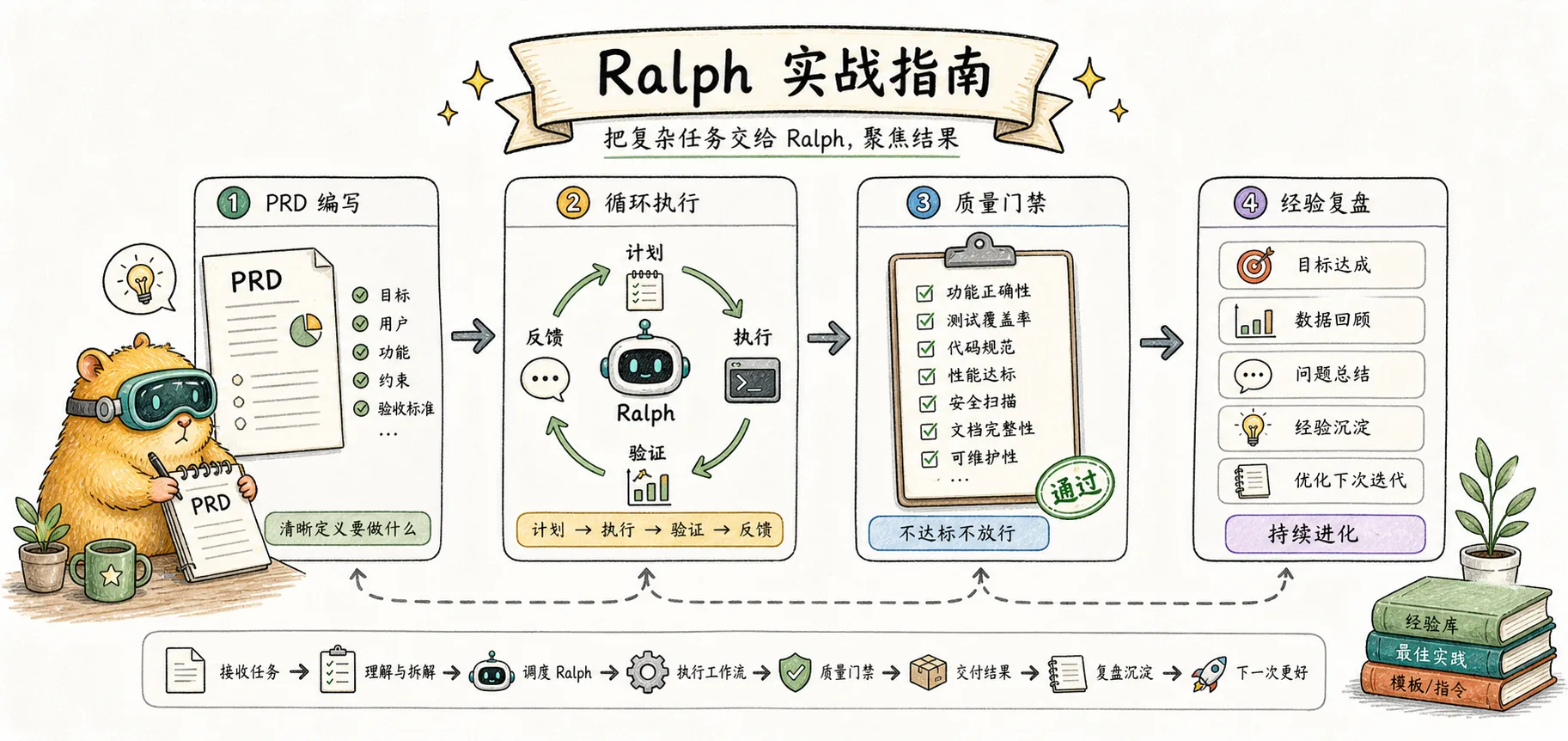
ラルフの実践ガイド
snarktank/ralph 完全操作マニュアル – インストールから実際の使用まで、PRD の作成、サイクルの実行、品質ゲートと学んだ教訓をカバー
はじめに
前の記事 では、無限ループ + 毎回新しいコンテキスト + 真実の唯一の情報源としてのファイルという Ralph の核となる原則を理解しました。これら 3 つの柱は単純に聞こえますが、コンセプトの理解から実際に実行するまで、多くの詳細を検討する必要があります。
この記事では、始めましょう。 snarktank/ralph を使用して、インストールから実行までの完全なプロセスを完了する方法を学びます。 snarktank/ralph は、コミュニティ内で最も成熟した Ralph 実装の 1 つです (10,000 つ星以上)。 Claude Code と Amp の 2 つのツールと、PRD 生成、JSON 変換、自動実行のための完全なツール チェーンをサポートしています。
前提条件
始める前に、環境が次の要件を満たしていることを確認してください。
| 依存関係 | 説明 |
|---|---|
| AI プログラミング ツール | クロード コード (npm install -g @anthropic-ai/claude-code) または Amp CLI |
| jq | JSON処理ツール(macOS:brew install jq) |
| Git | プロジェクトは Git リポジトリである必要があります。 |
# 检查依赖
claude --version # Claude Code CLI
jq --version # JSON 处理
git --version # Gitインストールと構成
snarktank/ralphは、利用シーンに合わせて選べる多彩な設置方法をご用意しています。
方法 1: クロード コードに直接インストールする (推奨)
最も簡単な方法 - クロード コードの会話に GitHub リンクを貼り付け、クロードが自動的にインストールを完了できるようにします。
Install this skill for me: https://github.com/snarktank/ralphClaude Code はリポジトリのクローンを自動的に作成し、スキル ファイルを正しい場所にコピーします。 /prd および /ralph コマンドは、インストール後に使用できるようになります。
方法 2: クロード コード マーケットのインストール
マーケットコマンド経由でインストールします。
# 添加并安装插件
/plugin marketplace add snarktank/ralph
/plugin install ralph-skills@ralph-marketplaceインストール後、/prd (PRD の生成) と /ralph (JSON への変換) の 2 つのスキルを使用できます。
方法 3: 手動スキルのインストール (クロード コード/アンプ)
スキル ファイルを対応するツールのグローバル構成ディレクトリに手動でコピーします。
# 先克隆仓库
git clone https://github.com/snarktank/ralph.git /tmp/ralph
# Claude Code 用户
cp -r /tmp/ralph/skills/prd ~/.claude/skills/
cp -r /tmp/ralph/skills/ralph ~/.claude/skills/
# Amp 用户
cp -r /tmp/ralph/skills/prd ~/.config/amp/skills/
cp -r /tmp/ralph/skills/ralph ~/.config/amp/skills//prd および /ralph コマンドは、インストール後に使用できるようになります。
方法 4: プロジェクト レベルのインストール
Ralph スクリプトをプロジェクトに直接コピーします。チーム共有またはカスタム スクリプトが必要なシナリオに最適です。
# 克隆 Ralph 仓库
git clone https://github.com/snarktank/ralph.git /tmp/ralph
# 复制核心文件到项目
mkdir -p scripts/ralph
cp /tmp/ralph/ralph.sh scripts/ralph/
cp /tmp/ralph/CLAUDE.md scripts/ralph/ # Claude Code 用户
# 或
cp /tmp/ralph/prompt.md scripts/ralph/ # Amp 用户
# 赋予执行权限
chmod +x scripts/ralph/ralph.shインストールが完了すると、プロジェクトの構造は次のようになります。
your-project/
├── scripts/ralph/
│ ├── ralph.sh # 核心循环脚本
│ └── CLAUDE.md # Claude Code 的 Prompt 模板
├── tasks/ # PRD 文件目录(执行时自动创建)
│ └── prd.json # 你的任务定义
└── ...提案: 最初の方法が最も簡単です。GitHub リンクを Claude Code に投げるだけです。インストール プロセスを手動で制御する場合は、方法 2 (マーケット コマンド) または方法 3 (手動コピー) を選択します。スクリプトをチームと共有する必要がある場合、またはスクリプトをカスタマイズする必要がある場合は、方法 4 を選択してください。
コアファイル構造
ラルフの記憶は完全にファイル システムに依存しています。各ファイルの役割を理解することは、Ralph を上手に使用するための前提条件です。
ralph.sh - ループエンジン
これは Ralph の核心であり、新しい AI インスタンスを常に生成する bash スクリプトです。
# 基本用法
./scripts/ralph/ralph.sh [max_iterations] # 默认:Amp
./scripts/ralph/ralph.sh --tool claude [iterations] # 使用 Claude Code反復ごとに、ralph.sh は次の手順を実行します。
- 機能ブランチを作成します (prd.json の
branchNameから) - 最も優先度の高い未完のストーリーを選択します (
passes: false) - このストーリーを実装するための 新しい AI インスタンスを生成します
- 品質チェックの実行 (タイプチェック、テスト)
- チェックに合格しました → git commit;チェックに失敗しました → 次の反復に残します
- prd.json を更新し、ストーリーを
passes: trueとしてマークします。 - 学んだ教訓を progress.txt に追加します。
- すべてのストーリーが完了するか、最大反復回数に達するまで繰り返します。
デフォルトの反復制限は 10 です。プロジェクトの複雑さに応じて調整します。
# 简单项目
./scripts/ralph/ralph.sh --tool claude 10
# 复杂项目
./scripts/ralph/ralph.sh --tool claude 50prd.json - タスク定義
これはラルフの「脳」であり、すべてのタスクが定義されます。これはフラットな JSON ファイルです。
{
"projectName": "Blog i18n Translation",
"branchName": "ralph/i18n-translation",
"userStories": [
{
"id": "US-001",
"title": "Translate homepage metadata",
"description": "Create content/docs/meta.en.json with English translations for all navigation items",
"acceptanceCriteria": [
"meta.en.json file exists with valid JSON format",
"All navigation titles are translated to English",
"pnpm types:check passes"
],
"priority": 1,
"passes": false,
"dependsOn": [],
"notes": "Reference the existing meta.json structure"
},
{
"id": "US-002",
"title": "Translate blog post hello-world",
"description": "Create content/blog/hello-world.en.mdx, translated from Chinese to English",
"acceptanceCriteria": [
"hello-world.en.mdx file exists",
"All QuoteCard components have defaultLang='en'",
"Internal links use /en/ prefix",
"Code blocks remain untranslated",
"pnpm types:check passes"
],
"priority": 2,
"passes": false,
"dependsOn": ["US-001"],
"notes": "Preserve MDX component props format"
}
]
}フィールドの説明:
| フィールド | 説明 |
|---|---|
projectName | ログとブランチの命名に使用されるプロジェクト名 |
branchName | Git ブランチ名 - Ralph が自動的に作成します |
id | ストーリーの一意の識別子、推奨される US-001 形式 |
title | 短いタイトル |
description | 詳細な説明 - 具体的であればあるほど良い |
acceptanceCriteria | 受け入れ基準のリスト - これは最も重要なフィールドです |
priority | 優先順位番号 - 番号が小さいほど、最初に実行されます。 |
passes | 完了したかどうか - Ralph は自動的に更新します |
dependsOn | 依存ストーリー ID リスト |
notes | 追加のヒントとコンテキスト |
progress.txt - 体験ログ
これがラルフの「長期記憶」です。各反復の後、AI は追加の学習エクスペリエンスを追加します。
=== Iteration 1 (US-001) ===
- Discovered: typecheck command is `pnpm types:check`, not `pnpm typecheck`
- Discovered: meta.en.json needs to mirror exact structure of meta.json
- Pattern: fumadocs i18n uses `.en.` suffix convention
=== Iteration 2 (US-002) ===
- Discovered: QuoteCard requires both `quote` and `quoteZh` props
- Gotcha: internal links must use /en/ prefix for English pages
- Pattern: code blocks should never be translated次の反復のためのクロードの新しいインスタンスは、このファイルを読み取り、すぐに以前のすべてのエクスペリエンスを取得します。これが、Ralph の実行がますます良くなっている理由です。繰り返しの間に知識は蓄積されますが、コンテキストはクリーンなままです。
AGENTS.md - 永続的な知識ベース
progress.txt に加えて、Ralph はプロジェクト内の AGENTS.md (または CLAUDE.md) ファイルも更新します。 Claude Code と Amp は両方とも、起動時にこれらのファイルを自動的に読み取ります。
progress.txt とは異なり、AGENTS.md はプロジェクト全体にわたる安定した知識を記録します。
# AGENTS.md
## Codebase Conventions
- Use fumadocs for documentation framework
- MDX files use custom components: QuoteCard, BlogImage, GlossaryCard
- i18n files use `.en.mdx` suffix
## Gotchas
- Always run `pnpm types:check` after modifying MDX files
- QuoteCard: set `defaultLang='en'` in English translationsPRD を書き込む
PRD (製品要件ドキュメント) の品質は、Ralph の実行結果を直接決定します。よく書かれています、ずっと順風満帆です、ラルフ。下手に書くと、ラルフは同じストーリーで何度も失敗することになります。
スキルを使用して PRD を生成する
snarktank/ralph スキルがインストールされている場合は、対話的に PRD を生成できます。
# 在 Claude Code 或 Amp 中
/prd I want to add i18n support to the blog, translating all Chinese content to EnglishAI は、いくつかの明確な質問 (どのドキュメントが関係しているか、テクノロジー スタックの制限、品質基準など) を尋ね、構造化された PRD ドキュメントを生成します。
生成後、/ralph コマンドを使用して PRD を prd.json 形式に変換します。
/ralph # 转换 PRD 为 prd.jsonPRD を手動で書き込む
prd.json を直接記述することもできます。以下は主要な設計原則です。
原則 1: ストーリーの粒度は中程度である
各ストーリーは 1 回の反復で完了できるほど小さく、独立して価値を提供できるほど大きい必要があります。
// ❌ 太大:一次迭代完不成
{
"id": "US-001",
"title": "Build complete user authentication system",
"description": "Implement registration, login, forgot password, OAuth, permission management..."
}
// ❌ 太小:没有独立价值
{
"id": "US-001",
"title": "Create email field on User table",
"description": "Add email field to User model"
}
// ✅ 刚好:一次迭代能完成,有独立价值
{
"id": "US-001",
"title": "Implement email/password login",
"description": "Create login API and login page with email/password authentication",
"acceptanceCriteria": [
"POST /api/auth/login accepts email + password",
"Returns JWT token",
"Login page form submits successfully",
"All tests pass"
]
}経験則: ストーリーには 1 ~ 3 つのファイル変更が含まれ、3 ~ 5 つの受け入れ基準があります。
原則 2: 受け入れ基準は自動的に検証可能でなければなりません
ラルフはストーリーが完了したかどうかを判断する必要があるため、受け入れ基準は客観的に評価可能である必要があります。
// ❌ 模糊的标准
"acceptanceCriteria": [
"Code quality is good",
"Performance is decent",
"User experience is smooth"
]
// ✅ 可验证的标准
"acceptanceCriteria": [
"pnpm types:check passes",
"pnpm test passes",
"API response time < 200ms",
"File src/auth/login.ts exists and exports loginHandler function"
]原則 3: dependOn を使用して実行順序を制御します
一部のストーリーには依存関係があります。 dependsOn フィールドは、Ralph が正しい順序で実行されることを保証します。
{
"userStories": [
{
"id": "US-001",
"title": "Create database schema",
"dependsOn": []
},
{
"id": "US-002",
"title": "Implement user registration API",
"dependsOn": ["US-001"]
},
{
"id": "US-003",
"title": "Implement login page",
"dependsOn": ["US-002"]
}
]
}原則 4: メモにコンテキストを提供する
メモフィールドは AI に追加のヒントを提供します。 AI が知らない可能性がある、あなたが知っている情報をここに書きます。
{
"notes": "Project uses fumadocs framework, i18n files follow .en.mdx suffix naming. Reference content/docs/notes/speckit/concept.en.mdx for translation style."
}ラルフループを実行する
PRD の準備ができたら、ループを実行します。
実行開始
# 使用 Claude Code,默认 10 次迭代
./scripts/ralph/ralph.sh --tool claude
# 指定迭代次数
./scripts/ralph/ralph.sh --tool claude 30
# 使用 Amp(默认)
./scripts/ralph/ralph.sh 20実行プロセス
開始すると、次のような出力が表示されます。
=== Ralph Loop - Iteration 1 ===
Branch: ralph/i18n-translation
Selected story: US-001 - Translate homepage metadata
Spawning fresh Claude instance...
[Claude Code executing...]
Quality check: pnpm types:check ... PASSED
Committing: feat: [US-001] - Translate homepage metadata
Updating prd.json: US-001 passes: true
Appending to progress.txt
=== Ralph Loop - Iteration 2 ===
Selected story: US-002 - Translate blog post hello-world
Spawning fresh Claude instance...各反復はクロードの完全に新しいインスタンスです。 prd.json を読み取ることで何をすべきかを認識し、progress.txt を読み取ることで以前に学習した内容を認識します。
###完全なシグナル
すべてのストーリーが passes: true とマークされると、Ralph は完了シグナルを出力して終了します。
All stories completed!
<promise>COMPLETE</promise>監視とデバッグ
Ralph の実行中に、次のコマンドを使用して進行状況を表示できます。
# 查看每个 story 的完成状态
cat tasks/prd.json | jq '.userStories[] | {id, title, passes}'
# 查看经验日志
cat progress.txt
# 查看最近的 git 提交
git log --oneline -10
# 实时跟踪 Ralph 输出
tail -f progress.txt自動アーカイブ
新しい機能を開始すると (別の branchName を使用して)、Ralph は最後に実行したファイルを archive/YYYY-MM-DD-feature-name/ ディレクトリに自動的にアーカイブし、作業ディレクトリをクリーンな状態に保ちます。
フィードバック ループと品質ゲート コントロール
ラルフの「自己修正」能力は、フィードバック ループの品質に完全に依存します。フィードバック ループがなければ、Ralph は盲目的にループする単なるスクリプトになります。コードが正しいかどうかを判断できないまま、コードを大量に出力し続けます。
品質チェックを構成する
CLAUDE.md(またはprompt.md)でQAコマンドを定義します。
## Quality Commands
After implementing each story, run these checks IN ORDER:
1. `pnpm types:check` — TypeScript type checking
2. `pnpm test` — Unit tests
3. `pnpm build` — Full build verification
If any check fails:
- DO NOT commit
- Fix the issue
- Re-run all checks
- Only commit when all checks pass品質アクセス制御レベル
| 階層 | ツール | 捕捉された問題 |
|---|---|---|
| 即時フィードバック | TypeScript コンパイラ | 型エラー、構文エラー |
| 機能検証 | 単体テスト | 論理エラー、特殊なケース |
| 統合検証 | ビルドコマンド | 依存関係の問題、構成エラー |
| 実行時検証 | 開発ブラウザスキル | UI レンダリングの問題 (フロントエンド プロジェクト) |
フロントエンド ストーリーの場合、Ralph は次の受け入れ基準を追加することを推奨しています。「開発ブラウザ スキルを使用してブラウザで検証する」 - AI に実際にブラウザを開いて、ページが正しくレンダリングされていることを確認させます。
品質チェックに失敗した場合
ストーリーが繰り返し QA に失敗した場合、Ralph は同じストーリーを無期限に再試行しません。反復上限に達すると停止し、現在の状態が保持されます。次のことができます。
- progress.txt を表示して、スタックの理由を理解します。
- 問題を手動で修正して、再度実行します。
- ストーリーの粒度を調整します (大きすぎる可能性があります)
- メモフィールドにコンテキストを追加します。
迅速なカスタマイズ
Ralph のプロンプト テンプレート (CLAUDE.md または prompt.md) は、AI の動作を制御する主な手段です。インストール後、プロジェクトに応じてカスタマイズする必要があります。
主要なカスタマイズ項目
1.プロジェクト固有の品質コマンド
## Project-Specific Commands
- Typecheck: `pnpm types:check` (not `tsc` or `pnpm typecheck`)
- Test: `pnpm vitest run`
- Build: `pnpm build`
- Lint: `pnpm lint`2.コードスタイルの制約
## Code Conventions
- Use TypeScript strict mode
- Prefer named exports over default exports
- Use fumadocs components for MDX content
- Follow existing file naming patterns (kebab-case)3.既知の落とし穴
## Known Gotchas
- MDX files: always import components at the top
- i18n: English files use `.en.mdx` suffix
- Links: English pages must use `/en/` prefix
- QuoteCard: set `defaultLang` to match the file language4.スタック時の対処
## When Stuck
If you cannot complete a story after 3 attempts within the same iteration:
1. Document what's blocking in progress.txt
2. Move to the next story if possible
3. Do NOT modify files unrelated to the current story実際のケース: Ralph によるブログの翻訳
Ralph が実際にどのように機能するかを示すために、実際の例を示します。Ralph スタイルの自律エージェントを使用して、ブログ全体を中国語から英語に翻訳します。
プロジェクト設定
このプロジェクトでは、22 以上のコンテンツ ファイル (ブログ投稿、ドキュメント、ナビゲーション メタデータ) を中国語から英語に翻訳する必要があります。このプロジェクトは fumadocs の Next.js ブログに基づいており、i18n をサポートしています。このタスクは prd.json ファイルで定義されており、それぞれに明確な受け入れ基準を持つ 16 のユーザー ストーリーが含まれています。
scripts/ralph/
├── prd.json # 16 个 user story,带验收标准
└── progress.txt # 经验日志,每个 story 完成后更新すべてのユーザー ストーリーは一貫したパターンに従います。
- 明示的な成果物: "コンテンツ/blog/xxx.en.mdx を作成"
- 検証可能な基準: 「タイプチェックに合格」、「内部リンクは /en/ プレフィックスを使用」
- 技術的制約: 「コード ブロックを翻訳しないようにする」、「QuoteCard にdefaultLang='en' を設定する」
実行モード
エージェントは、ラルフの方法論の中核原則に従います。
-
文書は真実の情報源です:
prd.jsonはどのストーリーが通過したかを追跡します (passes: true/false)。progress.txt反復の間に経験を積みます - 例: 「Typecheck コマンドはpnpm types:checkであり、pnpm typecheckではありません」 -
自動品質ゲート: 各翻訳の後、
pnpm types:checkが実行され、MDX ファイルが正しくコンパイルされたかどうかが検証されます。型チェックが失敗した場合は、送信する前に修正してください。 -
段階的な進歩: 各ストーリーは、説明的な提出情報 (
feat: [US-003] - Translate blog/claude-code-quality-control.mdx) とともに個別に提出され、必要に応じて簡単にロールバックできます。 -
並列実行: 長い記事の場合、複数のサブエージェントが同時に翻訳されます。たとえば、US-010 (claude-skills コンセプト + プラクティス)、US-011 (speckit コンセプト + プラクティス)、および US-012 (claude-architecture + claude-subagent) が並行して実行されます。
重要な教訓
| 経験 | 詳細 |
|---|---|
| 知識の蓄積は重要です | 初期のストーリーで発見されたパターン (QuoteCard defaultLang、リンク プレフィックス ルール) により、後続のストーリーをより速く完了できるようになります。 |
| フィードバック ループとしての型チェック | 問題が積み重なる前に、欠落しているインポートや不正な MDX を検出します。 |
| 並列化されスケーラブル | 6 つの翻訳エージェントが同時に実行され、完了時間は 1 つのエージェントとほぼ同じです。 |
| PRD の粒度は重要です | スコープはストーリーごとに 1 ~ 2 ファイル - 確実に完了するのに十分な大きさ、意味のあるのに十分な大きさ |
| 進捗状況ログにより、ミスの繰り返しを防止 | progress.txt の「コードベース パターン」部分は、同じ問題の再発見を防ぐためのナレッジ ベースになります。 |
結果
16 のユーザー ストーリーすべてが 1 回のセッションで完了しました。8 つの meta.en.json ナビゲーション ファイルが作成され、3 つのブログ投稿が翻訳され、12 のドキュメント ページが翻訳され、完全なサイトの構築が検証されました。受け入れ基準が明確であり、フィードバック ループ (タイプチェック) が問題を即座に検出するため、各翻訳は一貫した品質を維持します。
このプロジェクトは、Ralph の 完全な実装モデル - 明確に定義されたタスク + 明確な成功基準 + 自動検証 + ファイル システムを介した増分配信を実証します。
コミュニティの実装と代替案
スナークタンク/ラルフが唯一の選択肢ではありません。これらの実装にはそれぞれ、ニーズに応じて独自の長所と短所があります。
| リソース | リンク | 説明書 |
|---|---|---|
| スナークタンク/ラルフ | スナークタンク/ラルフ | この記事で使用される、最も完全な関数 |
| ラルフ・オーケストレーター | マイクヨブリエン/ラルフオーケストレーター | Mickey O'Brien によって開発され、より多くのカスタマイズ オプションを備えています。 |
| ラルフ・ループ・エージェント | vercel-labs/ralph-loop-agent | AI SDK に基づく Vercel の実装 |
| ラルフィー | マイケルシメレス/ラルフィー | Michael Shimeles による軽量実装 |
代替: GSD
GSD は厳密には Ralph の「コミュニティ実装」ではなく、代替です。これは、Ralph の中心原則 (コンテキスト管理、アトミック タスク) を適用していますが、より完全なワークフロー (議論→計画→実行→検証) を提供します。
| リソース | リンク | 説明書 |
|---|---|---|
| GSD (ゲット・スタッフ・ダン) | キラキラカウボーイ/くそったれ | アイデアから PRD、実行までの完全なフレームワーク |
Ralph が「生」すぎて、より多くのプロセス サポートが必要だと感じる場合は、GSD の方が適している可能性があります。詳細については、GSD の詳細な分析 を参照してください。
推奨リソース
公式情報源:
| リソース | リンク | 説明書 |
|---|---|---|
| ジェフリー・ハントリーのブログ | ghuntley.com/ralph | 発明者によるオリジナル記事 |
| ラルフ・ウィガムのハウツー | ガントリー/ラルフ・ウィガムのハウツー | 公式ユーザーガイド |
ビデオチュートリアル:
| リソース | リンク | 説明書 |
|---|---|---|
| ラルフ・ウィガムの徹底したディスカッション | なぜクロードコードの実装ではないのか | Geoffrey Huntley が正式な実装の問題点を説明します |
| Ralph の正しい使い方 | ラルフ ウィガム ループの使い方は間違っています | Roman (Mentat) の使用デモ |
| ラルフについて話さなければなりません | ラルフについて話さなければなりません | 論争に対するテオの分析 |
ベスト プラクティスとよくある質問
コスト管理
Ralph の自動実行は、API 料金が継続的に発生することを意味します。いくつかの管理措置:
- 常に
max_iterationsを設定します: これは最も基本的なセーフティ ネットです - ストーリーの粒度を適度に保ちます: ストーリーが大きすぎると、複数の反復が必要になります。ストーリーが詳細すぎると、起動時のオーバーヘッドが増加します。
- 最初は小規模なテスト: 新しいプロジェクトは最初に 3 ~ 5 回繰り返し実行され、プロンプトと品質アクセス制御が適切に機能していることを確認した後に拡張されます。
よくある落とし穴
罠 1: ストーリーが大きすぎる
症状: ストーリーが繰り返し失敗し、反復回数がすぐに使い果たされてしまいます。
解決策: 2 ~ 3 つの小さなストーリーに分割します。 「完全な認証システムの構築」は、「ログイン API の実装」+「ログイン ページの作成」+「JWT ミドルウェアの追加」に分かれています。
トラップ 2: フィードバック ループがない
症状: ラルフはストーリーが完了したと主張していますが、実際のコードには何か問題があります。
解決策: 実行可能チェック コマンドを受け入れ基準に追加します。 「コードが書かれている」は合格基準ではなく、「pnpm テストにすべて合格する」が合格基準です。
トラップ 3: progress.txt は使用されません
症状: 同じエラーが異なる反復で繰り返し表示されます。
解決策: プロンプト テンプレートで「progress.txt を読み、そこに含まれるルールに従う」ことを明示的に指示していることを確認してください。 AIが自動的に経験値を追加しない場合は、プロンプトに「各ストーリーが完了したら、progress.txtに経験値を追加します」と追加してください。
トラップ 4: 依存関係の順序が間違っている
症状: ストーリーがまだ存在しないコードに依存しているため、実装が失敗します。
解決策: dependsOn フィールドを正しく設定します。インフラストラクチャの話を必ず最初に置いてください。
FAQ
**Q: Ralph と公式プラグインの違いは何ですか? **
主な違い: snarktank/ralph は反復ごとに新しいプロセス (実際には完全に新しいコンテキスト) を生成しますが、公式プラグインは同じセッション内でループします (コンテキストは蓄積し続けます)。詳細は前回の記事の分析を参照してください。
**Q: prd.json は実行中に手動で変更できますか? **
はい。 Ralph は、各反復の開始時に prd.json を再読み込みします。反復間でストーリーの説明を変更したり、新しいストーリーを追加したり、ストーリーを手動で passes: true としてマークしたり (スキップ) することができます。
**Q: 何度も失敗するストーリーに行き詰まった場合、ラルフはどうすればよいですか? **
- progress.txt を確認して、失敗の理由を理解します。
- メモにコンテキストを追加する
- ストーリーを分割します (大きすぎるかもしれません)
- ブロックの問題を手動で修正して、再度実行します。
**Q: ラルフの実行中に他のことをすることはできますか? **
はい。ラルフは「人間としての役割を果たす」ように設計されており、じっと見つめる必要はありません。 AFK モードでは、仕事を降りる前に開始し、翌朝結果を確認します。 Ralph が作業しているファイルを変更しないでください。
**Q: コストを管理するにはどうすればよいですか? **
3 つの方法: 適切な max_iterations を設定する、ストーリーの粒度を適切に保つ (無駄な反復を減らすため)、最初に小規模な試行を実行してプロセスが正しいことを確認します。一般的に、10 ~ 20 ストーリーのプロジェクトの場合、API 料金は 50 ~ 100 ドル以内です。
概要
ラルフのワークフローは 5 つのステップに要約できます。
安装 → 编写 PRD → 配置质量门禁 → 运行循环 → 检查结果中心となる概念は変わりません。ドキュメントを唯一の真実の情報源とし、各反復をゼロから開始し、品質ゲートに制御してもらいます。
次に、プロジェクトに戻り、prd.json を準備し、./scripts/ralph/ralph.sh --tool claude を実行して、コーヒーを作りに行きます。
さらに読む
- ラルフ ウィガムの詳細な分析 - ラルフの核となる原則を再考する
- GSD の詳細な分析 - Ralph に基づいて構築された完全なコンテキスト エンジニアリング システム
- クロードスキルとは ——ラルフのPRDスキルはクロードスキルです
- Speckit 実践ガイド - もう 1 つの構造化された AI プログラミング ワークフロー