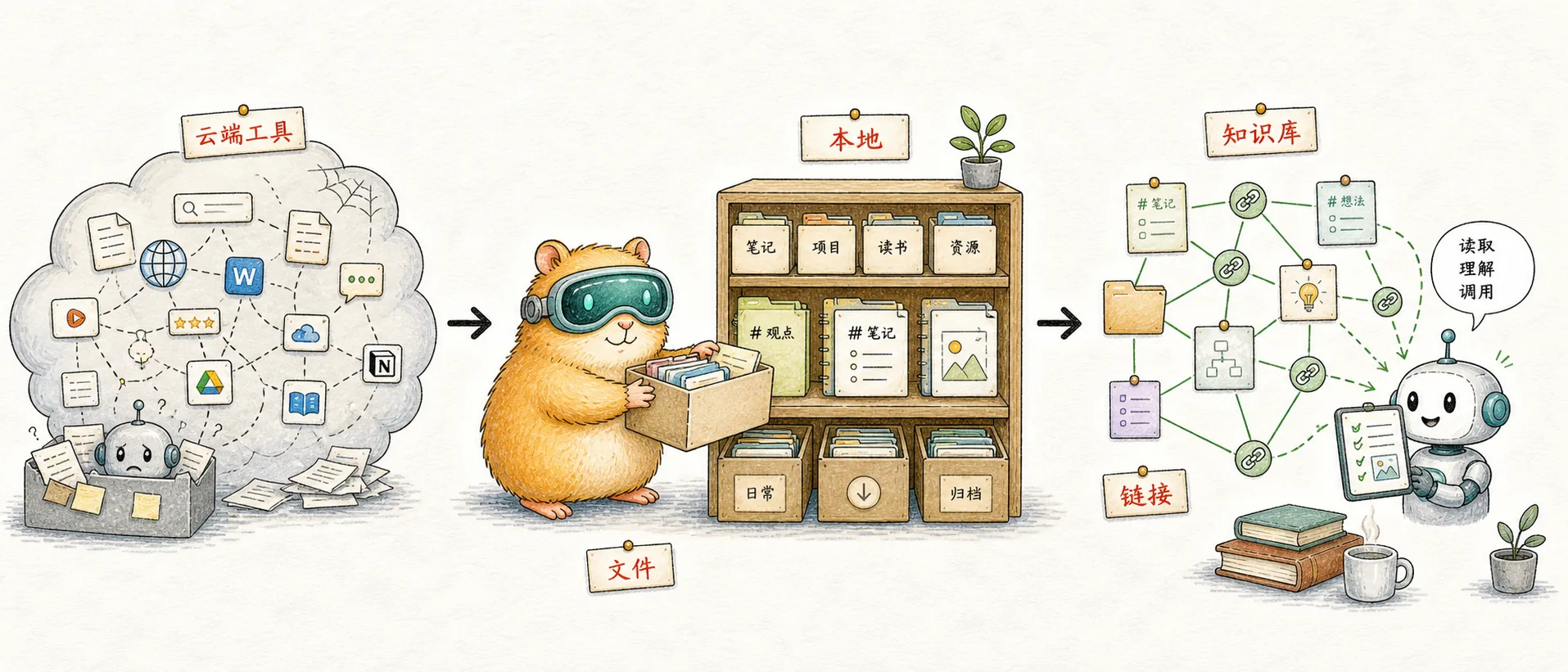
¿Cómo es el segundo cerebro en la era de la IA?
El wolai que he estado usando durante varios años no se ha actualizado durante medio año y Notion no puede conectarse con Claude, así que le pedí a Claude Code que me ayudara a construir un sistema de conocimiento de Obsidian desde cero. Después de medio mes, descubrí una cosa: lo que Notion quiere hacer es un sistema operativo y lo que quiero es un sistema de archivos. Estas dos cosas no serán el mismo producto en 2026.
En 2026, tus notas determinan cuánta IA puedes recurrir; ya no es solo una nota para ti, sino la memoria a largo plazo de la IA y la "capa de contexto" entre tú y el modelo. La forma de una nota determina si Claude a su lado puede leerla, escribirla, recuperarla y clasificarla, si puede soportar la densidad de docenas de colaboraciones de IA todos los días y si puede continuar acumulándose a lo largo de años y herramientas.
Pero los productos para tomar notas en manos de la mayoría de las personas no están diseñados para esta era: o el ritmo no puede seguir el ritmo, o los datos están encerrados en una caja negra de SaaS, o comienzan a venderle IA independiente. Por lo tanto, "Cómo debería verse el segundo cerebro en la era de la IA" es una pregunta que todo usuario intensivo de IA debe repensar.
La siguiente es la respuesta que le pedí a Claude Code que me ayudara a construir desde cero hace medio mes. Primero echemos un vistazo al efecto: después de funcionar durante medio mes, se ve así:
00-收件箱/ 待 triage 的临时落点
10-项目/ PARA:手头活跃的工作
20-领域/ PARA:长期关注的责任
30-资源/ PARA:参考资料库
40-原子笔记/ Zettelkasten:知识细胞(含 RAG/Agent 等主题子目录)
50-主题地图/ LYT/MOC:跨目录的主题入口
60-创作/ 创作管道:idea → outline → draft → ready → published
70-日志/ Periodic Notes:日记 / 周记 / 月记
90-归档/ 只读
99-系统/ CLAUDE.md / 模板 / 词典El esqueleto no es complicado, pero hay varios diseños menos obvios escondidos en su interior:
- Se unen tres conjuntos de metodologías: PARA gestiona el tiempo, LYT/MOC gestiona el espacio y Zettelkasten gestiona la granularidad atómica; estas tres cosas no entran en conflicto y están completas cuando se apilan juntas.
- Mínimo de construcción propia: 1 CLAUDE.md + 2 habilidades + 5 comandos de barra + 6 plantillas, el 95% restante usa complementos comunitarios
- Colaboración en capas de IA: la IA escribe la "capa de conocimiento" (hechos, recopilación) y los humanos escriben la "capa de juicio" (posición, contraejemplos). El campo
论证强度de cada nota atómica es el contrato de esta división del trabajo - Migración de estado = archivo mv: desde la inspiración de una oración hasta la publicación de la cuenta pública/Zhihu/Xiaohongshu, todo el proceso depende del controlador de movimiento de archivos entre los cinco subdirectorios de
60-创作/ - emerge de abajo hacia arriba: el conjunto de reglas anterior no me lo dio Claude el primer día de construcción - el espacio de nombres
#归类/, el campo论证强度y los límites de Auto Note Mover tardaron medio mes en crecer.
En cuanto a por qué cada nota se ve así, por qué wolai y Notion no me atraparon y cómo deberían verse las notas en la era de la IA, la historia debe comenzar desde la noche de mediados de abril de este año cuando estaba aturdido ante el botón de renovación.
El punto de partida de la historia: Esa noche de abril
Una noche a mediados de abril, abrí wolai (la versión doméstica de Notion que he usado durante varios años y guardé cientos de miles de palabras) para escribir un párrafo de mis pensamientos de ese día. El cursor parpadeó en la página en blanco unas cuantas veces. No me apresuré a escribir. En lugar de eso, accidentalmente llevé la barra lateral hasta el final y hojeé su registro de actualización:
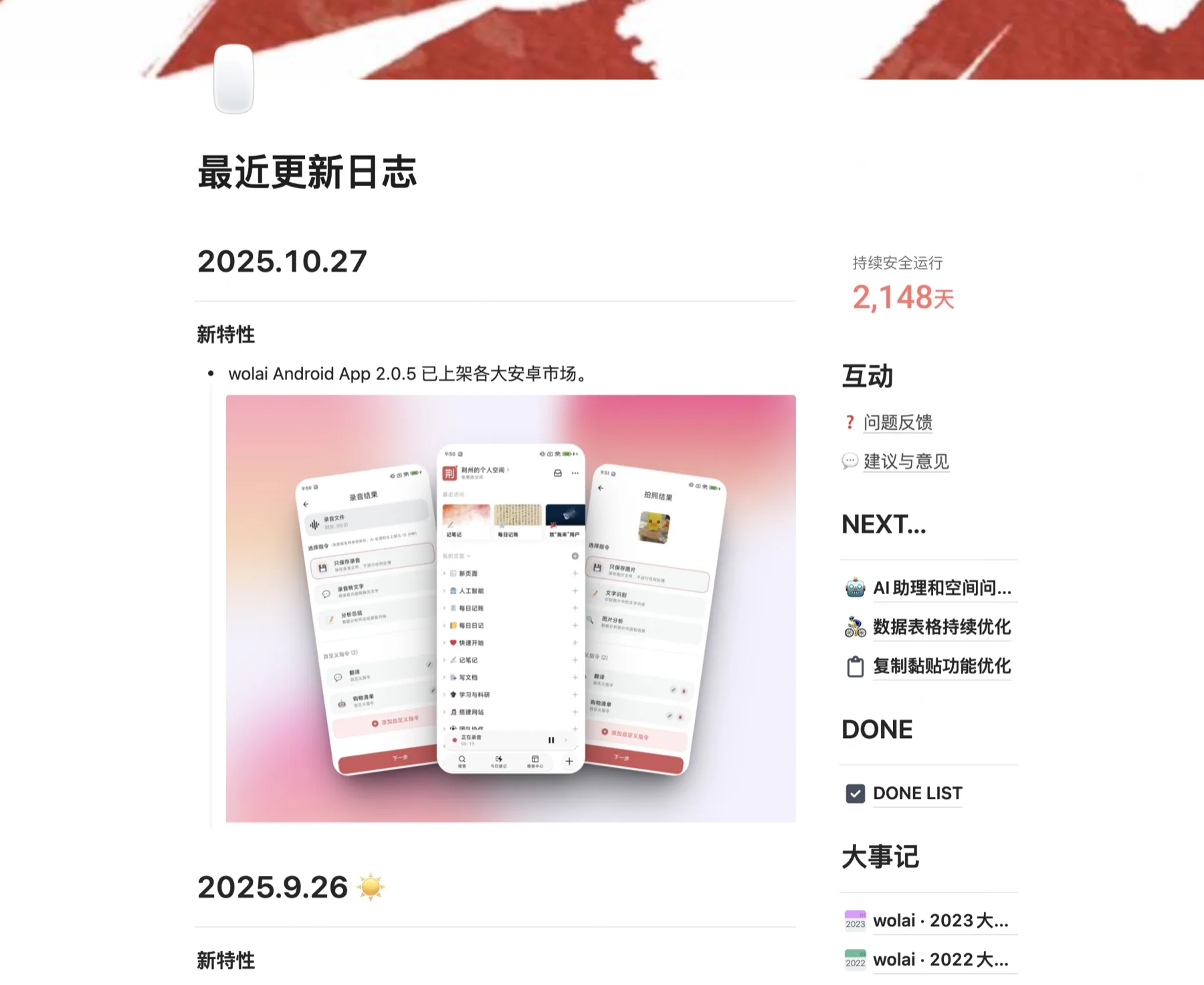
No es que esté muerto: "2148 días de operación segura continua" es cierto. Pero la última actualización se detuvo en octubre de 2025 y no se ha actualizado durante medio año; En el futuro, solo habrá unos pocos lanzamientos esporádicos durante más de un año después de mayo de 2024. Todo el producto desprende un olor a "en mantenimiento".
Casualmente hice clic en mi página de inicio personal y eché un vistazo——
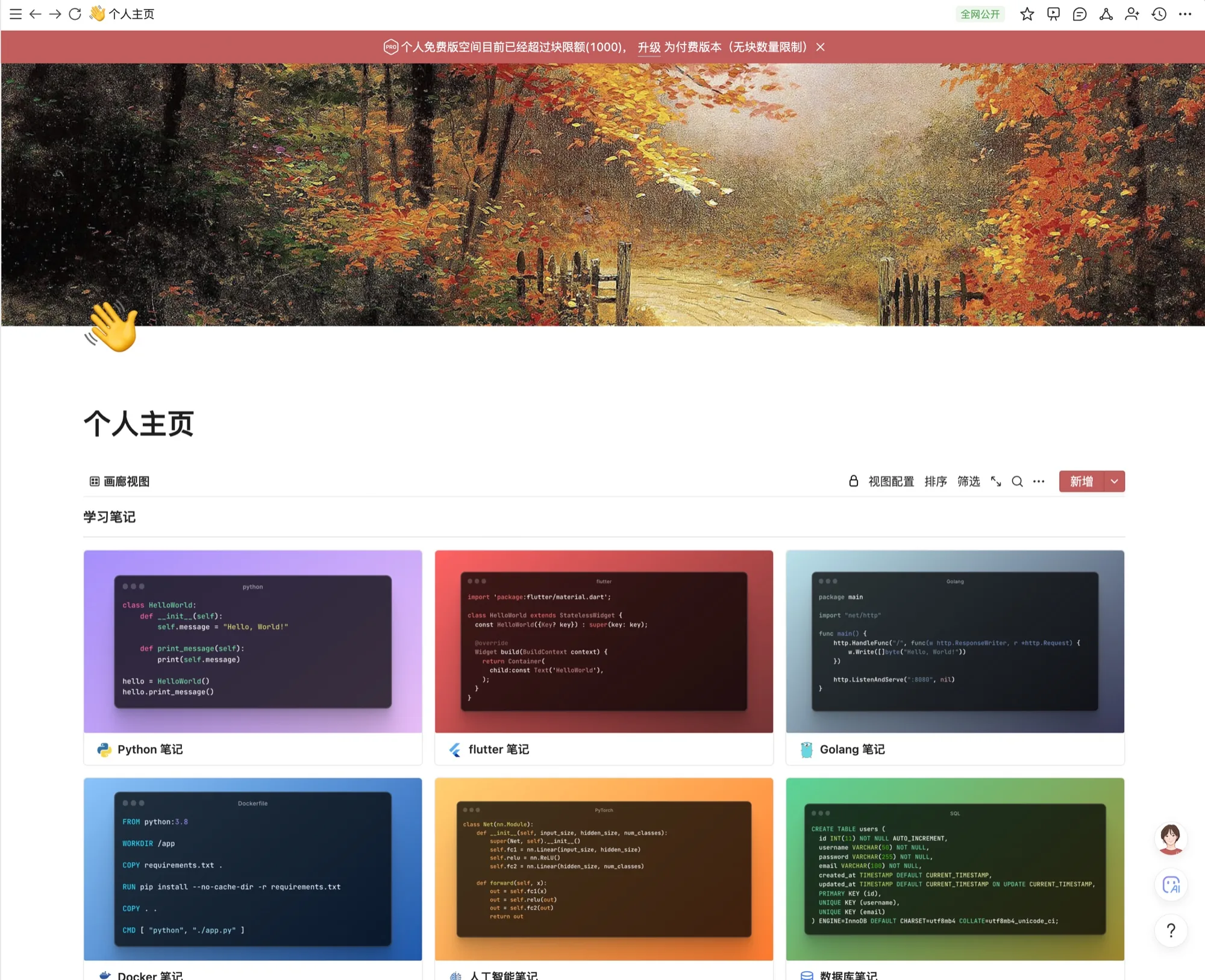
El mensaje rojo en la parte superior cuelga allí: "El espacio de la versión personal gratuita actualmente excede el límite de bloqueo (1000)". El tamaño de mis notas ya superó el límite de la versión gratuita, pero lo que es aún más llamativo es que esta página era originalmente "pública para toda la red"; podía enviar el enlace directamente a mis amigos hace medio año, pero ahora esta función más básica de "compartir una página pública" también está detrás de un muro de pago.
Las actualizaciones son cada vez más lentas y las funciones principales que originalmente eran gratuitas se están volviendo pagas: estas son dos señales de partida que aparecen una al lado de la otra.
Moví el mouse al botón de renovación y lo alejé.
No se trata de dinero. Pero esa noche no tomé una decisión inmediata: aparté el mouse, cerré el navegador, me di una ducha y dormí como de costumbre.
Lo que realmente me hizo considerar seriamente cambiar de herramientas fue un descubrimiento que surgió lentamente durante las siguientes semanas:
**Después de entrar en la era de la IA, recuerdo cada vez menos cosas. **
En el pasado, cuando encontraba detalles técnicos, pisaba obstáculos o encontraba una solución no obvia al escribir código, lo escribía y lo dejaba como referencia para mí la próxima vez. Muchas de mis cientos de miles de palabras de notas wolai se salvaron de esta manera.
Pero después de usar Claude Code, estas notas casi ya no se generan: la IA ha resuelto el problema y resolverá un problema similar la próxima vez. Ya no necesito "confiar en notas para recordar cómo solucionar errores". La naturaleza de lo que memoricé cambió silenciosamente: de "detalles tipo manual de operaciones" a pensamiento sistemático, razones para tomar decisiones y una o dos ideas en las que pensé después de leer un artículo.
Fue sólo en ese momento que me di cuenta: la naturaleza de los billetes había cambiado, entonces ¿debería elegir el portador de los billetes nuevamente? **
Decidí no renovar wolai cuando caducó y buscar una base para portátil que pudiera durar diez años. Y esta vez, le pedí a Claude que me ayudara a terminar esto. No planeo construir un sistema uno por uno yo solo, es demasiado agotador y ya sé que la IA puede hacer este tipo de cosas más rápido y mejor que yo.
Las dudas de esa noche y los descubrimientos realizados en esas dos semanas me llevaron a un camino inesperado: un período de medio mes en el que Claude Code me ayudó a construir un nuevo sistema desde cero y una serie de cuestiones en las que tuve que pensar nuevamente.
La noción no puede atraparme
Después de prepararse para mudarse de wolai, la siguiente parada que naturalmente me viene a la mente es Notion. La misma edición a nivel de bloque, la misma multiplataforma y la misma reputación entre los programadores chinos. Registré un espacio de trabajo y me preparé para moverlo.
El primer muro cayó rápidamente. El 70% de mis notas actuales están escritas por Claude: dejo que me ayude a organizar sistemáticamente un tema, que transcriba un vídeo en notas estructuradas, que comprima un artículo en algunas ideas de nivel atómico. Este tipo de flujo de trabajo requiere que la IA pueda escribir cosas en notas con tanta naturalidad como escribir documentos. Notion tiene MCP, que recogí con gran anticipación.
Después de recibirlo, golpeé la pared y llegué al tercer piso.
**Nivel 1: Lento y siempre tener que reautorizar. **
Notion MCP no lee ni escribe archivos directamente, sino que empaqueta cada operación en una solicitud API y la envía al servidor de Notion, y luego espera a que llegue la respuesta. Cuando Claude escribe una nota con una estructura un poco más compleja, debe dividirse en una docena de llamadas de agregado de bloques, cada una de las cuales requiere un viaje de ida y vuelta en la red; casi todo el tiempo para implementar la nota completa se pasa esperando al servidor. Lo que impacienta aún más a la gente es que no se trata de una autorización única para uso de por vida. De vez en cuando, aparecerá un cuadro de confirmación como este, en el que tendré que hacer clic manualmente antes de poder continuar:

Una tarea para que Claude resuelva un tema se puede dividir en 3 o 4 secciones, y yo tengo que mirar la pantalla y decir "Está bien, pase" para cada sección. Además, el viaje de ida y vuelta de la API anterior ya es lento y todo el flujo de trabajo se ve arrastrado por estas dos capas de fricción. Obsidian no tiene estas dos capas en absoluto: archivos locales, Claude directamente Write un archivo .md, disco local IO, nivel de milisegundos, sin intermediarios para asentir. Puedo pedirle a Claude que cambie una docena de archivos cada día, y esta brecha se magnifica infinitamente.
**Nivel 2: isla de suscripción a IA. **
El foco de la evolución de Notion en los últimos dos años es obviamente la IA: la escritura de IA incorporada, las preguntas y respuestas y las capacidades similares a las de los agentes se suceden una tras otra. Abra notion.com y verá de un vistazo:
Pero todo esto me resulta redundante. Mi suscripción principal a IA ya está con Claude: el paquete de 200 dólares de Claude Code está lleno todos los días y las capacidades, el contexto y la memoria son suficientes. Lo que quiero es ampliar las capacidades existentes de Claude a la toma de notas, en lugar de pagar por una IA independiente para el software de toma de notas y adaptarme a un nuevo estilo de agente. El flujo de trabajo debería ser controlable por mí y no debería quedar atrapado por un determinado SaaS en su ecosistema de IA.
**Nivel 3: la edición a nivel de bloque está obsoleta. **
Notion se enorgullece de su "edición a nivel de bloque": se puede arrastrar y soltar, incrustar una base de datos bidireccional, y cada párrafo de texto se puede tratar como un ladrillo Lego reorganizable; este paradigma avanza en la era de "la gente escribe y lee". Pero cuando mis notas las escribe principalmente IA, las leo yo y la IA me ayuda a recuperarlas y revisarlas, el bloque se convierte en un grillete. Las manifestaciones específicas son: Notion usa internamente JSON de bloque y la conversión de rebajas a bloques está incompleta. Las listas anidadas, las leyendas y las etiquetas de lenguaje de bloques de código se deforman después de su implementación: la IA es incómoda de escribir, tengo dificultades para leer y la búsqueda no es transparente.
Pero lo que realmente me hizo decidir apagarlo fue lo más importante detrás de la imagen de arriba: Notion en sí ya no es el "segundo cerebro" que solía ser. Está evolucionando hacia plataforma de trabajo de IA empresarial, que puede ser adecuada para el tipo de clientes Forbes Cloud 100, pero está demasiado lejos de mis objetivos:
**Notion quiere hacer SO, lo que quiero es sistema de archivos. ** **Estas dos cosas no son el mismo producto en 2026. **
No me gustó la obsidiana durante dos años
De hecho, instalé Obsidian durante mucho tiempo. Se instaló hace dos años y el ícono siempre está en el Dock:
Pero en realidad nunca hice clic en él ni una sola vez; la razón es que "no tiene suficiente nivel de bloque" y los archivos son simplemente rebajas, lo cual es demasiado "original".
No fue hasta este momento que me di cuenta: ** Todas las cosas que antes no me gustaban resultaron ser las ventajas de tomar notas en la era de la IA. **
The best file format for the future is the one you can read without the app that created it.
Kepano es el director ejecutivo de Obsidian. En File over app, habló de una verdad que es tan simple que casi resulta contraintuitiva: el software desaparecerá, pero los archivos no serán destruidos. Notion puede morir y Obsidian puede morir, pero un montón de archivos .md en su disco duro no se podrán abrir porque cualquier aplicación muera. Las notas verdaderamente reutilizables en la era de la IA no son la estructura interna de un SaaS, sino texto sin formato + una estructura de directorios que puedes controlar.
Esta es la razón fundamental por la que me retiré de wolai y Notion: soberanía de datos.
Pero claro, la obsidiana por sí sola no es suficiente. Obsidian es un editor de rebajas vacío. No le dirá "cómo se debe organizar el conocimiento". Así que tomé una decisión que me alegró mucho más tarde: subcontratar todo el asunto de "cómo organizar" a Claude.
Una frase de exigencia, un plan.
Abrí Claude Code y escribí un párrafo; luego, este párrafo se escribió intacto en el contexto del plan de construcción:
Ahora quiero construir mi propio sistema de Obsidiana. Eche un vistazo a los proyectos relacionados y vea si hay almacenes relacionados en github. Es decir, quiero tener un sistema y luego puedo usar AI para administrar todo mi sistema.
No dije cómo se ve el directorio, qué complementos se necesitan ni la metodología. Solo dije tres cosas: Quiero un sistema, preferiblemente que no sea desde cero, preferiblemente que permita que la IA participe sin problemas.
Unas horas más tarde, Claude me entregó un documento de propuesta. Leí y aprobé. En esencia hay cinco principios, tan simples que los cité una y otra vez:
- Puede instalar complementos sin escribir código: diario, plantilla, doble enlace, recorte, clasificación automática, la comunidad tiene complementos maduros, todos se pueden instalar directamente
- Si puedes clonar, no empieces desde cero: una muestra de referencia que utiliza kepano/kepano-obsidian (la bóveda personal pública del CEO de Obsidian) como esqueleto del directorio.
- MCP en lugar de habilidad autoescrita: use el
MarkusPfundstein/mcp-obsidianya preparado para conectarse a Claude Code, en lugar de recrear la capacidad básica de "leer y escribir notas". - Reutilizar la cadena de habilidades yux-* existente - Ya tengo el manuscrito terminado pulido + cadena de habilidades de publicación multiplataforma (cuenta oficial/Zhihu/Xiaohongshu). El nuevo sistema solo acepta la primera mitad de "Inspiración → Borrador", y la segunda mitad se entrega directamente
- La construcción propia se limita a "juicio semántico y capa de adhesión que no se pueden realizar mediante soluciones listas para usar" - Especificación CLAUDE.md, palabra de aviso de clasificación activada por IA, pegamento de conexión
Al final, la carga de trabajo autoconstruida se comprimió a: 1 copia de CLAUDE.md + 2 habilidades + 5 comandos de barra diagonal + 6 plantillas de plantilla. Un 60% menos que la primera versión de la solución que se me ocurrió.
Cuando miré este plan, mi primera reacción fue: "Esta IA sabe cómo controlarse mejor que yo".
La mayoría de las personas no logran construir una bóveda, no porque no trabajen lo suficiente, sino porque quieren escribir ellas mismas cada línea de reglas. Como resultado, después de tres meses, vi que el montón de ganchos y habilidades que escribí no se podía mantener, y todo el sistema quedó abandonado tan pronto como la novedad desapareció. Claude me dijo tan pronto como apareció: el 95% de las capacidades se subcontratan al ecosistema, y el 5% que solo puede resolverse con IA se puede resolver mediante la autoconstrucción: juicio a nivel semántico. Este incidente en sí es uno de los mayores beneficios de este experimento.
La mirada de Claude
El producto principal que me dio Claude fue una copia de CLAUDE.md en el directorio raíz de la bóveda; este documento es la "constitución" de todo el sistema. Define el lenguaje de la bóveda, la metodología, los límites del escenario dual, los roles de IA, las reglas estrictas del directorio, el frontmatter, el espacio de nombres de etiquetas... Cada vez que se abre una nueva sesión de Claude Code, puede asumir inmediatamente la colaboración de toda la bóveda después de leer este documento. Comienza así:

Ya has visto el esqueleto al principio. No lo volveré a publicar aquí; lo que quiero decir no es el catálogo en sí, sino cómo encajan las tres metodologías detrás del esqueleto y los dos límites que determinan si se puede utilizar.
Detrás del esqueleto hay una mezcla de tres conjuntos de metodologías, cada una de las cuales aborda una dimensión:
| Metodología | Fuente | Manifestación en bóveda | Qué resolver |
|---|---|---|---|
| PARA | Tiago Forte "Construyendo un segundo cerebro" | 10/20/30/90 Arriba | "¿Qué estoy haciendo ahora?" - Dimensión del Tiempo |
| LYT/MOC | Nick Milo Vinculando tu pensamiento | 50-主题地图/ | "Cómo vincular lateralmente" - Dimensión espacial |
| Zettelkasten | Sönke Ahrens "Cómo tomar notas inteligentes" | 40-原子笔记/ | "Células de conocimiento" - Granularidad atómica |
PARA es responsable de "cómo dividir las cosas que tengo a mano según su ejecutabilidad", LYT es responsable de "cómo las ideas se llaman entre sí" y Zettelkasten es responsable de "cómo se divide cada idea en fragmentos independientes". Las tres cosas no entran en conflicto y están completas cuando se combinan: la mayoría de las personas solo aprenden una y el resultado es que el sistema siempre se queda atrás.
Para que no sólo "escuches mi narración", he seleccionado la frase más aguda de cada uno de los autores de estas tres metodologías:
PARA de Tiago Forte, el juicio central en el texto original sobre "por qué no clasificar por tema" es:
Instead of organizing information according to broad subjects like in school, I advise you to organize it according to the projects and goals you are committed to right now.
Es por eso que mis 10-项目 / 20-领域 / 30-资源 / 90-归档 son de nivel superior: son estados de acción, no temas. La categoría de tema "AI/Escritura/Productos" es solo una etiqueta #主题/ secundaria.
Sönke Ahrens habla sobre Zettelkasten en Cómo tomar notas inteligentes. La frase más citada es:
A note is only as valuable as the network it's embedded in.
El valor de una nota es igual al valor de la red en la que está incrustada.
Una nota atómica por sí sola no tiene sentido; su valor proviene de la densidad de conexiones entre ella y otras notas. Es por eso que en 40-原子笔记/ fomento el encadenamiento doble denso: con cada enlace agregado, los activos de toda la bóveda aumentan de valor.
LYT de Nick Milo implementó lo anterior de una manera más ingenieril: se opuso a la "clasificación perfecta" codificada y abogó por el uso de MOC (Mapa de contenido) como una página de directorio viva para permitir que la estructura crezca durante el uso. Esta es exactamente la lógica subyacente de 50-主题地图/: MOC no reemplaza las carpetas, pero le permite ver todas las notas dispersas relacionadas desde la entrada de un tema, más flexibles que las carpetas y más estructuradas que las etiquetas.
Lo que realmente determina si este sistema se puede utilizar o no son dos límites que no se pueden confundir:
**Artículo 1: 40-原子笔记/ ≠ 60-创作/素材库/. ** El primero es un activo intelectual permanente: una nota atómica = una idea o conocimiento independiente al que se puede hacer referencia en cualquier lugar y se espera que esté vinculado una y otra vez. Estos últimos son materiales de una sola vez: frases de oro, casos y fragmentos de citas utilizados en un manuscrito de cuenta pública específico, y su ciclo de vida es igual al de ese manuscrito. Si se confunde este límite, tarde o temprano la base de conocimientos se verá inundada de contenido desechable.
**Artículo 2: Base de conocimiento ≠ creación. ** 10/20/30/40/50/70 es la capa de conocimiento y 60-创作/ es la capa creativa. Las dos capas están conectadas por una incrustación unidireccional: los manuscritos pueden usar ![[原子笔记#章节]] para citar el contenido de Atomic Notes, pero Atomic Notes no se vincula a los manuscritos. Esta válvula unidireccional protege la pureza del conocimiento, por lo que el hecho de que un blog se vuelva popular o no no afecta la estabilidad de la nota atómica que hay detrás de él.
El sistema de etiquetas se divide estrictamente en cuatro categorías según el espacio de nombres:
#类型/原子— Tipo de estructura, la IA escribe automáticamente según el campo de front-matter#主题/ai— Clasificación de temas, escrito manualmente#状态/待读— Estado temporal, eliminar después de su uso#归类/RAG— Clasificación de subdirectorios (solo para40-原子笔记/), AI escribe automáticamente por tema
El último espacio de nombres #归类/ no estaba disponible el primer día de construcción; dos semanas después descubrí que Atomic Notes tenía más directorios moleculares, pero no quería que Auto Note Mover reescribiera toda la lógica de clasificación, así que abrí un espacio de nombres separado específicamente para la "clasificación secundaria de Atomic Notes".
Hablaré de este detalle más adelante; fue la experiencia más sorprendente para mí en este experimento.
¿Cómo lo uso todos los días?
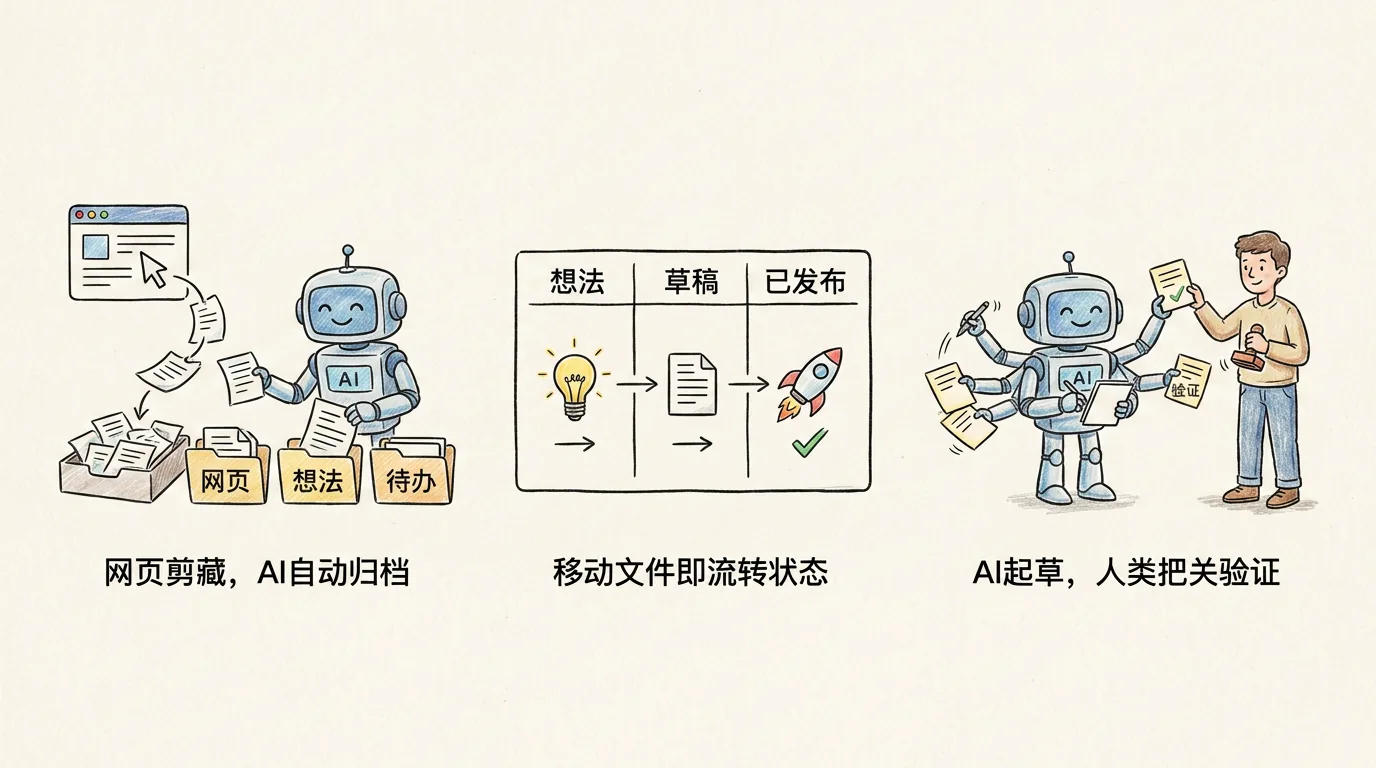
Devuelve el navegador con un clic
Este proceso es ahora memoria muscular. Chrome tiene instalado el Obsidian Web Clipper oficial, y cuando veas un buen artículo, haz clic en él; así es como vi el artículo de Anthropic "Construyendo agentes efectivos" la semana pasada: el texto completo + la URL de origen + mi resaltado, junto con el frontmatter completado automáticamente, cayó a 00-收件箱/.
Regrese a la terminal y ejecute /inbox:
$ claude
> /inboxDespués de que Claude leyó el artículo, me respondió: "Este contenido es el resumen oficial de Anthropic del patrón de diseño del agente. Está altamente estructurado y no es una opinión personal. Se considera un tipo de 'recorte de artículo' y se recomienda clasificarlo en 30-资源/文章剪藏/. ¿Necesita que divida de 3 a 5 notas atómicas en 40-原子笔记/Agent/ al mismo tiempo? "
Le dije: "Primero devuélvalo al portapapeles y lo leeré yo mismo en Atomic Notes antes de desmantelarlo". - Cree el archivo mv, agregue el frontmatter 类型: 文章剪藏 y agregue la etiqueta #类型/文章剪藏 #主题/ai, y estará listo en 30 segundos. **Solo hice dos acciones en todo el proceso: presionar el botón Clipper y escribir una oración. **
Este proceso todavía era manual hace medio mes: descargar → cambiar nombre → decidir qué carpeta colocar → escribir frontmatter; un artículo debería tomar al menos 5 minutos. Si encuentra algo que no sabe dónde poner, se retrasará una semana. Ahora tengo diez artículos acumulados en mi bandeja de entrada y puedo terminarlos en 5 minutos.
Una frase de inspiración conduce al manuscrito terminado.
Este es el conducto más largo de todo mi sistema. Desde una frase de inspiración hasta la finalización de la publicación en tres plataformas (cuentas oficiales, Zhihu y Xiaohongshu), todo está impulsado por el movimiento de archivos:
/idea 谈谈 Claude Code Skill 比 MCP 灵活的原因
↓ 60-创作/01-灵感池/20260502-...md(Templater 自动写入 frontmatter)
/draft <灵感文件>
↓ Claude 从 40-原子笔记/ 拉相关原子,从素材库拉历史素材,组织大纲+初稿
↓ 落到 60-创作/03-初稿/
/publish
↓ yux-blog-writer 润色 → yux-publish-* 多平台发布
↓ 文件 mv 到 05-已发布/2026/05/,frontmatter 回写各平台 URLEste pipeline tiene un diseño que me gusta particularmente: la migración de estado es un archivo mv. El directorio en el que se encuentra el archivo es su estado. El complemento Kanban genera un tablero Kanban de cinco columnas basado directamente en los cinco subdirectorios de 60-创作/, con código cero: arrastra la tarjeta y el archivo se mueve. Tan simple que casi no parece un flujo de trabajo.
AI escribe, yo solo leo
Esta escena es el cambio real del modelo de "escritura humana y lectura humana" de cientos de miles de palabras en wolai al modelo de "escritura y lectura humana con IA" en la era de la IA.
Le pido a Claude que me ayude a organizar sistemáticamente un tema, como RAG. Se escribirá directamente debajo de 40-原子笔记/RAG/. Cada entrada es una nota atómica independiente, con etiquetas #类型/原子 #归类/RAG #主题/ai y el texto inicial correcto. Después de escribirlo, me dijo: "He escrito 12 elementos en este lote. Tómese el tiempo para leerlos. He marcado la solidez del argumento como 'para ser verificado'. Lo cambiaré a 'verificado' después de que lo haya leído nuevamente".
Todo lo que hago es: leer, juzgar y cambiar "para ser verificado" por "verificado" o "especulado". Una parte considerable de mis cientos de miles de palabras de notas wolai son en realidad este tipo de trabajo de clasificación: debería haber sido realizado por IA. Ahora me atrevo a entregar el 70% de mis escritos a AI porque mi rol ha cambiado.
Consistente entre sesiones
El momento que más me hizo sentir que este sistema "cobró vida" fue una sesión de Claude Code recién abierta; no le di ninguna indicación y simplemente le agregué un fragmento de texto: "Ayúdame a pegarlo en el lugar correcto".
Leyó CLAUDE.md, analizó la semántica de mi texto y me dijo: "Este párrafo no es como una nota atómica (la conclusión no es lo suficientemente independiente), sino más bien como material creativo: ¿qué manuscrito fue preparado para usted?"
**Me está pidiendo que vuelva usando mis reglas. **
Este es un subproducto que no esperaba el primer día de configuración: cuando escribes las reglas con suficiente claridad, la IA te obligará a pensar con claridad sobre lo que estás haciendo en el proceso de ejecutar las reglas.
Lo que no entendí hasta medio mes después.
** El error más fácil al construir un sistema de conocimiento en la era de la IA es dejar que la IA te ayude a diseñar una "clasificación perfecta" y luego no podrás seguir el ritmo de los ajustes preestablecidos. **
El primer día de instalación, la estructura del directorio que me dio Claude era tan clara como la hoja de respuestas de un examen. Pero lo que realmente se puede utilizar el decimoquinto día es la ordenada hoja de respuestas más una serie de correcciones de tipo "sólo lo sabrás después de usarlo", como por ejemplo:
- A medida que se acumulan más y más notas atómicas, el directorio raíz se vuelve confuso → Agregue
#归类/espacio de nombres y subdirectorio de temas - Las notas escritas por AI se mezclan con las que pensé y escribí, lo que hace imposible distinguirlas → Agregue el campo
论证强度frontmatter para capas
Estas reglas no surgieron del primer día de trabajo previo de Claude. Crecieron después de medio mes de trabajar y pasar por algunos obstáculos.
Si mi plan para el primer día hubiera copiado a kepano, el #归类/ de hoy nunca habría aparecido, porque esa no era la necesidad de kepano. **El sistema verdaderamente utilizable es algo que se utiliza, no se imagina. **
Repensar las notas en la era de la IA

En este punto, puedo tomar tres decisiones finales, dicho de la forma más sencilla posible:
**Primera frase: El lado opuesto de la nota ha cambiado de mí a AI. **
Solía escribir notas para mi futuro yo, así que cuanto más recordara y más bellamente organizadas estuvieran, mejor. Pero ahora paso la mayor parte de mi tiempo con la IA ayudándome a escribir, leer y buscar por mí. La verdadera cara de la nota ha cambiado: ahora es la "memoria a largo plazo" a la que la IA que te rodea quiere llamar en cualquier momento, y tú simplemente la lees de pasada.
Este asunto determina directamente los criterios de selección de las herramientas para tomar notas. La razón fundamental por la que me retiro de wolai y Notion no es que dejen de actualizarse o se congelen, sino que la IA de su contenido no se puede usar: la IA en una caja negra de SaaS no se puede llamar a su lado en ningún momento, y no importa cuán hermosa sea una computadora portátil, no se puede guardar. ** Entonces, cuando evalúo las herramientas para tomar notas ahora, la primera pregunta es "¿Puede la IA leer y escribir mi contenido de forma natural?" Úsalo si puedes, ríndete si no puedes. **
**Segunda frase: la IA escribe conocimiento y los humanos escriben juicios. **
La IA puede escribir hechos, organización y principios técnicos de forma más rápida y precisa que yo; sería una pérdida de tiempo para dos personas escribirlos a mano. Pero la posición, la evaluación y los contraejemplos los debe escribir usted mismo. No es porque la IA no pueda escribir, es porque una vez que subcontratas esta parte, poco a poco irás perdiendo la confianza en tu propio juicio. El muy elogiado artículo de HN de marzo de este año planteaba este asunto con la mayor dureza:
The risk isn't that AI replaces our thinking. It's that we lose confidence in our own judgments — even in domains where AI cannot meaningfully contribute.
Mi contramedida es marcar cada nota como "por verificar / verificar / especular"; la marca completa escrita por AI es "por verificar" y, una vez que termine de leerla, se cambiará a "verificada" o "especulada". **Quien presione este botón debo ser yo. **
**La tercera frase: El sistema se construye usándolo, no inventándolo. **
Esta frase se ha explicado detalladamente en la sección anterior: no permita que la IA le dibuje un índice perfecto el primer día. Después de dos semanas de funcionamiento, surgirán naturalmente algunas reglas que solo usted necesita.
Esto es solo el comienzo
Este sistema solo lleva medio mes configurado y está lejos de estar finalizado, pero es suficiente para usarlo y es suficiente para escribir esta publicación de blog.
Si también desea crear su propio conjunto: No copie mi catálogo, copie el método. Lanza esta publicación de blog en Claude Code y cuéntala:
参考这篇博文里的体系,给我搭一套属于我自己的。
不要直接抄目录,先问我 10 个问题,比如:
- 我每天会读多少新内容?是看视频、读论文,还是逛博客?
- 我有没有写作或发布的需求?发到哪里?
- 我希望 AI 在我的笔记里扮演什么角色——
只读、整理、还是直接帮我写?
- 有没有哪些笔记是只服务一次的素材,哪些是要长期沉淀的资产?
- 我的旧笔记在哪里?是想全迁过来还是慢慢消化?
- ……剩下的你来问。
把我的回答记到 CLAUDE.md 的 Context 段里,然后再给方案。Te dará un sistema diferente al mío, pero que te pertenece.
En cuanto a los cientos de miles de palabras y notas de wolai, no las transferí todas; dejé que la IA las digiera lentamente. Esta es la segunda fase del sistema. Si un día ves que este blog publica un artículo "Le pedí a AI que me leyera cientos de miles de palabras de notas antiguas", significa que el sistema ha crecido.
En ese momento ya no sería sólo una bóveda de obsidiana: sería un segundo cerebro verdaderamente mío que duraría diez años.
Lectura adicional
Si desea profundizar en las metodologías y herramientas citadas en este artículo, aquí tiene las siguientes en orden de importancia:
- File over app — kepano Un ensayo de mil palabras que explica detalladamente "Por qué los datos deberían ser archivos". Léelo en 5 minutos y úsalo durante diez años.
- Cómo uso Obsidian — kepano ¿Cómo es su propia bóveda? Una muestra representativa de la toma de notas de abajo hacia arriba.
- El método PARA + Presentación del segundo cerebro de la IA — Teoría PARA de Forte + extensión a la era de la IA
- Cómo tomar notas inteligentes (Ahrens) + Vincular tu pensamiento (Milo) — La metodología original de Zettelkasten y LYT
- Publicación en el foro Zettelkasten con IA aumentada — Una voz representativa que se opone a "escribir tarjetas con IA directamente"
- MarkusPfundstein/mcp-obsidian — Servidor MCP que permite a Claude Code leer y escribir toda la bóveda de forma natural
Artículos relacionados
Publicar en la cuenta oficial de WeChat con un solo comando usando Claude Skills
Guía paso a paso para usar el Skill baoyu-post-to-wechat y automatizar la publicación desde Markdown hacia la cuenta oficial de WeChat, cubriendo instalación, configuración y todo el flujo de publicación
De Eclipse a Zed: La evolución de editores de un desarrollador
Del desarrollo backend al full-stack, de VS Code con más de 200 plugins a un flujo de trabajo centrado en la terminal — cómo mis elecciones de editor evolucionaron con la era de la IA
Mis mejores prácticas con Claude Code
Comparto mis experiencias usando Claude Code para programar: 10 técnicas clave, guía completa de comandos slash y configuración de comandos personalizados para mejorar tu eficiencia en programación con AI