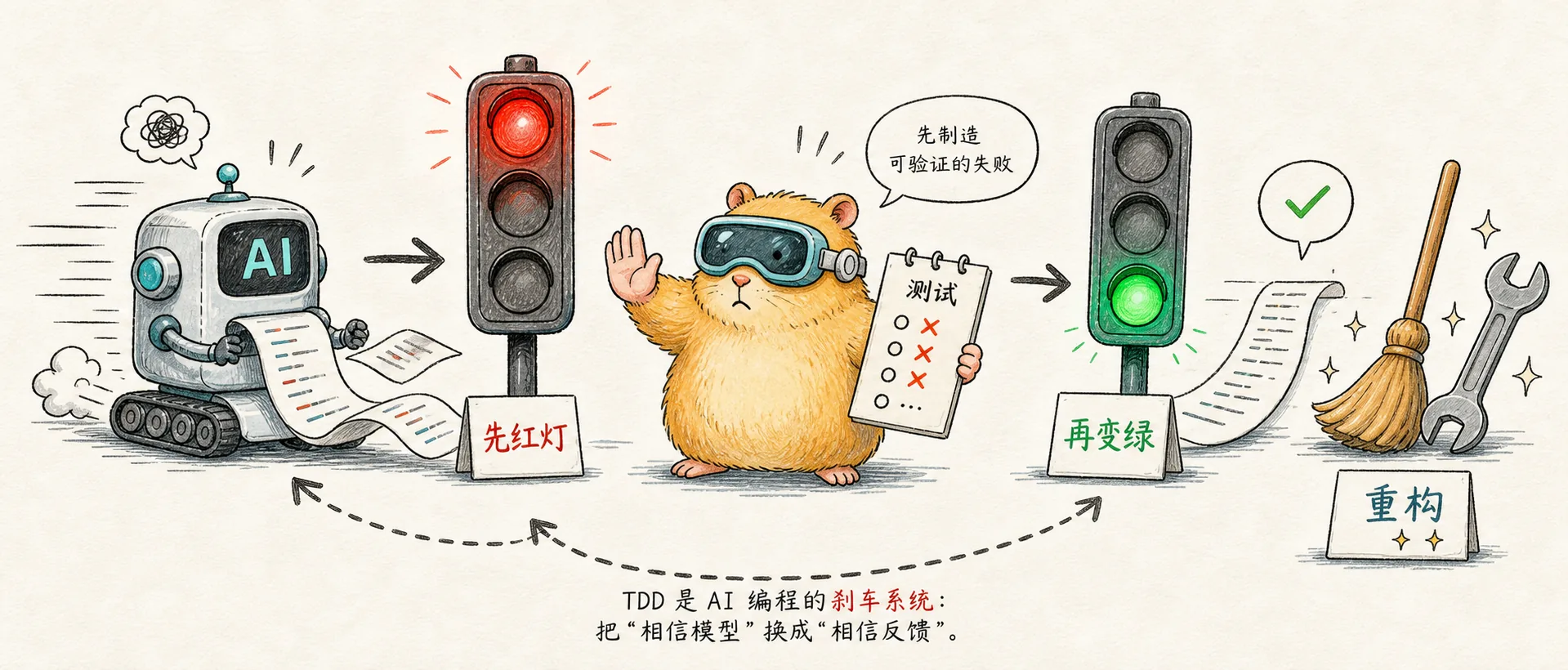
AI 時代の TDD: モデルに最初に赤信号を当てさせます
AI プログラミングに TDD が必要なのはなぜですか?重要なのは、正式に「最初にテストを書く」ことではなく、実装が赤から緑に変わる前に検証可能な障害を作成することです。
まず結論から話しましょう
AI がコードを作成した後、TDD は時代遅れではありませんが、その立場は変わりました。
以前、TDD について話すとき、最初にテストを作成し、次に実装を作成し、小さなステップでリファクタリングするというプログラマーの自制心についてよく話していました。 AI プログラミングに関して言えば、ブレーキ システムに似ています。なぜなら、モデルが最も得意とすることは、同時に最も危険なことでもあるからです。それは、完全に見える大きなコードを素早く書くことができるからです。
関数の実装を依頼すると、次のような結果が得られます。
- 実装ファイル
- 一連のテスト
- 説明
- 「完了」という言葉
問題は、「完全に見える」ということはエンジニアリングの意味では行われないということです。工学的な意味で完了するには、少なくとも次のように答えてください。
この動作は、明示的に失敗したテストによって定義されているのでしょうか? この失敗は実装によって緑色になったのでしょうか? 緑色になった後、動作を変えずにコードを整理しましたか?
AI時代にTDDが再び話題になっているのはこのためだ。
それはプロセスを高度に見せることではなく、「モデルへの信頼」を「フィードバックへの信頼」に置き換えることです。
1. よくある誤解: TDD は「最初にテストを書く」ものではありません
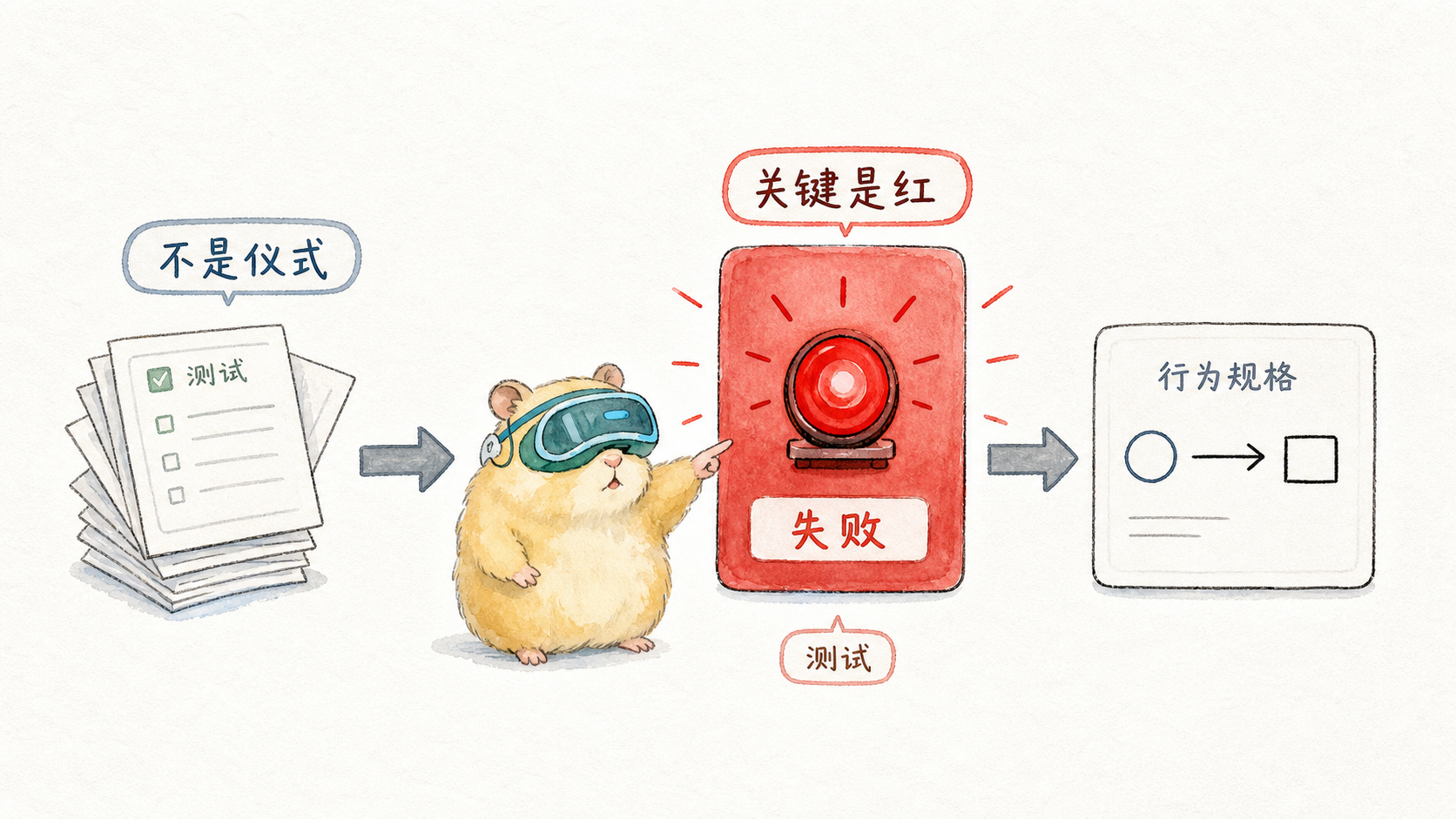
多くの人が TDD を嫌うのは、TDD を儀式だと理解しているからです。
先写测试。
再写代码。
最后跑一下。これは確かに退屈で、形式主義になってしまいがちです。
本当に役立つ TDD は、「テスト ファイルが早く現れる」ことではなく、「障害が十分早く現れる」ことです。
重要なのはテストではなく赤です
TDD の最初のステップは、TEST ではなく RED と呼ばれます。
赤は、システムが明らかに失敗するように最初にテストを作成することを意味します。これが失敗するには、次の 3 つのことが当てはまる必要があります。
- 失敗します。
- ターゲットの動作が存在しないため、失敗します。
- 期待通りに失敗する。
最初に赤を見なければ、その後に続く緑は意味がありません。
たとえば、slugify("Hello World") -> "hello-world" を実装するとします。貴重な RED は、「テスト ファイルを作成した」ことではなく、次のことです。
Test: tests/test_slugify.py
Command: pytest tests/test_slugify.py -q
Failure: NameError: name 'slugify' is not defined
Reason: 目标函数还不存在,符合预期このとき、テストが仕様になります。次のステップに進むには、この動作を true にするだけで済みます。
まずグリーンにしてからテストを補い、通常はストーリーを作り上げます
AI が逆の方向に進むことは簡単です。最初に実装を記述し、後でテストを追加します。
これはスムーズな体験です。コードが実行され、テストが実施されたのを見ると、心の中で「もうすぐ」と感じるでしょう。しかし、これには致命的な問題があります。テストは現在の実装を遡及的に実装する可能性が高いのです。
「要件がどうあるべきか」を問うのではなく、「現在のコードを簡単に通過できるようにどのように記述するか」を問うのです。
AI がテストを作成する際に次のような匂いがするのはこのためです。
- アサーションが現在の実装に固有すぎる
- モックが多すぎて、実際の境界が測定されていません。
- ハッピーパスのみをテストします
- 既存のコードを通過させるには、アサーションを非常に広範囲に作成します
- 古いコードがもともと間違っていたことを証明できるテストはありません
TDD ではその逆が必要です。まず要件を失敗させてから、コードが要件に追いつくようにします。
2. AI 時代に TDD がより必要とされる理由
AI プログラミングの核心的な矛盾は、「コードの記述が遅い」ことではなく、「フィードバックが遅い」ことです。
TDD を使用しない場合、通常は次のように作業します。
描述需求 -> AI 写一堆代码 -> 人肉看 diff -> 跑一下 -> 发现问题 -> 回头修最後まで疑問は山積するだろう。それが間違っていると気づく頃には、次の 3 つのカテゴリのものが混在している可能性があります。
- 要件の誤解
- 実装パスが間違っています
- リファクタリングにより古い動作が破壊される
TDD の役割は、この長いチェーンを短縮することです。
モデルに決定可能な目標を与えます
「エレガントに書く」ことが目的ではありません。
「ユーザーのログインステータスの有効期限が切れた後、自動的にログインページに戻る」という表現は十分に具体的ではありません。
より良い目標は次のとおりです。
当 access token 过期时:
1. 请求返回 401。
2. 客户端清理本地 session。
3. 用户被重定向到 /login。
4. 原始目标地址被保存在 redirect 参数里。さらに一歩進んで、そのうちの 1 つを失敗したテストに変えます。
given expired session
when user opens /settings
then app redirects to /login?redirect=/settings現時点では、AI は「ログイン状態の期限切れをどのように処理するか」を推測するのではなく、明確な動作を完了します。
大きなタスクを小さな閉じたループに分割します
AI が制御を失いやすいのは、すべてを一度に実行することです。
ログイン、権限、リフレッシュ トークン、エラー プロンプト、ルート ジャンプを一度に実装すると、最終的には大きな差が得られます。うまくいくかもしれないが、レビューコストは高い。ビジネス、ステータス、ルーティング、境界、テスト、リファクタリングを同時に判断する必要があります。
TDD のリズムは次のようになります。
一个行为 -> 一个失败测试 -> 最小实现 -> 变绿 -> 再下一个行为一度に少量だけ進めてください。それは理解できるほど小さく、AI がストーリーを作るのが難しいほど小さく、失敗したときにすぐに特定できるほど小さいです。
モデルが「スムーズにプレイできる」ように制限されます。
AI によくある問題は、過度の熱意です。
境界のバグを修正するように要求すると、ヘルパーが抽出されます。テストを追加するように要求すると、実装が変更されます。リファクタリングを要求すると、動作が変わります。
TDD はフェーズを使用してこれらのアクションを分離します。
| ステージ | 何をすべきか | してはいけないこと |
|---|---|---|
| レッド | 失敗するテストを書く | 本番環境の実装を作成する |
| グリーン | 最小限の実装を書く | 緑色になるようにテストを変更します。 |
| リファクター | クリーンアップ構造 | 新しい動作を導入する |
「ご注意ください」よりもこの表の方が役に立ちます。これにより、モデルがどの段階にあるかを認識できるようになり、人間が境界違反を検出しやすくなります。
3. 赤と緑の再構築: 3 つのスローガンではなく 3 つのドア
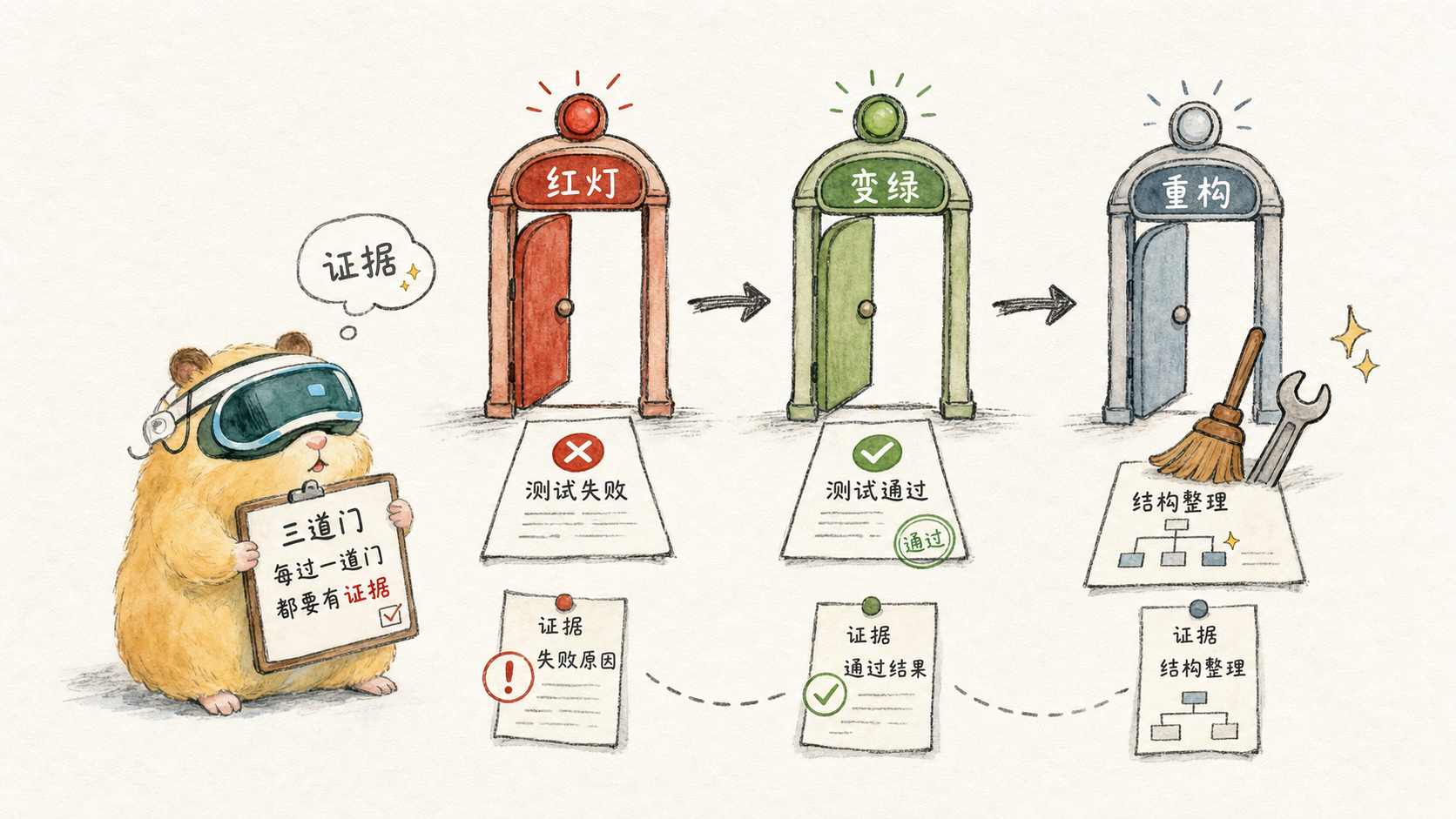
「レッド、グリーン、リファクタリング」は簡単にスローガンになる可能性があります。実際に使用すると、3 つのドアのように見えるはずです。ドアを通過するたびに証拠を残さなければなりません。
最初の扉: 赤、ニーズが満たされていないことを証明
RED フェーズ中の最も重要な質問は次のとおりです。
このテストが失敗した場合、目標とする行動がまだ不足していることが証明されるのでしょうか?
悪い赤:
assert TrueREDもあまり良くありません:
assert "hello" in format_title("Hello World")広すぎます。多くの欠陥のある実装も合格します。
より良い赤:
def test_slugify_lowercases_and_uses_hyphen():
assert slugify("Hello World") == "hello-world"このテストは小規模ですが、明らかです。入力、出力、および動作を指定します。
2 番目のドア: 緑、現在のテストのみを通過させます
GREEN フェーズは、最終的なアーキテクチャを記述することではありません。
ミッションは 1 つだけです。それは、現在失敗しているテストに最小限のコードで合格することです。
この発言は直感に反して聞こえます。多くの人は、「最小限の実装」があまりにも醜いのではないかと心配しています。はい、時には醜いこともあります。しかし、その価値は設計圧力を維持することにあります。
最初のテストが次の場合:
def test_slugify_lowercases_and_uses_hyphen():
assert slugify("Hello World") == "hello-world"許容される GREEN は次のとおりです。
def slugify(text: str) -> str:
return text.lower().replace(" ", "-")中国語、アクセント、連続句読点、絵文字、SEO の特殊なケースをすぐにサポートする必要はありません。これらは後のテストによって駆動される必要があります。
3 番目のドア: REFACTOR、構造のみを変更し、動作は変更しません
REFACTOR ステージは AI によって最も混乱されやすいです。
「コードを整理する」を「ついでに強化する」と解釈します。これではうまくいきません。リファクタリングの定義は非常に狭いです。外部の動作は変わりませんが、内部構造は改善されます。
適切なリファクタリングは次のようになります。
- 変数名をより正確なものに変更します
- 繰り返される表現を抽出する
- 深すぎる条件分岐を削除する
- モジュールの責任を明確にするために関数の場所を移動します。
悪いリファクタリングは次のようになります。
- 新しい入力がサポートされるようになりました
- エラーメッセージを簡単に変更しました
- 依存関係を簡単に変更
- テストアサーションを便利に変更しました
判断基準はシンプルです。
このコミットが
refactor:と呼ばれただけであれば、テストの前後で同じ緑色になるはずで、ユーザーの動作も同じになるはずです。
4. 良いテストの味
TDD は、テストが多ければ多いほど良いというものではありません。 AI は、ほとんど価値のないテストを大量に生成することにも優れています。
さらに重要なのは味を試すことです。
優れたテストは仕様書のようなものです
優れたテストは、ビジネス仕様のように読み取る必要があります。
当用户没有权限时,保存按钮不可点击。
当标题为空时,表单显示错误信息。
当重复提交同一个请求时,只创建一条记录。それは内部で行われることではなく、外部の動作に関係します。
悪いテストは実装ノートのように見えます。
应该调用 validateInput 三次。
应该读取 state.user.flags。
应该触发 handleClick 内部函数。実装の詳細が決まると、リファクタリングは困難になります。内部構造を変更しただけですが、大規模なテストは失敗しました。このようなテストでは、コードを保護するのではなく、コードをフリーズします。
優れたテストには限界がある
テストは 1 つの質問にのみ答えるように設計するのが最適です。
テストで次のこともアサートされる場合:
- 正しい形式
- 権限は正しいです
- ネットワークリクエストは正しいです
- トースト コピーは正しいです
- データベースのステータスが正しい
失敗すると、何が問題なのかを知るのは困難です。
AI は一度に多くのことを証明したいため、このような「大規模で包括的な」テストを作成する傾向があります。 TDD はその逆で、アクション、失敗、実装です。
優れたテストにより、実装での不正行為が困難になります
テストがあまりにも具体的な入力のみをカバーする場合、AI はちょうど一致する偽の実装を作成する可能性があります。
たとえば:
def slugify(text: str) -> str:
return "hello-world"最初のテストでは合格しますが、2 番目のテストでは実際のロジックが強制的に実行されます。
def test_slugify_handles_another_title():
assert slugify("Test Driven Development") == "test-driven-development"したがって、TDD は常に 1 つのテストだけを作成するわけではなく、各ラウンドで 1 つの動作プレッシャーのみを追加します。徐々に圧力が増し、模様が徐々に伸びていきます。
5. AI はどのように TDD を回避するのでしょうか?

AI は本来テストを尊重しないため、この部分を明確にする必要があります。
最適化の目標はシンプルです。先ほど述べたタスクを完了することです。 「テストをパスさせてください」と言うと、人間が望まないアクションを実行する可能性があります。
最初のタイプ: テストを変更して緑色にします
最も典型的なもの:
assert slugify("Hello World") == "hello-world"を現在の出力に変更します- 失敗したアサーションを削除する
skipをテストに追加します- 厳密なアサーションを緩やかなアサーションに変更する
これはTDDではなく、赤い光を消しているのです。
2 番目のタイプ: 書き込みオーバーフィッティング実装
たとえば、テストには入力が 1 つだけあります。
def test_slugify_lowercases_and_uses_hyphen():
assert slugify("Hello World") == "hello-world"モデルは次のように記述できます。
def slugify(text: str) -> str:
if text == "Hello World":
return "hello-world"
return textこのとき叱る必要はありません。実装がハードコーディングされ続けないように、次の動作を追加し続ける必要があります。
3 番目の方法: モックを使用して実際の境界をカバーする
AIはモックが大好きです。モックを使用すると、テストの作成が容易になり、実際の問題の多くが解消されます。
嘲笑できないわけではありませんが、次のことを尋ねる必要があります。
私が今嘲笑しているのは遅い依存関係ですか、それとも本当に検証したい境界線ですか?
支払いコールバック解析を検証したいが、解析層を模擬する場合、テストは無意味になります。
6. TDD を使用しない場合
TDD には価値がありますが、すべてが価値があるわけではありません。
不適切なシーン
- 純粋な視覚的な微調整
- ワンタイムスクリプト
- 技術探索デモ
- 要件自体が明確に考えられていないプロトタイプ
- テスト フレームワークはまだウェアハウスをセットアップしていません
このようなシナリオでは、まず探索速度を追求し、プロセスに足を引っ張られないようにしてください。
適したシーン
- バグ修正
- 権限、課金、ステートマシン
- データ変換と境界処理
- 長期間保守されるコアモジュール
- AIが繰り返し変更するコードパス
判断基準は「この機能が素晴らしいかどうか」ではなく、
間違っていた場合、コストは明らかですか?
コストは明らかなので、最初にテストを作成する価値があります。
7. 実行可能なメンタルメソッド
AI に一言だけ与えるとしたら、次のようには言いません。
请高质量实现这个功能。私ならこう言います:
先写一个失败测试,运行它,确认失败原因符合预期。不要写实现,直到我说 go。この文は、モデルに「適切に動作する」ことを求めているのではなく、チェック可能なプロセスに入るように求めているため、より高品質です。
もう少し完全なもの:
每轮只处理一个行为。
RED:写一个失败测试并运行。
GREEN:写最小实现,不改测试。
REFACTOR:只在绿色状态下整理结构。
每轮报告测试文件、命令、失败原因、通过结果。これがAI時代のTDDの核心です。
テストやプロセスについて迷信深いのではなく、すべてのステップについて証拠を持つことについて考えています。
終わりに
AI プログラミングに最も必要なのは、より多くのコードではなく、より短いフィードバックです。
TDD の価値は次のとおりです。TDD は、「正しいはずだと思っていた」ことを、「ここで失敗したが、その後青信号になった」に変えるのです。変化は小さいですが、十分に現実的です。
一文しか覚えていない場合は、次のことを思い出してください。
AI にコードを直接配信させないでください。最初に赤色の光を照射し、次に赤色の光を緑色に変えます。
次の記事 実践ガイド では、このリズムを直接コピーできるワークフローに変換します。
推奨リソース
Augmented Coding: Beyond the Vibes
Kent Beck's first-person account of using AI agents while keeping engineering discipline.
Red/green TDD
Why red/green TDD is a useful compact instruction for coding agents.
Test-Driven Development: By Example
The original book that defined the red-green-refactor loop.