Diagnose and Triage: Establish a Feedback Loop First, Then Decide Who Handles It
Deconstructing Matt Pocock's /diagnose and /triage engineering skills: one focuses on finding the root cause of bugs with a repeatable feedback loop, the other on moving issues through needs-info, ready-for-agent, ready-for-human, or wontfix states.
Why Discuss These Two Skills Together
/diagnose and /triage are presented as two independent skills in the README, but they address two halves of the same engineering problem:
/diagnosecares about: What exactly is this bug, how can it be reproduced, and how can we prove it's fixed?/triagecares about: Should this issue wait for more information, be assigned to an agent, to a human, or be closed?
One deals with facts, the other with process. In real projects, these two are often linked: you triage a bug issue, find insufficient information, and mark it needs-info; once enough information is available, you use diagnose to build a feedback loop; after clearly reproducing it, you decide whether it's ready-for-agent or ready-for-human.
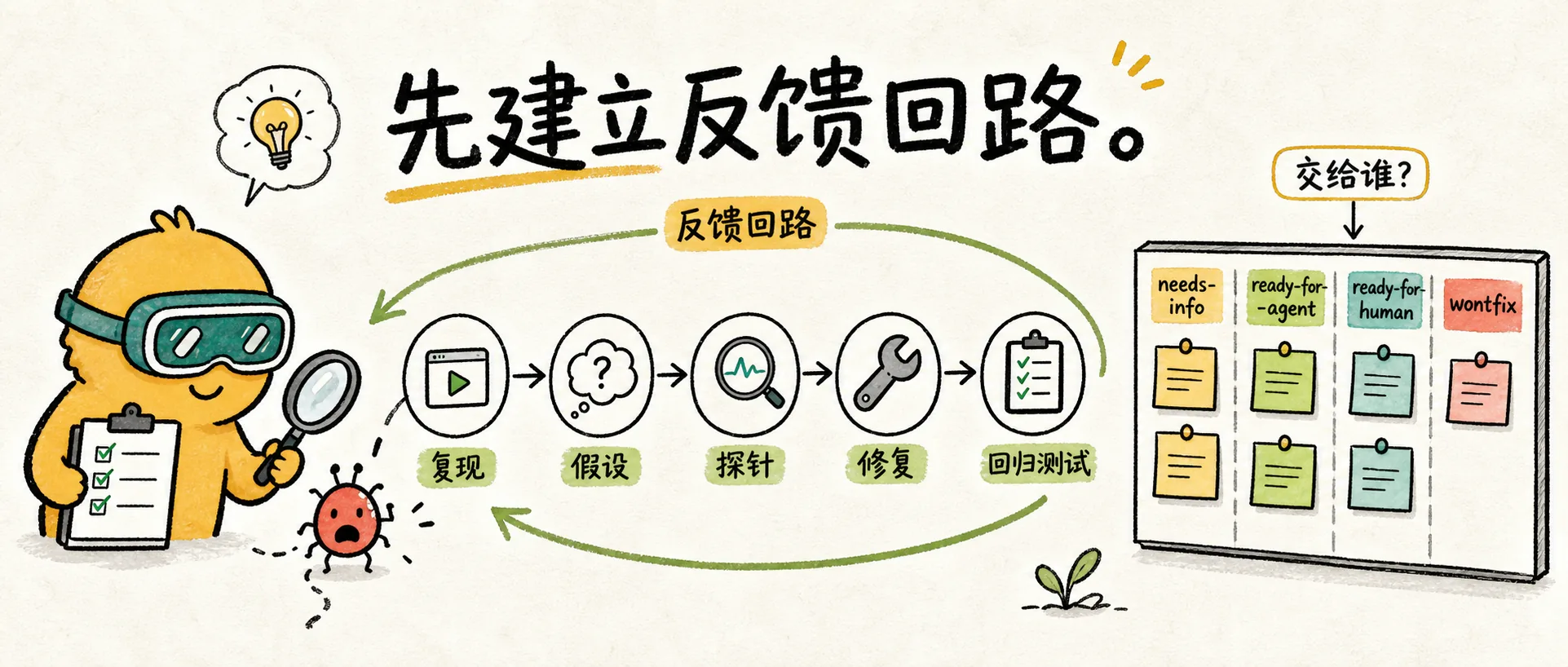
The Core of /diagnose: The Feedback Loop Is Everything
The most important takeaway from /diagnose is: first, establish a pass/fail signal that an agent can run.
Matt breaks down diagnosis into 6 stages:
| Stage | Goal |
|---|---|
| Build a feedback loop | Set up a fast, deterministic, repeatable failure signal |
| Reproduce | Make this signal reproduce the same bug described by the user |
| Hypothesise | List 3-5 falsifiable hypotheses |
| Instrument | Verify hypotheses with minimal probes |
| Fix + regression test | Write regression tests on the correct test surface, then fix |
| Cleanup + post-mortem | Clean up temporary probes, document the true root cause |
This is contrary to how many people debug. The common debugging process is: look at code, guess the cause, make a change, refresh the page. Matt reverses this: first, turn the bug into a repeatable machine signal, then discuss hypotheses.
What Constitutes a Good Feedback Loop
/diagnose provides a set of priorities, from best to last resort:
| Loop Type | Suitable Scenario |
|---|---|
| Failing test | When there's an appropriate test surface that can directly express the bug |
| curl / HTTP script | API bugs, server-side behavior reproducible with requests |
| CLI + fixture | Command-line tools, parsers, transformers |
| Headless browser | UI bugs, console errors, network behavior |
| Replay captured trace | Real-world payloads, event streams, log traces from production |
| Throwaway harness | Start only a small part of the system, isolating complex dependencies |
| Property / fuzz loop | Intermittent error output, needs increased trigger rate |
| Bisection / differential loop | Broken after a certain version, needs bisection or comparison with old versions |
| HITL script | Even when manual interaction is required, ensure humans follow a script for stable output |
There's a strict judgment here: without a loop, do not enter the hypothesis stage. Without a signal, all analysis becomes "it looks like."
What About Non-Deterministic Bugs?
/diagnose also offers a practical approach to intermittent bugs: the goal isn't 100% reproduction from the start, but to increase the reproduction rate to a debuggable level.
For example:
- Trigger 100 times in a loop
- Trigger concurrently
- Inject
sleepto widen race windows - Fix random seeds or time
- Narrow down environment variables and external dependencies
A 1% intermittent bug is hard to debug; a 50% intermittent bug is already a debuggable object. This approach is very useful for frontend async issues, message queues, payment callbacks, and streaming output.
Hypotheses Must Be Falsifiable
Matt requires listing 3-5 hypotheses before attempting verification, and each hypothesis must include a prediction:
If X is the cause, then changing Y should make the bug disappear;
or observing Z should reveal a certain characteristic.This prevents the agent from getting stuck on the first seemingly plausible explanation. More importantly, it allows you to judge whether an experiment provides any information.
A bad hypothesis:
It might be a caching issue.A falsifiable hypothesis:
If browser caching is causing an old script to execute, then after disabling cache and hard refreshing, the old bundle hash in the console should disappear, and button click events should resume functionality.Only the latter is worth verifying.
Common Mistakes in the Fix Stage
/diagnose requires that if there's a correct test surface, you should first convert the minimal reproduction into a failing test, then fix the code.
The key is "correct test surface." It's not just adding any unit test as a regression test. The correct test surface must cover the real bug pattern:
- If the bug is triggered by a combination of multiple callers, don't just test a single function.
- If the bug is triggered by a real payload structure, don't just test a handwritten toy object.
- If the bug is triggered by the order of browser events, don't just test pure functions.
If you can't find the correct test surface, that itself is a conclusion: the code structure doesn't provide a place to lock down the bug. After fixing, this information should be passed to /en/docs/notes/matt-pocock-skills/improve-codebase-architecture.
The Core of /triage: Issues as State Machines
/triage is not about letting AI "just take a look at the issue." It treats issues as small state machines.
Every issue should simultaneously have:
- A category:
bugorenhancement - A state:
needs-triage,needs-info,ready-for-agent,ready-for-human,wontfix
The value of this set of states is that it allows maintainers to quickly answer:
- Which ones haven't been looked at yet?
- Which ones are waiting for the reporter to provide more information?
- Which ones are clear enough to be assigned to an AFK agent?
- Which ones must be done by a human?
- Which ones should be closed, and why?
Criteria for ready-for-agent
ready-for-agent is the most critical state in this workflow. It's not "this task can be tried by AI," but rather:
The task is clear enough for an absent agent to independently pick up, implement, and verify.
This usually means the issue contains at least:
- Background and problem statement
- Relevant code paths or modules
- Clear acceptance criteria
- Known constraints
- If it's a bug, ideally a reproduction method
- No need for additional product/design judgment
If these are missing, it should be needs-info or ready-for-human, not forced onto an agent.
needs-info Requires Specific Questions
/triage provides a simple template for needs-info, but the key is that the questions must be specific:
## Triage Notes
**What we've established so far:**
- ...
**What we still need from you (@reporter):**
- ...Bad question:
Please provide more information.Good question:
Please provide the browser version that triggered the issue, the URL of the problematic page, the click sequence, and the response body of `/api/orders/:id` from the Network panel.AI can easily write polite platitudes; this skill forces it to separate "what we already know" from "what we still need."
wontfix Also Needs Documentation
/triage has an interesting design for wontfix enhancements: don't just close the issue, but write the rejection reason into the .out-of-scope/ knowledge base and link to it in the comments.
This way, the next time a similar request comes up, the AI won't re-engage in the same discussion. It can first read .out-of-scope/ and remind the maintainer: "This direction was previously rejected for reason X."
This is similar to the spirit of ADRs: not recording all decisions, but only those that will cause confusion in the future and are likely to recur.
How They Work Together
A typical bug issue might follow this path:
/triagereads the issue, comments, labels, and relevant code.- It determines this is
bug + needs-triage. - It first attempts to reproduce; if steps are insufficient, it changes to
needs-info. - Once enough information is available, it initiates
/diagnose. /diagnoseestablishes a reproduction loop, lists hypotheses, and identifies the root cause.- If the fix path is clear and the test surface is well-defined, the issue becomes
ready-for-agent. - If product judgment, external permissions, or manual verification are needed, the issue becomes
ready-for-human. - After fixing, the root cause and regression tests are written back to the issue or PR.
The key to this process is not "AI automatically fixes bugs," but rather transforming a vague issue description into an executable work package.
My Usage Recommendations
If you only remember one thing:
/diagnosefirst asks "How do I prove it's broken?";/triagefirst asks "What state should it be in now?"
These two questions can prevent a lot of low-quality AI programming:
- Fixing without reproduction
- Starting work without acceptance criteria
- Refactoring without a root cause
- Assigning to an agent without information
Matt's two skills are not flashy, but they are very much like what a senior engineer in a real team would do: first consolidate the facts, then advance the process.
References
diagnose/SKILL.md
A disciplined loop for hard bugs and performance regressions.
triage/SKILL.md
Move issues through a small state machine of triage roles.
Next: TDD: Force AI to Take Small Steps with Red-Green-Refactor.