Grill With Docs: Equipar la IA con memoria de proyecto utilizando lenguaje de dominio y ADR
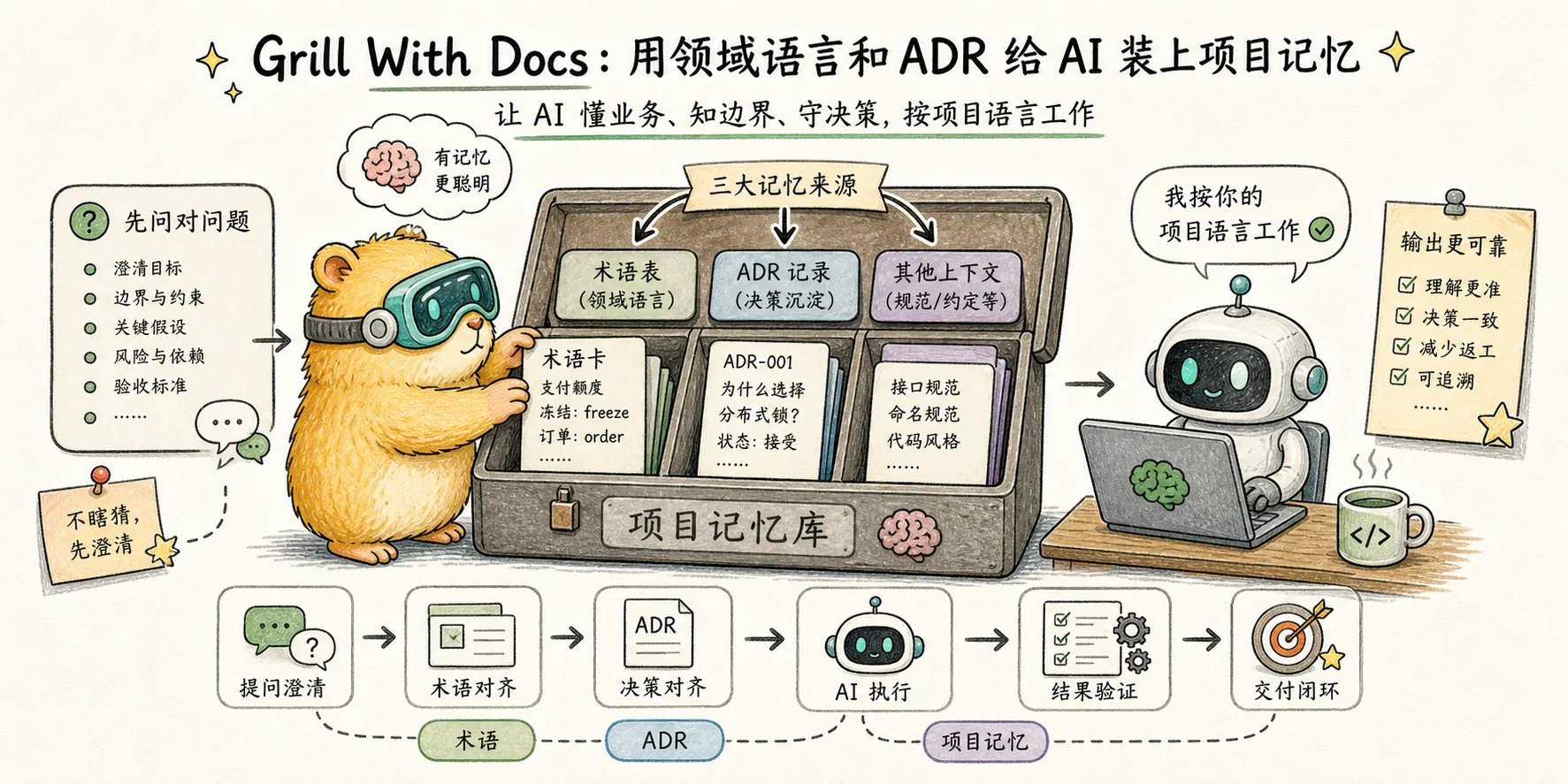
La versión avanzada de grill-me: mientras interroga los requisitos, mantiene automáticamente CONTEXT.md (glosario de proyectos) y ADR (registro de decisiones arquitectónicas) y traduce las omnipresentes ideas del lenguaje de DDD en flujos de trabajo que LLM puede ejecutar directamente.
With a ubiquitous language, conversations among developers, expressions of the code, and conversations with domain experts are all derived from the same domain model.
Modo de error: "La IA es demasiado detallada"
El segundo modo de fracaso en el discurso de Matt:
La IA expresa algo simple con mucha palabrería. Es como hablarte dos idiomas.
Esto no tiene nada que ver con la cantidad de código, es ubicación incorrecta del vocabulario. La IA utilizará términos generales ("elemento", "datos", "controlador") de forma predeterminada, y los términos reales en el proyecto que tiene en mente pueden ser "Curso", "Versión borrador", "Lección fantasma". La IA no sabe que estas palabras tienen significados específicos en su proyecto, por lo que creará un montón de palabras nuevas sinónimas a su alrededor. El resultado es:
- Proceso de pensamiento largo (evite las palabras exclusivas)
- La implementación no está alineada con el diseño que tienes en mente (porque no están en el mismo espacio semántico)
- No reutilizable entre sesiones (el contexto debe restablecerse para cada conversación)
Teoría clásica: el lenguaje ubicuo de DDD
Matt citó el "Diseño basado en dominios" de Eric Evans. Este libro fue publicado en 2003 y propuso el concepto de lenguaje ubicuo:
Utilice el mismo conjunto de términos para conectar expertos en el dominio, desarrolladores y códigos. Una palabra en discusiones sobre productos, comentarios de código, nombres de variables, documentación: debe significar lo mismo.
El objetivo de DDD es hacer que el código parezca el cerebro de un experto en el dominio. En la era de la IA, hay un nuevo rol: LLM también debe estar en este idioma. El LLM no está en la reunión de pie, no puede ver la reunión de requisitos del producto y no puede entender la jerga de su grupo; solo puede aprender de los documentos que usted le proporciona.
Matt convirtió esto en una habilidad: escanear la base del código para extraer términos, generar un archivo de rebajas CONTEXT.md y luego alinearlo tanto con los humanos como con la IA.
La evolución de las habilidades: del lenguaje ubicuo a la parrilla con documentos
La primera habilidad se llamó ubiquitous-language; solo hacía una cosa: escanear la base del código para generar un glosario. Pero Matt descubrió más tarde que simplemente generar un documento no era suficiente:
- La documentación estará desactualizada: se genera hoy, el código se cambia mañana y el glosario no se ha actualizado.
- La gente no tomará la iniciativa de mirarlo: Estaría muerto si lo pones ahí
Lo refactorizó en grill-with-docs, que combinaba tres cosas:
- Requisitos de tortura (todas las habilidades heredadas de grill-me)
- Desafía el glosario existente: ¿La palabra que dijiste no coincide con lo que está escrito en CONTEXT.md? Señalalo inmediatamente
- Actualizar documentos simultáneamente al tomar decisiones: Las nuevas conclusiones alcanzadas durante el proceso de tortura se escriben en línea en CONTEXT.md o se crea un nuevo ADR.
Se trata de un cambio de paradigma de "generar documentos estáticos" a "diálogo es mantener documentos".
Texto completo de la habilidad
Estructura central de engineering/grill-with-docs/SKILL.md:
---
name: grill-with-docs
description: Grilling session that challenges your plan against the
existing domain model, sharpens terminology, and updates
documentation (CONTEXT.md, ADRs) inline as decisions crystallise.
---
<what-to-do>
Interview me relentlessly about every aspect of this plan until we
reach a shared understanding. Walk down each branch of the design
tree, resolving dependencies between decisions one-by-one. For each
question, provide your recommended answer.
Ask the questions one at a time, waiting for feedback on each question
before continuing.
If a question can be answered by exploring the codebase, explore the
codebase instead.
</what-to-do>
<supporting-info>
## Domain awareness
During codebase exploration, also look for existing documentation:
### File structure
Most repos have a single context:
/
├── CONTEXT.md
├── docs/
│ └── adr/
│ ├── 0001-event-sourced-orders.md
│ └── 0002-postgres-for-write-model.md
└── src/
If a CONTEXT-MAP.md exists at the root, the repo has multiple contexts.
## During the session
### Challenge against the glossary
When the user uses a term that conflicts with the existing language in
CONTEXT.md, call it out immediately.
"Your glossary defines 'cancellation' as X, but you seem to mean Y —
which is it?"
### Sharpen fuzzy language
When the user uses vague or overloaded terms, propose a precise
canonical term.
"You're saying 'account' — do you mean the Customer or the User?
Those are different things."
### Discuss concrete scenarios
When domain relationships are being discussed, stress-test them with
specific scenarios.
### Cross-reference with code
When the user states how something works, check whether the code
agrees. If you find a contradiction, surface it.
### Update CONTEXT.md inline
When a term is resolved, update CONTEXT.md right there. Don't batch
these up — capture them as they happen.
### Offer ADRs sparingly
Only offer to create an ADR when all three are true:
1. Hard to reverse
2. Surprising without context
3. The result of a real trade-off
</supporting-info>¿Cómo se ve el CONTEXT.md real?
El repositorio course-video-manager de Matt ofrece un ejemplo completo de CONTEXT.md. Escojamos algunos términos para tener una idea:
| Terminología | Definición |
|---|---|
| Course | The primary domain entity: a structured collection of versions, sections, lessons, and videos |
| Draft Version | The single mutable CourseVersion that is currently being edited; always the latest by createdAt |
| Published Version | An immutable CourseVersion with a name and description, created by the Publish flow |
| Ghost Lesson | A lesson that exists in the database but not yet on the file system (fsStatus = "ghost") |
| Export Hash | A SHA256 hash derived from a video's clip filenames, timestamps, clip order |
| Unexported Video | A video whose current Export Hash does not match any file on disk; blocks publishing |
| Materialization Cascade | The chain reaction when materializing a lesson inside a ghost course |
| Clip | A timestamped segment of source footage within a video |
| Fractional Index | A string-based ordering value that allows inserting items between existing items |
| Purge | The deliberate deletion of an Exported Video's .mp4 file from disk |
Tenga en cuenta algunas cosas:
- Cada término es un gerundio o un nombre propio, no una frase descriptiva como “estado del pedido”
- Cada definición hace referencia a otros términos (Curso → Versión → Lección → Video) formando una red de ontologías
- El campo de código aparece directamente (
fsStatus = "ghost") - Mapeo 1:1 de documentos y código - Incluya descripciones de las decisiones ("bloquea la publicación", "reacción en cadena"): no solo sustantivos, sino reglas
Al escribir código, cuando AI vea este documento, utilizará "Lección fantasma" en lugar de "lección sin archivo". El código, las conversaciones y los mensajes de confirmación están todos unificados.
ADR: cuando se crea
Hay una restricción importante en la habilidad:
Only offer to create an ADR when all three are true:
- Hard to reverse — the cost of changing your mind later is meaningful
- Surprising without context — a future reader will wonder "why did they do it this way?"
- The result of a real trade-off — there were genuine alternatives
La cultura de ADR (Architecture Decision Record) se originó en el blog de Michael Nygard en 2011, pero muchos equipos la utilizan para escribir ADR para todas las decisiones: 18 de cada 20 ADR están ejecutando cuentas. Matt Esta triangulación es una gran herramienta: ADR solo vale la pena si se cumplen tres condiciones simultáneamente. De lo contrario, deje que se digiera en CONTEXT.md y se digiera en el código.
Cómo instalar y usar
Condiciones previas: primero ejecute /setup-matt-pocock-skills (le preguntará dónde colocar CONTEXT.md y dónde colocar el directorio ADR).
Llamar: /grill-with-docs
Proceso típico:
- Describe lo que quieres hacer
/grill-with-docs- Claude escanea CONTEXT.md y docs/adr/ primero, cargando los términos y decisiones existentes en contexto
- Iniciar la tortura, durante el proceso:
- La palabra que usaste entra en conflicto con CONTEXT.md → Indícalo en el acto
- Usó palabras vagas (por ejemplo, "Cuenta" podría ser Cliente o Usuario) → Le permite elegir una de las dos y colocarla en el documento.
- El comportamiento que mencionaste es inconsistente con el código existente → señala el conflicto
- Actualice CONTEXT.md sincrónicamente cuando se tome la decisión (sin retrasos ni procesamiento por lotes)
- Decisiones clave irreversibles → Preguntar si se debe generar un ADR
Si aún no hay CONTEXT.md y docs/adr/ en el proyecto, se creará de forma diferida: los archivos no se generarán hasta que sea necesario escribir el primer término y crear el primer ADR. No le daremos una plantilla en blanco desde el principio.
Proyectos de contexto múltiple (CONTEXT-MAP.md)
Si el proyecto es demasiado grande para caber en un CONTEXT.md (por ejemplo, pedidos y facturación son dos contextos delimitados independientes), puede colocar CONTEXT-MAP.md en el directorio raíz como directorio general:
/
├── CONTEXT-MAP.md ← 总目录
├── docs/adr/ ← 系统级决策
├── src/
│ ├── ordering/
│ │ ├── CONTEXT.md
│ │ └── docs/adr/ ← 模块级决策
│ └── billing/
│ ├── CONTEXT.md
│ └── docs/adr//grill-with-docs reconocerá automáticamente la existencia de CONTEXT-MAP.md y saltará al subdirectorio correspondiente. Esta es una implementación directa del concepto de contexto limitado en DDD: las "órdenes" en cada contexto pueden tener significados diferentes y se mantienen por separado para evitar la contaminación.
La diferencia entre ## y grill-me
| dimensiones | /asarme | /parrilla-con-docs |
|---|---|---|
| Capacidad de cuestionamiento | ✅ | ✅ (heredar todo) |
| Verificación de la terminología del proyecto | ❌ | ✅ |
| Actualizaciones en tiempo real CONTEXT.md | ❌ | ✅ |
| Sentencia de activación de ADR | ❌ | ✅ |
| Etapa aplicable | Primeras ideas, proyectos personales | Proyectos reales con complejidad de dominio |
| Costo inicial | 0 | Requiere configuración + Tener/estar dispuesto a construir CONTEXT.md en el proyecto |
Juicio simple y crudo:
- Guiones personales, redacción de artículos, impartición de cursos →
/grill-me - Proyectos reales que requieren mantenimiento a largo plazo →
/grill-with-docs
Un beneficio contrario a la intuición: dejar que la IA aprenda a "callarse"
CONTEXT.md no es sólo para IA, es para futuras sesiones de IA. Cada vez que comienza una nueva conversación, Claude puede ingresar instantáneamente al contexto del proyecto leyendo CONTEXT.md, lo que le ahorra una larga incorporación.
Lo que es aún más sutil es: Matt dijo en su discurso que después de agregar CONTEXT.md podía ver en el rastro de pensamiento de AI——
"Permite que la IA piense de una manera menos detallada".
¿Por qué? Porque sin CONTEXT.md, la IA tiene que definir constantemente sus propios términos cuando piensa: "el usuario, es decir, la persona que ordenó el artículo, en lo sucesivo denominado...". Con CONTEXT.md dice directamente "Cliente", la cadena de pensamiento es mucho más corta y la respuesta es más rápida.
La economía simbólica de LLM determina: acortar el camino del pensamiento = producción más rápida, más precisa y más barata. CONTEXT.md es la palanca oculta para esta eficiencia.
Notas
CONTEXT.md cambiará significativamente durante la primera ejecución. Si ya hay un CONTEXT.md escrito a mano en el proyecto, primero git stash o déjelo funcionar en seco antes de ejecutarlo (puede agregar una oración en el mensaje "Enumere el contenido que se cambiará primero, no escriba el archivo directamente").
La moderación ADR es moderación real. No te emociones y haz que cada decisión genere un ADR, tus docs/adr/ estarán llenos de basura en 6 meses. Los tres criterios de Matt deben seguirse estrictamente.
CONTEXT.md No ponga detalles de implementación. Hay un dicho en Skill: "No combine CONTEXT.md con los detalles de implementación. Incluya sólo términos que sean significativos para los expertos en el dominio". Escribir "PostgreSQL" en CONTEXT.md es incorrecto: a los expertos en dominios no les importa la selección de la base de datos, eso es una cuestión de ADR.
Recursos de referencia
grill-with-docs/SKILL.md (源码)
The full SKILL.md including supporting-info on domain awareness, ADR discipline, and multi-context handling.
course-video-manager CONTEXT.md (真实例子)
A real-world CONTEXT.md from Matt's own video editor project. Use as a template for what good ubiquitous language docs look like.
Skills Changelog: ubiquitous-language → grill-with-docs
Matt's writeup on why he merged the standalone ubiquitous-language skill into a new conversational version.
Artículo siguiente: a-PRD + a-Issues: Del diálogo al ticket ejecutable——Después de la tortura, cómo solidificar el diálogo en una unidad de trabajo ejecutable.
Comentarios
Grill Me
La habilidad más popular de Matt Pocock, la reducción de 7 líneas, le permite a Claude alinearse con sus necesidades durante 30 a 45 minutos antes de comenzar a hacerlo: desmantelando su principio de funcionamiento, la diferencia con el modo de plan que viene con Claude Code y cómo extenderlo a escenarios sin programación.
PRD y problemas
La parte intermedia del flujo de trabajo de Matt Pocock: /to-prd convierte la conversación en un PRD, y /to-issues divide el PRD en temas cortados verticalmente que se pueden recopilar de forma independiente. Interpretación en profundidad del nuevo papel de los dos viejos conceptos de "bala trazadora" y "corte vertical" en la era de la IA