et chaque paragraphe de texte peut être traité comme une brique Lego réorganisable - ce paradigme est avancé à l'ère du "les gens écrivent et les gens lisent". Mais lorsque mes notes sont principalement écrites par l'IA, lues par moi, et que l'IA m'aide à les récupérer et à les réviser, le blocage devient une entrave. Les manifestations spécifiques sont les suivantes : Notion utilise en interne le bloc JSON et la conversion du markdown en bloc est incomplète. Les listes imbriquées, les légendes et les balises de langage de bloc de code sont toutes déformées après leur implémentation - l'IA est difficile à écrire, j'ai des difficultés à lire et la recherche n'est pas transparente.
Mais ce qui m'a vraiment poussé à décider de l'éteindre, c'est la chose la plus importante derrière l'image ci-dessus : Notion lui-même n'est plus le "deuxième cerveau" qu'il était. Elle évolue vers Enterprise AI work platform, qui peut convenir à des clients de type Forbes Cloud 100, mais c'est trop loin de mes objectifs :
** Notion veut faire du système d'exploitation, ce que je veux, c'est le système de fichiers. ** **Ces deux choses ne sont pas le même produit en 2026. **
Je n'ai pas aimé Obsidian pendant deux ans
En fait, j'ai installé Obsidian depuis longtemps. Il a été installé il y a deux ans et l'icône est toujours sur le Dock :
Mais je n'ai jamais cliqué dessus une seule fois - la raison est qu'il n'est "pas assez au niveau du bloc" et que les fichiers sont juste des démarques, ce qui est trop "original".
Ce n’est qu’à ce moment-là que j’ai réalisé : **Toutes les choses que je n’aimais pas auparavant étaient les avantages de la prise de notes à l’ère de l’IA. **
The best file format for the future is the one you can read without the app that created it.
Kepano est le PDG d'Obsidian. Dans File over app, il évoque une vérité si simple qu'elle est presque contre-intuitive : le logiciel disparaîtra, mais les fichiers ne seront pas détruits. Notion peut mourir, et Obsidian peut mourir, mais un tas de fichiers .md sur votre disque dur ne seront pas impossibles à ouvrir car une application meurt. Les notes véritablement réutilisables à l'ère de l'IA ne sont pas la structure interne d'un SaaS, mais du texte brut + une structure de répertoires que vous pouvez contrôler.
C'est la raison fondamentale pour laquelle je me suis retiré du wolai et de Notion - la souveraineté des données.
Mais là encore, l’obsidienne seule ne suffit pas. Obsidian est un éditeur de démarques vide. Il ne vous dira pas « comment les connaissances doivent être organisées ». J'ai donc pris une décision dont j'ai été très heureux par la suite : confier toute la tâche "comment s'organiser" à Claude.
Une phrase d'exigence, un plan
J'ai ouvert Claude Code et tapé un paragraphe - plus tard, ce paragraphe a été écrit intact dans le contexte du plan de construction :
Maintenant, je veux construire mon propre système Obsidian. Jetez un œil aux projets associés et voyez s'il existe des entrepôts associés sur github. Autrement dit, je veux avoir un système, puis je peux utiliser l'IA pour gérer l'ensemble de mon système.
Je n'ai pas dit à quoi ressemble le répertoire, quels plug-ins sont nécessaires ou la méthodologie. Je n'ai dit que trois choses : Je veux un système, de préférence pas à partir de zéro, de préférence permettant à l'IA de participer en douceur.
Quelques heures plus tard, Claude m'a remis un document de proposition. J'ai lu et approuvé. À la base se trouvent cinq principes, si simples que je les ai cités encore et encore :
- Vous pouvez installer des plug-ins sans écrire de code - journal, modèle, double lien, découpage, classification automatique, la communauté dispose de plug-ins matures, tous peuvent être installés directement
- Si vous pouvez cloner, ne partez pas de zéro - un exemple de référence utilisant kepano/kepano-obsidian (le coffre-fort personnel public du PDG d'Obsidian) comme squelette de répertoire.
- MCP au lieu d'une compétence auto-écrite - utilisez le
MarkusPfundstein/mcp-obsidianprêt à l'emploi pour vous connecter à Claude Code, au lieu de recréer la capacité de base de « lire et écrire des notes » - Réutilisez la chaîne de compétences yux-* existante - J'ai déjà poli le manuscrit fini + la chaîne de compétences de publication multiplateforme (compte officiel/Zhihu/Xiaohongshu). Le nouveau système n'accepte que la première moitié de "Inspiration → Draft", et la seconde moitié est directement remise
- L'auto-construction est limitée au « jugement sémantique et à la couche d'adhésion qui ne peuvent pas être réalisés par des solutions toutes faites » - Spécification CLAUDE.md, mot d'invite de tri déclenché par l'IA, colle de connexion
Au final, la charge de travail auto-construite a été compressée à : 1 copie de CLAUDE.md + 2 compétences + 5 commandes slash + 6 modèles de modèles. 60% de moins que la première version de la solution que j'ai proposée.
Lorsque j’ai examiné ce plan, ma première réaction a été : « Cette IA sait mieux que moi faire preuve de retenue. »
La plupart des gens ne parviennent pas à construire un coffre-fort, non pas parce qu’ils ne travaillent pas assez dur, mais parce qu’ils veulent écrire eux-mêmes chaque ligne de règles. En conséquence, après trois mois, j'ai vu que la pile d'accroches et de compétences que j'avais écrites ne pouvait pas être maintenue, et l'ensemble du système a été abandonné dès que la nouveauté s'est dissipée. Claude me l'a dit dès son arrivée : 95 % des capacités sont externalisées vers l'écosystème, et les 5 % qui ne peuvent être résolues que par l'IA peuvent l'être par l'auto-construction - jugement au niveau sémantique. Cet incident en lui-même est l’un des plus grands gains de cette expérience.
Le regard de Claude
Le livrable principal que Claude m'a donné était une copie de CLAUDE.md dans le répertoire racine du coffre-fort - ce document est la "constitution" de l'ensemble du système. Il définit le langage du coffre-fort, la méthodologie, les limites des doubles scénarios, les rôles de l'IA, les règles strictes du répertoire, le frontmatter, l'espace de noms des balises... Chaque fois qu'une nouvelle session Claude Code est ouverte, il peut immédiatement prendre en charge la collaboration de l'ensemble du coffre-fort après avoir lu ce document. Ça commence comme ça :

Vous avez déjà vu le squelette au début. Je ne le publierai pas ici - ce que je veux dire n'est pas le catalogue lui-même, mais la façon dont les trois méthodologies derrière le squelette s'articulent et les deux frontières qui déterminent s'il peut être utilisé.
Derrière le squelette se cache un mélange de trois ensembles de méthodologies, chacune traitant d'une dimension :
| Méthodologie | Source | Manifestation dans le coffre-fort | Que résoudre |
|---|---|---|---|
| PARA | Tiago Forte « Construire un deuxième cerveau » | 10/20/30/90 Haut | "Qu'est-ce que je fais maintenant" - Dimension Temps |
| LYT/MOC | Nick Milo Lier votre réflexion | 50-主题地图/ | "Comment créer un lien latéral" - Dimension spatiale |
| Zettelkasten | Sönke Ahrens « Comment prendre des notes intelligentes » | 40-原子笔记/ | "Cellules du savoir" - Granularité atomique |
PARA est responsable de "comment diviser les choses que j'ai sous la main en fonction de leur exécutabilité", LYT est responsable de "comment les idées s'appellent" et Zettelkasten est responsable de "comment chaque idée est divisée en morceaux indépendants". Les trois choses ne sont pas incompatibles et elles sont complètes lorsqu’elles sont combinées : la plupart des gens n’en apprennent qu’une seule, et le résultat est que le système est toujours à la traîne.
Afin que vous ne vous contentiez pas « d'écouter ma narration », j'ai choisi la phrase la plus pointue de chacun des auteurs de ces trois méthodologies -
PARA de Tiago Forte, le jugement central du texte original sur « pourquoi ne pas classer par sujet » est :
Instead of organizing information according to broad subjects like in school, I advise you to organize it according to the projects and goals you are committed to right now.
C'est pourquoi mes 10-项目 / 20-领域 / 30-资源 / 90-归档 sont de niveau supérieur : ce sont des états d'action, pas des sujets. La catégorie de sujet « IA/Écriture/Produits » n'est qu'une balise #主题/ secondaire.
Sönke Ahrens parle de Zettelkasten dans Comment prendre des notes intelligentes. La phrase la plus citée est :
A note is only as valuable as the network it's embedded in.
La valeur d'un billet est égale à la valeur du réseau dans lequel il est intégré.
Une note atomique en elle-même n’a aucun sens ; sa valeur vient de la densité des connexions entre elle et les autres notes. C'est pourquoi dans 40-原子笔记/ j'encourage le double chaînage dense - avec chaque lien ajouté, les actifs de l'ensemble du coffre-fort augmentent en valeur.
Le LYT de Nick Milo a implémenté ce qui précède d'une manière plus technique : il s'est opposé à la "classification parfaite" codée en dur et a préconisé l'utilisation de MOC (Map of Content) comme page de répertoire vivante pour permettre à la structure de croître au cours de son utilisation. C'est exactement la logique sous-jacente de 50-主题地图/ : MOC ne remplace pas les dossiers, mais vous permet de voir toutes les notes dispersées associées dès l'entrée d'un sujet - plus lâches que les dossiers et plus structurées que les balises.
Ce qui détermine réellement si ce système peut être utilisé ou non, ce sont deux frontières qui ne peuvent être confondues :
**Article 1 : 40-原子笔记/ ≠ 60-创作/素材库/. ** Le premier est un actif intellectuel permanent - une note atomique = une idée ou un aperçu autonome qui peut être référencé n'importe où et qui devrait être lié encore et encore. Ces derniers sont des documents ponctuels - phrases dorées, cas et fragments de citations utilisés dans un manuscrit de compte public spécifique, et leur cycle de vie est égal à celui de ce manuscrit. Confondez cette frontière et, tôt ou tard, la base de connaissances sera inondée de contenu jetable.
**Article 2 : Base de connaissances ≠ création. ** 10/20/30/40/50/70 est la couche de connaissances et 60-创作/ est la couche créative. Les deux couches sont reliées par une intégration unidirectionnelle : les manuscrits peuvent utiliser ![[原子笔记#章节]] pour citer le contenu d'Atomic Notes, mais Atomic Notes ne renvoie pas aux manuscrits. Ce clapet anti-retour protège la pureté de la connaissance, de sorte qu'un blog devienne populaire ou non n'affecte pas la stabilité de la note atomique qui le sous-tend.
Le système de balises est strictement divisé en quatre catégories selon l'espace de noms :
#类型/原子— Type de structure, l'IA tape automatiquement en fonction du domaine frontal#主题/ai— Classification des thèmes, saisi manuellement#状态/待读— État temporaire, supprimer après utilisation#归类/RAG— Classification de sous-répertoire (uniquement pour40-原子笔记/), l'IA tape automatiquement par sujet
Le dernier espace de noms #归类/ n'était pas disponible le premier jour de construction - deux semaines plus tard, j'ai découvert qu'Atomic Notes avait plus de répertoires moléculaires, mais je ne voulais pas qu'Auto Note Mover réécrive toute la logique de classification, j'ai donc ouvert un espace de noms séparé spécifiquement pour la "classification secondaire d'Atomic Notes".
Je parlerai de ce détail plus tard - ce fut pour moi l'expérience la plus surprenante de cette expérience.
Comment l'utiliser au quotidien ?
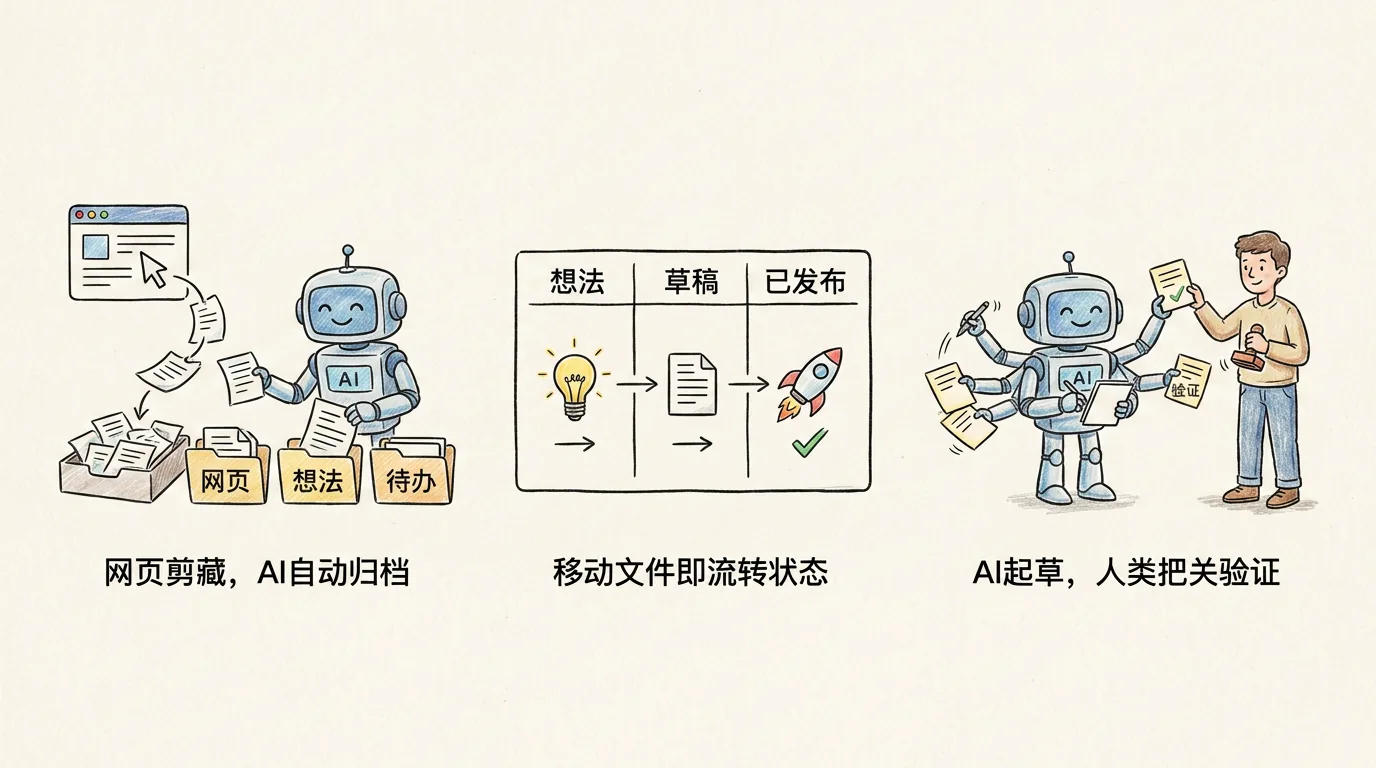
Renvoie le navigateur en un clic
Ce processus est désormais la mémoire musculaire. Chrome a installé le [Obsidian Web Clipper] (https://obsidian.md/clipper) officiel, et lorsque vous voyez un bon article, cliquez dessus - c'est ainsi que j'ai vu l'article d'Anthropic "Créer des agents efficaces" la semaine dernière - le texte entier + l'URL source + mon surlignage, ainsi que le contenu rempli automatiquement, sont tombés à 00-收件箱/.
Revenez au terminal et exécutez /inbox :
$ claude
> /inboxAprès que Claude ait lu l'article, il m'a répondu : « Ce contenu est le résumé officiel d'Anthropic du modèle de conception d'agent.
J'ai dit : "Remettez-le d'abord dans le presse-papiers, et je le lirai moi-même dans Atomic Notes avant de le démonter." - Créez le fichier mv, ajoutez le frontmatter 类型: 文章剪藏 et ajoutez la balise #类型/文章剪藏 #主题/ai, et ce sera fait en 30 secondes. **Je n'ai effectué que deux actions dans tout le processus : appuyez sur le bouton Clipper et tapez une phrase. **
Ce processus était encore manuel il y a un demi-mois - télécharger → renommer → décider quel dossier mettre → rédiger le texte de présentation - un article devrait prendre au moins 5 minutes. Si vous rencontrez quelque chose que vous ne savez pas où mettre, cela sera retardé d’une semaine. Il y a maintenant dix articles empilés dans ma boîte de réception et je peux les terminer en 5 minutes.
Une phrase d'inspiration mène au manuscrit terminé
C'est le pipeline le plus long de tout mon système. D'une phrase d'inspiration à la finalisation de la publication sur trois plateformes (comptes officiels, Zhihu et Xiaohongshu), tous sont motivés par le mouvement des fichiers :
/idea 谈谈 Claude Code Skill 比 MCP 灵活的原因
↓ 60-创作/01-灵感池/20260502-...md(Templater 自动写入 frontmatter)
/draft <灵感文件>
↓ Claude 从 40-原子笔记/ 拉相关原子,从素材库拉历史素材,组织大纲+初稿
↓ 落到 60-创作/03-初稿/
/publish
↓ yux-blog-writer 润色 → yux-publish-* 多平台发布
↓ 文件 mv 到 05-已发布/2026/05/,frontmatter 回写各平台 URLCe pipeline a un design que j'aime particulièrement : la migration d'état est un fichier mv. Le répertoire dans lequel se trouve le fichier correspond à son statut. Le plug-in Kanban génère un tableau Kanban à cinq colonnes directement basé sur les cinq sous-répertoires de 60-创作/, avec zéro code - vous faites glisser la carte et le fichier est déplacé. Si simple que cela ne ressemble presque pas à un flux de travail.
L'IA écrit, je ne fais que lire
Cette scène est le véritable passage du modèle « écriture humaine et lecture humaine » de centaines de milliers de mots en wolai au modèle « écriture IA et lecture humaine » à l'ère de l'IA.
Je demande à Claude de m'aider à organiser systématiquement un sujet - comme RAG. Il sera écrit directement sous 40-原子笔记/RAG/. Chaque entrée est une note atomique indépendante, avec les balises #类型/原子 #归类/RAG #主题/ai et le texte de couverture correct. Après qu'il ait été écrit, il m'a dit : « J'ai écrit 12 éléments dans ce lot. Veuillez prendre le temps de les lire. J'ai marqué la force de l'argument comme « à vérifier ». Je le changerai en « vérifié » après que vous l'aurez relu.
Tout ce que je fais, c'est : lire, juger et changer "à vérifier" en "vérifié" ou "spéculé". Une partie considérable de mes centaines de milliers de mots de notes wolai est en fait ce genre de travail de tri – il aurait dû être effectué par l’IA. J'ose désormais confier 70 % de mes écrits à l'IA car mon rôle a changé.
Cohérent entre les sessions
Le moment qui m'a fait sentir que ce système "prenait vie" le plus était une session Claude Code nouvellement ouverte - je ne lui ai donné aucune invite et j'y ai simplement ajouté un morceau de texte : "Aidez-moi à le coller au bon endroit."
Il a lu CLAUDE.md, analysé la sémantique de mon texte et m'a dit : « Ce paragraphe n'est pas comme une note atomique (la conclusion n'est pas assez indépendante), mais plutôt comme un matériau créatif - quel manuscrit a été préparé pour vous ?
**Il me demande de revenir en utilisant mes règles. **
C'est un sous-produit auquel je ne m'attendais pas le premier jour de l'installation : lorsque vous écrivez les règles de manière suffisamment claire, l'IA vous oblige à réfléchir clairement à ce que vous faites dans le processus d'exécution des règles.
Ce que je n'ai compris qu'un demi-mois plus tard
**Le piège le plus simple dans la création d'un système de connaissances à l'ère de l'IA est de laisser l'IA vous aider à concevoir une « classification parfaite », et vous ne pourrez alors pas suivre les préréglages. **
Le premier jour d’installation, la structure de répertoires que Claude m’a donnée était aussi soignée qu’une feuille de réponses à un examen. Mais ce qui peut vraiment être utilisé le quinzième jour, c'est la feuille de réponses soignée ainsi qu'une série de correctifs « vous ne le saurez qu'après l'avoir utilisé » - tels que :
- À mesure que de plus en plus d'Atomic Notes s'accumulent, le répertoire racine devient confus → Ajoutez l'espace de noms
#归类/et le sous-répertoire de thème - Les notes écrites par l'IA sont mélangées à celles que j'ai pensées et écrites, ce qui rend impossible de les distinguer → Ajouter le champ frontmatter
论证强度pour la superposition
Ces règles ne sont pas sorties du premier jour de pré-travail de Claude. Ils ont grandi après un demi-mois de travail et après avoir traversé quelques embûches.
Si mon plan du premier jour avait copié Kepano, le #归类/ d'aujourd'hui ne serait jamais apparu - parce que ce n'était pas le besoin de Kepano. **Le système véritablement utilisable est quelque chose qui est utilisé et non imaginé. **
Repenser les notes à l'ère de l'IA

À ce stade, je peux prendre trois décisions finales – pour le dire aussi simplement que possible :
**Première phrase : le côté opposé de la note est passé de moi à AI. **
J'avais l'habitude d'écrire des notes pour mon futur moi - donc plus je m'en souvenais et plus elles étaient joliment organisées, mieux c'était. Mais maintenant, je passe la plupart de mon temps avec l’IA qui m’aide à écrire, lire et trouver pour moi. Le vrai visage de la note a changé : c'est désormais la « mémoire à long terme » que l'IA autour de vous veut appeler à tout moment, et vous vous contentez de la lire en passant.
Cette question détermine directement les critères de sélection des outils de prise de notes. La raison fondamentale pour laquelle je me retire de wolai et Notion n'est pas qu'ils arrêtent de se mettre à jour ou se bloquent, mais que leur contenu AI ne peut pas être utilisé - l'IA dans une boîte noire SaaS ne peut pas être appelée à vos côtés à tout moment, et peu importe la beauté d'un ordinateur portable, il ne peut pas être sauvegardé. **Ainsi, lorsque j'évalue les outils de prise de notes maintenant, la première question est « Mon contenu peut-il être lu et écrit naturellement par l'IA ? » Utilisez-le si vous le pouvez, abandonnez si vous ne pouvez pas. **
**Deuxième phrase : l'IA écrit des connaissances et les humains écrivent des jugements. **
L'IA peut écrire des faits, des organisations et des principes techniques plus rapidement et avec plus de précision que moi - ce serait une perte de temps pour deux personnes de les écrire à la main. Mais la position, l’évaluation et les contre-exemples doivent être rédigés par vous-même. Ce n'est pas parce que l'IA ne sait pas écrire, c'est parce qu'une fois que vous aurez externalisé cette partie, vous perdrez lentement confiance en votre propre jugement. L’article très apprécié de HN paru en mars de cette année énonce ce sujet de la manière la plus dure :
The risk isn't that AI replaces our thinking. It's that we lose confidence in our own judgments — even in domains where AI cannot meaningfully contribute.
Ma contre-mesure consiste à marquer chaque note comme "à vérifier/vérifié/spéculé" - la note complète écrite par l'IA est "à vérifier", et une fois que j'aurai fini de la lire, elle sera changée en "vérifié" ou "spéculé". **Celui qui appuie sur ce bouton doit être moi. **
**La troisième phrase : Le système est créé en l'utilisant, pas en l'inventant. **
Cette phrase a été expliquée en détail dans la section précédente : ne laissez pas l'IA vous dresser une table des matières parfaite dès le premier jour. Après deux semaines de fonctionnement, quelques règles dont vous seul avez besoin émergeront naturellement.
Ce n'est que le début
Ce système n'est mis en place que depuis un demi-mois, et il est loin d'être finalisé - mais il me suffit de l'utiliser, et cela me suffit pour écrire ce billet de blog.
Si vous souhaitez également créer votre propre ensemble - Ne copiez pas mon catalogue, copiez la méthode. Jetez ce billet de blog dans Claude Code et dites-lui :
参考这篇博文里的体系,给我搭一套属于我自己的。
不要直接抄目录,先问我 10 个问题,比如:
- 我每天会读多少新内容?是看视频、读论文,还是逛博客?
- 我有没有写作或发布的需求?发到哪里?
- 我希望 AI 在我的笔记里扮演什么角色——
只读、整理、还是直接帮我写?
- 有没有哪些笔记是只服务一次的素材,哪些是要长期沉淀的资产?
- 我的旧笔记在哪里?是想全迁过来还是慢慢消化?
- ……剩下的你来问。
把我的回答记到 CLAUDE.md 的 Context 段里,然后再给方案。Cela vous donnera un système différent du mien, mais qui vous appartient.
Quant aux centaines de milliers de mots de notes du wolai, je ne les ai pas tous transférés : j’ai laissé l’IA les digérer lentement. Il s'agit de la deuxième phase du système. Si un jour vous voyez ce blog publier un article « J’ai demandé à l’IA de lire pour moi des centaines de milliers de mots d’anciennes notes », c’est que le système a grandi.
À ce moment-là, ce ne serait plus seulement un coffre-fort en obsidienne, ce serait un véritable deuxième cerveau qui durerait dix ans.
Lectures complémentaires
Si vous souhaitez approfondir les méthodologies et outils cités dans cet article, voici les suivants par ordre d’importance :
- File over app — kepano Un essai de mille mots qui explique en détail « Pourquoi les données devraient être des fichiers ». Lisez-le en 5 minutes et utilisez-le pendant dix ans.
- Comment j'utilise Obsidian — kepano À quoi ressemble son propre coffre-fort, un échantillon représentatif de prise de notes ascendante
- La méthode PARA + Présentation du deuxième cerveau de l'IA — Théorie PARA de Forte + extension à l'ère de l'IA
- Comment prendre des notes intelligentes (Ahrens) + Lier votre réflexion (Milo) — La méthodologie originale de Zettelkasten et LYT
- Message du forum Zettelkasten augmenté par l'IA — Une voix représentative qui s'oppose à "l'écriture directe de cartes par l'IA"
- MarkusPfundstein/mcp-obsidian — Serveur MCP qui permet à Claude Code de lire et d'écrire naturellement l'intégralité du coffre-fort
Articles connexes
Publier sur un compte officiel WeChat en un clic avec Claude Skills
Guide pas a pas pour utiliser le Skill baoyu-post-to-wechat afin d'automatiser la publication de Markdown vers un compte officiel WeChat, couvrant l'installation, la configuration et le processus complet de publication
D'Eclipse a Zed : l'evolution des editeurs d'un developpeur
Du developpement backend au full-stack, de VS Code avec plus de 200 extensions a un workflow centre sur le terminal — comment mes choix d'editeurs ont evolue avec l'ere de l'IA
Mes meilleures pratiques pour Claude Code
Partage de mon experience avec Claude Code — 10 conseils essentiels, guide complet des commandes slash et configuration des commandes personnalisees pour ameliorer votre efficacite en programmation IA