Skill-Creator の詳細な分析: データを使用してスキル開発を推進します
Anthropic の公式「メタスキル」スキルクリエイターの詳細な分析 - クロード コード スキルを体系的に作成、テスト、評価、最適化し、スキル開発を直感主導からデータ主導に変える方法
はじめに
この記事は 2026 年 3 月の情報に基づいており、Claude Code v2.1 以降に対応しています。
概念 と 実践 を読んだことがあれば、SKILL.md ファイルを手動で作成する方法をすでに知っているはずです。フロントマッターを定義し、コマンドを作成し、それを .claude/skills/ ディレクトリに保存すれば完了です。
しかし、ここで基本的な質問があります: **自分のスキルが本当に役に立つとどうやってわかりますか? **
段落の文言を変更して、より良く機能したと感じるかもしれませんが、それはあなたの主観的な感覚にすぎません。おそらく、別のプロンプト単語があれば、新しいバージョンはさらに悪化するでしょう。もしかしたら、あなたのスキルは未熟な状態に比べてまったく向上していないかもしれません。クロードは一人でも十分にできます。
概念的な章と実践的な章では、スキル開発のプロセスは次のとおりです: **書いた → 試した → 大丈夫だと感じた → オンライン **。プロセス全体は直感に依存しており、定量化はなく、「このスキルは、スキルをまったく持たない場合よりもどの程度優れているか?」に答える方法がありません。そして、Skill-Creator はこれをエンジニアリングに変えました。筆記 → スキルあり / なしの並行テスト → ブラインド テスト A/B 比較 → 定量的スコアリング → フィードバックの反復 → データ検証。
The skill-creator turns skill creation from art into engineering — you can now test, measure, and systematically improve your skills instead of relying on intuition alone.
これがスキルクリエイターの存在理由です。 「SKILL.md の生成」を支援するだけでなく、作成 → テスト → 評価 → 最適化のループの完全なセットを提供し、データそのものに語らせることができます。
スキルクリエイターとは
Anthropic によって公式に提供される「メタ スキル」 - 他のスキル を作成、テスト、最適化するために特に使用されるスキル 。評価フレームワーク、ブラインド テストの比較、記述の最適化などの機能が組み込まれており、スキル開発を「書いて試してみる」から「データ駆動型の反復エンジニアリング」にアップグレードします。
Improving skill-creator: Test, measure, and refine Agent Skills
The official blog post announcing skill-creator improvements with eval, improve, and benchmark capabilities.
Skill-Creator 自体もスキルです。33KB の SKILL.md ファイルに加えて、サブエージェント ガイダンス ファイル、Python スクリプト、および HTML ビューアをサポートしています。そのディレクトリ構造は次のようになります。
skill-creator/
├── SKILL.md # 主指令文件(486 行)
├── agents/ # 子代理指导
│ ├── grader.md # 评分代理
│ ├── comparator.md # 盲测对比代理
│ └── analyzer.md # 分析代理
├── eval-viewer/ # 评估结果查看器
│ ├── generate_review.py
│ └── viewer.html
├── assets/
│ └── eval_review.html # 触发评估审查界面
├── scripts/ # Python 工具脚本
│ ├── run_eval.py # 运行触发评估
│ ├── run_loop.py # 优化循环
│ ├── improve_description.py # 描述优化
│ ├── aggregate_benchmark.py # 聚合基准测试
│ ├── package_skill.py # 打包为 .skill 文件
│ └── quick_validate.py # 快速校验
└── references/
└── schemas.md # JSON Schema 定义インストールも非常に簡単です。
# 通过 Claude Code 插件市场
/plugins # 然后搜索 skill-creator 安装
# 或通过 skills.sh
npx skills add anthropics/skills -- skill skill-creatorもう一度これに従います: 既存のスキルを評価して最適化する
私が実際に使用しているスキルを使用して、Skill-Creator の完全なプロセスを見てみましょう。私はクロード コード プラグイン マーケット yux-claude-hub を管理しています。このマーケットでは、yux-video-summary スキルを使用してビデオ字幕を構造化された要約に変換します。中国語と英語の言語検出、DUAL_FILE/SINGLE_FILE の 2 つの出力モード、フィラーワードクリーニングなどをサポートしています。スキルの SKILL.md は次のようになります。
---
name: yux-video-summary
description: Transform a video transcript file into a structured,
organized summary with key points, timeline, and cleaned transcript.
Use when the user has a transcript file and wants it summarized.
allowed-tools: Read, Write, Glob, Grep
---スキルは書かれていますが、それが本当に役立つかどうかはどうやってわかりますか? ** ここで Skill-Creator が登場します。
Skill-Creator のソース コードには重要な記述原則があります: 「すべての背後にある理由を一生懸命説明してください。ALWAYS または NEVER をすべて大文字で書いていることに気付いたら、それは黄色の旗です。フレームを再構成して理由を説明してください。」 意味: 優れたスキルは、厳格なルールを積み上げるのではなく、理由を説明する必要があります。
ステップ 1: テスト ケースを作成し、評価を実行する
主な質問: **このスキルは本当にスキルがないより優れていますか? **
クロード コードを開き、次のように直接入力します。
Use the skill creator to create evals for the yux-video-summary skillSkill-Creator は、まずスキル定義とスキーマを読み取り、次にテスト ケースと定量的アサーションを自動的に生成します。私の実行では、3 つのテスト ケースと 39 のアサーションが生成されました。

テスト ケースを無造作にコンパイルするわけではないことに注意してください。スキルで定義されている DUAL_FILE と SINGLE_FILE の 2 つの出力モードを理解し、さまざまなビデオ タイプ (チュートリアル、ポッドキャスト インタビュー、テクノロジー共有) と言語の組み合わせをカバーするシナリオを具体的に設計します。アサーションの設計も非常に特殊で、言語検出、出力モードの選択からコンテンツの品質、中国語と英語のフィラーワードのクリーニングに至るまで、自分でディメンションをテストするよりもはるかに包括的です。
Skill-Creator のコンテキストでは、Eval はスキル の体系的なテストである を指します。各 Eval には、テスト プロンプト (プロンプト)、予想される出力の説明、および定量的アサーション (アサーション) が含まれています。システムは熟練バージョンと非熟練バージョンの両方を同時に実行し、結果を比較します。
次に、システムはテスト ケースごとに 2 つの独立したサブエージェント、with_skill (スキルのロード) と without_skill (ベースライン、スキルはロードされない) を同時に開始します。 6 つの並列エージェント (3 つのテスト ケース × 2 バージョン) が一度に開始され、それぞれが互いに干渉することなく 独立したワークツリー で実行されました。
Anthropic の PDF スキルは以前、入力不可能なフォームの処理に問題がありました。クロードはフィールドを定義せずにテキストを正確な座標に配置する必要がありました。 Eval を通じて障害点が特定され、その後チームは位置決めロジックを修正しました。それが Eval の価値です。「何かが正しくないと感じられる」を「ここで正確に何が間違っているのか」に変えるのです。
ステップ 2: 3 人のサブエージェントがスコアリングをリレーします。
すべての操作が完了すると、3 つの専門的なサブエージェントが 自動的に 順番に表示されます。
採点者 アサーションを 1 つずつ検証します。 with_skill バージョンの概要に概要テーブルが含まれているかどうか、DUAL_FILE モードが正しく選択されているかどうか、フィラー ワードがクリーンアップされているかどうかを確認し、各項目の合格/不合格と証拠を記録して、grading.json を生成します。
{
"expectations": [
{ "text": "摘要包含 Overview 表格", "passed": true, "evidence": "Found overview table with Type, Duration, Language fields" },
{ "text": "正确选择 DUAL_FILE 模式", "passed": true, "evidence": "Generated separate summary and transcript files" },
{ "text": "filler 词已清理", "passed": false, "evidence": "Found 'you know' in transcript line 42" }
],
"summary": { "passed": 2, "failed": 1, "total": 3, "pass_rate": 0.67 }
}Comparator はブラインド A/B 比較を行います。2 つの概要を受け取りますが、どれがスキル バージョンでどれがベースライン バージョンであるかはわかりません。 「アウトプットA」と「アウトプットB」のみを見て、独自の品質基準に基づいて独自に審査し、勝者を決定します。
Comparator サブエージェントが 2 つの出力を比較する場合、 はどちらがスキル バージョンのもので、どちらがベースライン バージョン のものであるかを知りません。 「出力 A」と「出力 B」だけを見て、生成した品質基準に基づいて独立して判断し、最終的に勝者または引き分けを決定します。この設計により、評価の偏りが排除されます。
Analyzer は上記の結果を組み合わせて、スキルに関係なくどのアサーションが合格したか (このアサーションには区別がなく、より良いアサーションに置き換える必要があることを示します)、どの結果の分散が大きいか (テストが不安定である)、時間とトークンの間のトレードオフは何か、などの診断を行います。最後に、改善のための提案が示されます。
ステップ 3: Eval Viewer で結果を確認する
スコアリングが完了すると、Skill-Creator はブラウザで HTML ビューアを自動的に開きます。
[出力] タブ 各テスト ケースの出力を 1 つずつ表示できます。下部にフィードバック テキスト ボックスがあります。「要約にタイムラインが欠けている」「つなぎ言葉が整理されていない」など、不十分だと思われる点を書き留めてください。すべての使用例を読んだ後、すべてのレビューを送信 をクリックすると、フィードバックが feedback.json に保存されます。
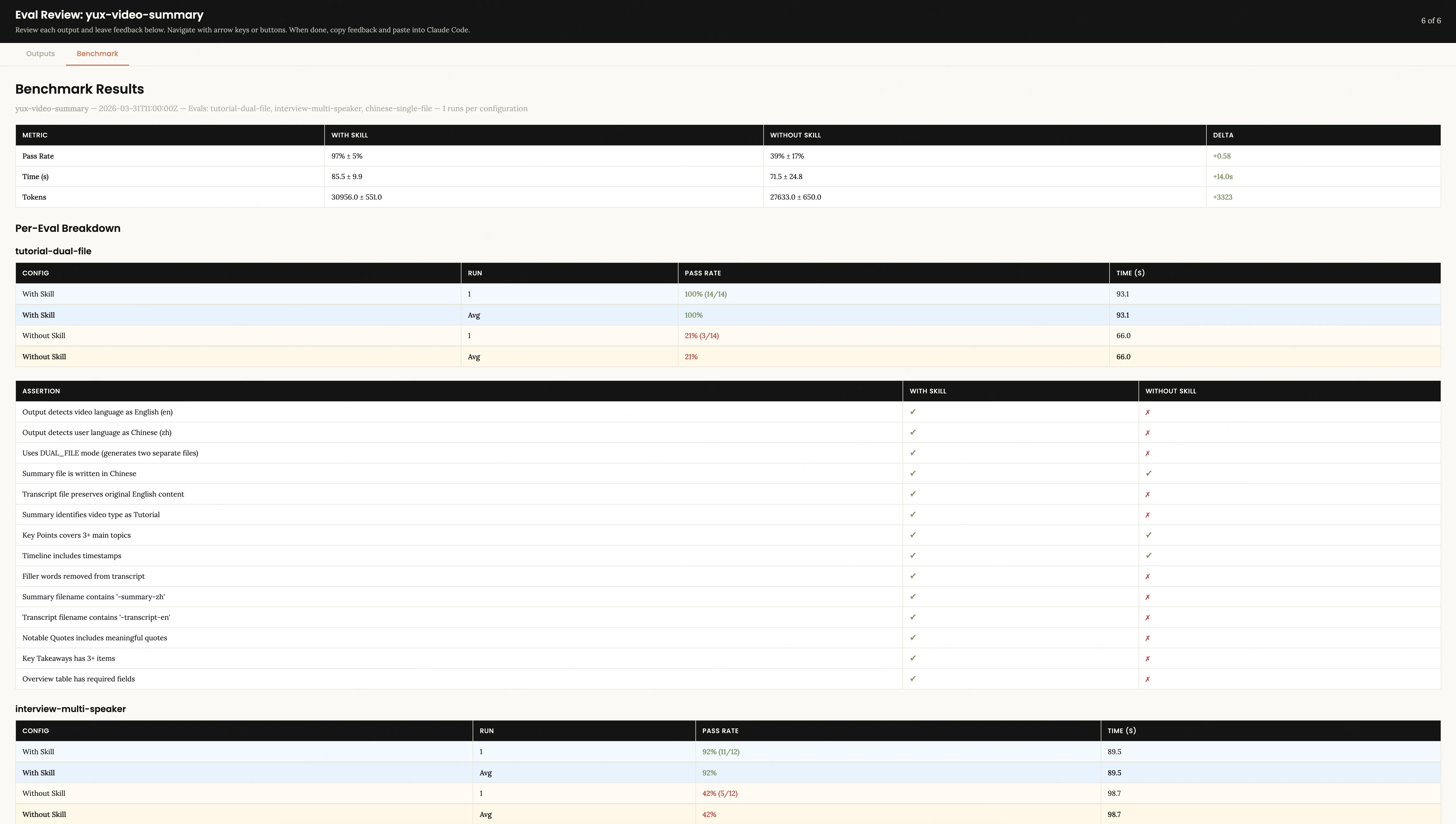
[ベンチマーク結果] タブ 定量的な比較 (with_skill と without_skill の合格率、消費時間、トークン消費、および各アサーションの項目ごとの比較) を確認できます。
ステップ 4: 満足するまで繰り返して改善する
Claude Code に戻り、フィードバックの提供が終了したことを伝えます。 Skill-Creator は feedback.json を読み取り、ベンチマーク データに基づいて分析と改善の提案を行います。

私のスキルは合格率 97% と好調でした。 Skill-Creator は、小さな問題を正確に特定しました。インタビュー ビデオには注目に値する引用文の段落が欠けており、それを修復するための提案を行いました。
重要なのは、個々のテスト ケースにパッチを適用しないことです。フィードバックを一般化し、その背後にある要件を理解し、スキルの全体的な構造を調整してから、SKILL.md を書き換え、すべてのテストを iteration-2/ ディレクトリに再実行して、新しい Eval Viewer を開いて 2 つのラウンドの出力を比較できるようにします。このサイクルは満足するまで続きます。
Skill-Creator ソース コードの注目すべき改善哲学: 「私たちは、さまざまなプロンプトで何百万回も使用できるスキルを作成しようとしています。厄介な過剰適合の変更や、抑圧的な MUST を加えるのではなく、頑固な問題がある場合は、分岐して別のメタファーを使用してみてください。」 中心的なアイデア: 過剰適合を回避して、テスト ケースを作成し、一般化機能を追求します。
ステップ 5 (オプション): スキルが適切なタイミングで発動するように説明を最適化します。
スキルの品質は検証されていますが、見落とされやすい別の問題があります。それは、スキルの description フィールドによって、クロードがいつそれを呼び出すかが決定されるということです。
入力:
Use the skill creator to optimize the description for yux-video-summarySkill-Creator は約 20 の評価クエリを自動的に生成し (半分はトリガーする必要があり、半分はトリガーしないでください)、レビュー インターフェイスがブラウザーで開きます。
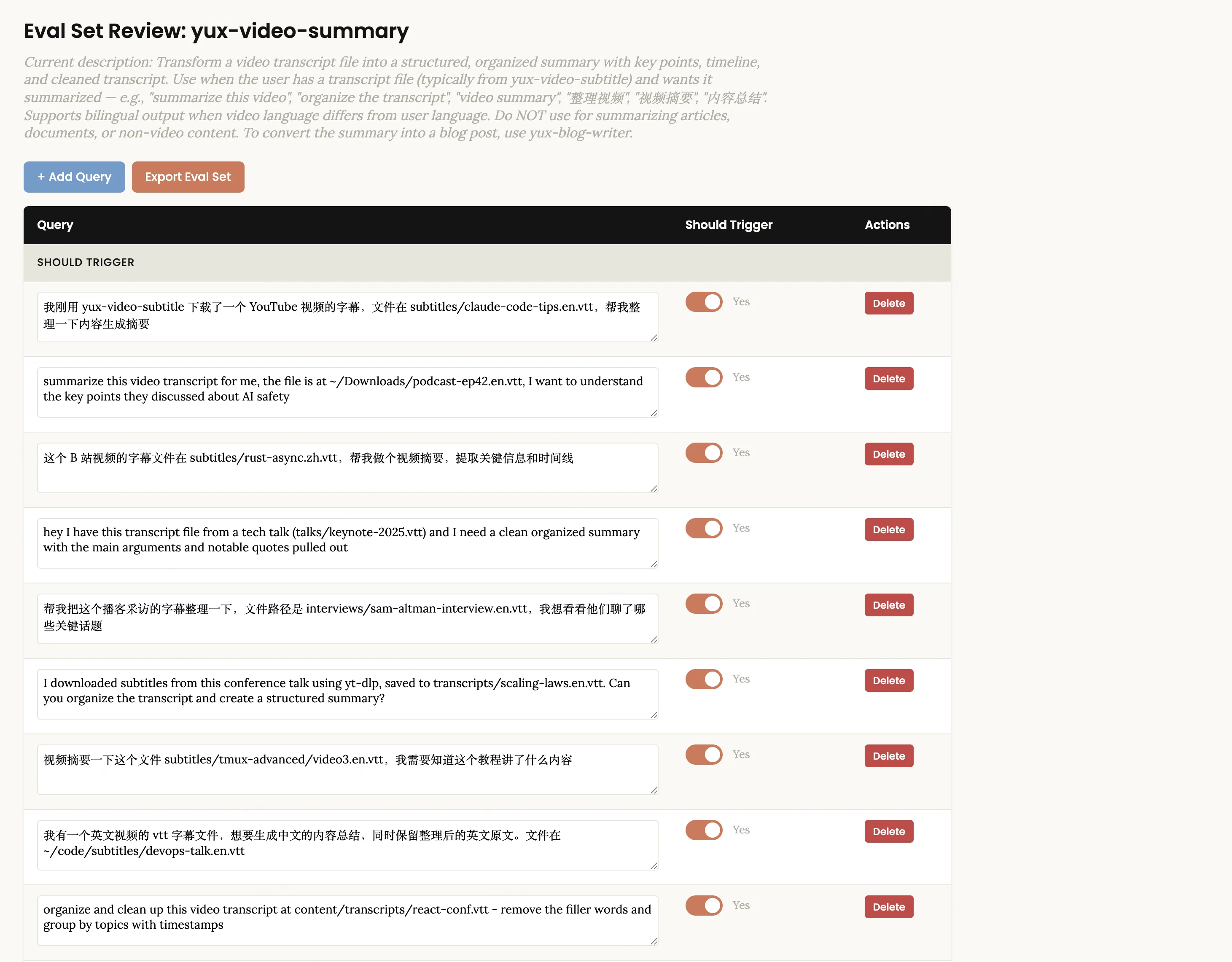
これらのクエリは中国語と英語の両方で利用でき、実際のさまざまな表現をカバーしていることに注意してください。 「トリガーすべきではありません」クエリはあまりにも法外であってはなりません。良い反例は「この会議の議事録を要約するのを手伝ってください」です。これはキーワード「要約」をビデオ要約と共有していますが、実際にはビデオ要約よりも文書処理スキルが必要です。
ページ上でクエリ テキストを直接編集したり、[+ クエリの追加] をクリックして新しいクエリを追加したり、[削除] ボタンを使用して不適切なクエリを削除したり、クエリごとに [トリガーする必要がある] スイッチを切り替えることもできます。正しいことを確認したら、[評価セットのエクスポート] をクリックして JSON ファイルをエクスポートします。 Claude Code に戻り、エクスポートしたことを伝えます。システムはバックグラウンドで最適化ループを自動的に実行します。

プロセス全体は完全に自動化されており、クエリをトレーニング セットとテスト セット 60/40 に分割し、トレーニング セットの記述を繰り返し最適化し (最大 5 ラウンド)、テスト セットの結果を使用して、過学習を回避する最適なバージョンを選択します。実行後、最適化前後の説明の比較が出力されます。

最適化された説明はより具体的になります。サポートされるファイル タイプ (.vtt/.srt) が明確になり、パイプライン機能 (フィラー クリーニング、DUAL/SINGLE_FILE ロジック) が強調され、MUST USE を使用してトリガーされるべきではないシナリオが除外されます。 Anthropic は、内部でこのオプティマイザーのセットを使用して、独自のドキュメント作成スキルを実行しました。これにより公開スキル6種類中5種類の発動精度が向上しました。
高度な使用法: 動的なコンテキスト インジェクション
スキルのロード時にコンテキストを自動的に挿入する場合は、スキル 2.0 の ! 構文を使用して SKILL.md にシェル コマンドを埋め込むことができます。
## Project Context
File tree: !`find . -type f -not -path '*/node_modules/*' | head -50`
Package info: !`cat package.json 2>/dev/null || echo "No package.json"`
Recent commits: !`git log --oneline -10`これらのコマンドはクロードがスキルを確認する前に実行され、データはプロンプトに直接埋め込まれます。クロードにファイルを 1 つずつ探索させる場合と比較して、時間とトークンを大幅に節約できます。
2 種類のスキル: どちらを作成する必要がありますか?
Skill-Creator を使用する前に、Anthropic によって定義された 2 つのスキル タイプを理解する必要があります。
能力向上型 - 今までできなかったこと、うまくできなかったことをモデルにやらせます。たとえば:
- 画像生成スキル:クロードはネイティブで画像を生成できませんが、スキルを通じてナノバナーなどのツールを呼び出すことで実現できます。
- フロントエンド設計スキル: デフォルトの AI 設計は非常に「AI 風味」であることが多く、優れた設計スキルにより品質が大幅に向上します。
コーディング設定 - 特定のワークフローを確立します。モデルにはすでに個別の機能が備わっていますが、正確な実行順序が必要です。たとえば:
- PRレビュースキル:一定の手順に従ってコードのセキュリティをチェックし、リスクレベルレポートを出力
- ビデオ要約スキル: 特定のテンプレート構造に従った出力、自動言語検出、フィラーワードクリーニング
これら 2 つのタイプのスキルをテストする必要がある理由は異なります。 能力向上タイプは、モデルが進化するにつれて不要になる可能性があります。ベースライン (without_skill) もすべてのアサーションを通過できる場合、モデルが十分にネイティブであることを意味し、このスキルは廃止できます。 コーディング タイプ は耐久性が高くなりますが、ワークフローに本当に忠実であるかどうかを検証する必要があります。
Skill-Creator の評価機能を使用すると、古くなった可能性のあるスキルを盲目的に使用するのではなく、スキルがまだ価値があるかどうかを継続的に検証できます。
コミュニティの意見
Skill-Creator のアップデートは、X/Twitter から Reddit、独立したブログに至るまで、多くの議論を引き起こしました。実際のフィードバックは公式ドキュメントよりも価値があります。
それは本当に役に立ちますか?データが語る
最も直接的な質問は、スキルを追加した方が、スキルを追加しないよりも本当に優れているのかということです。 ** いくつかの実測により明確な答えが得られます。
Reddit u/hashpanak がタイトル生成スキルの評価を実行したところ、with_skill では 100% の合格率でしたが、With_skill ではわずか 60% でした。トークンのコストに見合う価値があるかどうか尋ねると、彼は「その通りです。最適化後は、繰り返されるタスクをスクリプトに変換できるため、トークンを節約できます。」と答えました。 u/spences10 はさらに極端です。彼は 250 のサンドボックス評価を実行し、スキルのアクティブ化率を 84% から 100% に増加させました。コメントセクションの u/Manfluencer10kultra は次のように述べています。「これは標準的な慣行になるはずです。」
ブロガー Nathan Onn による WordPress セキュリティ スキルのベンチマークテスト: 21 のアサーションすべてに合格し (ベースラインは 90.5% のみ)、速度は 9.9% 速くなりました。彼の要約: 「スキルはかつては芸術でしたが、今ではエンジニアリングです。」
@0zhuxiaofeng 氏は、実際のワークフローの観点から、より具体的な数値を示しました。「1 か月間使用してみて、最大の変化は、run_eval によってスキル自体がスコアリングできるようになったということです。コンテンツ操作を実行するエージェントは、各リリース後に効果を自動的に評価するようになり、不十分なスキルは直接排除され、書き直されます。手動介入が 1 日 3 時間から 30 分に短縮されました。」
見落とされている盲点: トリガー ≠ 品質
ブロガー Mager は、誰も言及していなかった盲点を指摘しました。 スキルは品質評価に合格することもありますが、トリガー評価では失敗します - 出力品質は非常に優れていますが、決して呼び出されることはありません。 run_loop.py 最適化を 3 ラウンド行った後、彼は eval を 13/13 にトリガーしました。核となる洞察: 「スキルの説明はメタデータではなく、学習可能なパラメーターです。実際のルーティング動作を最適化する必要があります。」
これは、@DrWang5257 の提案と一致します。「一度に全体を書き直さないでください。まず、トリガー条件、入力テンプレート、失敗フォールバックの 3 つのセクションに分割し、ステップごとに繰り返します。この方法では、更新速度が速く、ロールオーバー率が低くなります。」
本当の問題点
効果は良好ですが、落とし穴もたくさんあります。
- トークンの消費量が膨大です。 @konghao10 は、「トークンの消費量は膨大だ」と率直に言いました。6 つの並列エージェントを同時に実行するのは実際には安くありません。 Reddit u/munkymead も「本格的な検査を受けるには費用がかかる」とも述べている。
- スキルが多すぎると戦闘になります。 RoboRhythms ブロガー Noah Albert は、スキルが 8 ~ 10 に達すると問題が発生し始めることを発見しました。クロードは出力を自問し、より冗長な序文を生成し、スキル間でコマンドの競合が発生することがあります。しかし、Reddit u/Specialist_Solid523 は、「下手に書かれたスキルはコンテキストを消費するだけです。よく書かれたスキルは、ほとんどの場合、トークンの使用をより効率的にします。」と反論しました。
- SKILL.md は反復回数が増えると長くなる。 Reddit u/IulianHI は矛盾を指摘しました。改善を繰り返すことで、スキル ファイルは拡張し続けます ** が、実際に何かを行うためのコンテキスト ウィンドウが押し出されてしまいます **。ハッピー パスのみをカバーするテスト ケースは、重要な 5% を見逃します。
- バージョン管理がありません。 @fengqve は「スキル ** にはバージョンという概念がないのはなぜですか? これは何度も更新されているため、どの更新であるかを説明するのが難しいです。」と不満を述べています。これは、複数ラウンドの繰り返しの後では特に苦痛です。
- ヘッドレスモードにはバグがあります。 GitHub には重要な問題があります。スキルが
claude -pモードではトリガーされず、最適化ループを説明するリコールが常に 0% になります (#36570)。
さらに考える: 再帰的な自己改善
@vista8 は関連する論文 [Memento-Skills: Let Agents Design Agents] (https://github.com/Memento-Teams/Memento-Skills) を共有し、コメント エリアの誰かがそれを正確に要約しました。「スキルの中心的なボトルネックは反復です。最初のバージョンを作成するのは簡単ですが、実際のシナリオでより良く使用できるようにするのは困難です。この「使用→評価→改善」サイクルを自動化できれば、それはエージェントに自己進化エンジンをインストールするのと同じです。」
Reddit r/ClaudeAI の 104 のようなスレッドでも、この方向性について議論されています。しかし、一番上のコメントはそれに冷水を浴びせた。u/Tatrions は次のように述べた。「再帰ループは機能しますが、難しいのは改善をいつ信頼するかを判断することです。証拠のゲートを行う必要があることがわかりました。少なくとも 2 回失敗しない限り、変更をコミットしないでください。そうしないと、各サイクルが最初から壊れていないものを「修正」することになり、最終的にはさらに悪化することになります。」
設置とエコロジー
Skill-Creator は、Anthropic によって公式に管理されているスキルの 1 つとして、anthropics/skills ウェアハウスに含まれており、17 以上の製品レベルのスキルが含まれています。
より広範なスキル エコシステムも急速に成長しています: skills.sh 市場は便利な検出とインストールのエクスペリエンスを提供し、コミュニティは 1,234 以上のエージェント スキルを維持しています。
The Complete Guide to Building Skills for Claude
A comprehensive 33-page guide covering skill fundamentals, planning, testing, distribution, and YAML frontmatter reference.
Claude Code Agent Skills 2.0: From Custom Instructions to Programmable Agents
A deep dive into Skills 2.0 architecture, context forking, and the programmable agent paradigm.
最後に書きます
Skill-Creator が解決する中心的な問題は次のとおりです: **自分のスキルが本当に効果的であることはどのようにしてわかりますか? **
それがない場合、スキル開発は「書く→試す→大丈夫と感じる」に依存します。 Skill-Creator を使用すると、次のことが可能になります。
- Parallel Agent を使用して、熟練した効果と未熟な効果の両方をテストします
- ブラインド A/B 比較 により評価バイアスを排除
- Eval Viewer を使用して結果を視覚化し、フィードバックを残す
- Description Optimizer を使用して、スキルの発動タイミングを正確に制御します
- 反復ループを使用して、満足するまで継続的に改善します
これは、ソフトウェア エンジニアリングにおけるテスト駆動開発の概念、つまり「コードを書いて実行できると考えるだけ」ではなく、「実際に期待どおりに動作することをテストによって証明する」という概念と一致しています。
Anthropic は公式ブログで興味深い見通しを提示しました。モデルの機能が向上するにつれて、SKILL.md は「実装計画」 (クロードに どのように を伝える) から「仕様の説明」 (クロードに 何を 伝え、モデルにそれを独自に理解させる) に進化する可能性があります。 Eval フレームワークは、この方向への最初のステップです。Eval は「何をすべきか」を説明します。いつかこの記述自体がスキルになるとしたら、スキルクリエイターが確立したテスト制度はさらに重要なものになるでしょう。
すでにスキルを使用している場合は、/skill-creator を使用して、最もよく使用されているスキルを評価してみてください。一部のスキルは、実際にはまったくスキルがないことよりも優れているわけではないことに驚くかもしれません。そこから最適化が始まります。
Extend Claude with skills
Official documentation for Claude Code Skills — structure, frontmatter fields, and best practices.
関連書籍:
- クロード スキルとは — スキルの基本原則を理解する
- 練習ガイド — 最初のスキルを作成する