
中文 AI 圈不是靠转发增长的
从 165 个 AI 相关账号和 2192 条公开帖子出发,拆解 X 上 AI 内容的流量结构、发帖频次、内容重合度,以及普通创作者更值得占据的位置。
最近我认真想一个问题:如果我也想把 X 做起来,应该学谁?
我原本以为答案会是一份名单:中文 AI 大 V、英文源头账号、AI 编程作者、出海 SaaS 创作者、独立开发者。把他们每天发什么拆出来,照着发一段时间,应该就能找到感觉。
抓完 165 个账号、2192 条公开帖子后,我发现这个想法太粗了。
真正的问题不是“谁最火”,而是这些流量从哪里来,又有什么部分是普通创作者能复制的。
这篇文章就是我被数据纠正直觉的过程。
我是怎么看的
为了不靠感觉,我从自己的关注列表出发,又补充了一批中文 AI 圈、AI 编程、Agent、独立开发、出海 SaaS、设计增长和英文源头账号。最后形成 179 个候选账号,其中 165 个进入抓取样本。
我看的不是“谁粉丝最多”,而是几个更接近增长的问题:
- 他们最近到底在发什么,频次是什么节奏?
- 哪些内容拿到了明显更高的浏览?
- 哪些内容其实在转同一个源头,哪些表达真的能被普通创作者复制?
这次样本规模如下:
| 指标 | 数量 |
|---|---|
| 候选账号 | 179 |
| 实际抓取账号 | 165 |
| 有帖子样本的账号 | 161 |
| 帖子样本 | 2192 |
| 有浏览量数据的帖子 | 2145 |
| 可视为原创或账号自有内容的样本 | 1926 |
| 明确识别为转帖/他人原帖的样本 | 219 |
| 重复出现的同一条 status URL | 24 |
先说明限制:这不是 X 官方 API 的全量数据,而是一次登录态下公开页面的可见快照。它适合研究内容结构,不适合做严肃排行榜。X 页面会混入转帖、引用、置顶帖,也会因为加载失败导致少量账号拿不到帖子。所以我单独做了原创/转帖校正,避免把别人原帖的千万浏览误算到转发者身上。
一旦把“原帖”和“转帖”分开,很多看上去很热闹的增长幻觉就消失了。
AI 内容是一条链
一开始我以为目标很简单:看中文 AI 圈的大号。
但抓完第一轮我发现,如果只看中文 AI 大 V,会漏掉真正影响传播的上游和下游。
X 上的 AI 内容大概沿着这条链流动:
- 英文源头:OpenAI、Anthropic、xAI、Google DeepMind、Karpathy、Simon Willison、swyx、Ethan Mollick 等。
- 产品和公司号:Vercel、Raycast、Zed、Dia、Obsidian、Cursor、Ollama、Hugging Face 等。
- 技术解释者:把源头事件解释成开发者能理解的判断。
- 中文本地化账号:把英文事件转译成中文语境里的工具、机会和行动建议。
- 独立开发和出海账号:把 AI 叙事接到赚钱、增长、SEO、SaaS、Build in Public。
- 设计和作品展示账号:把 AI 能力变成看得见的界面、动画、产品和审美。
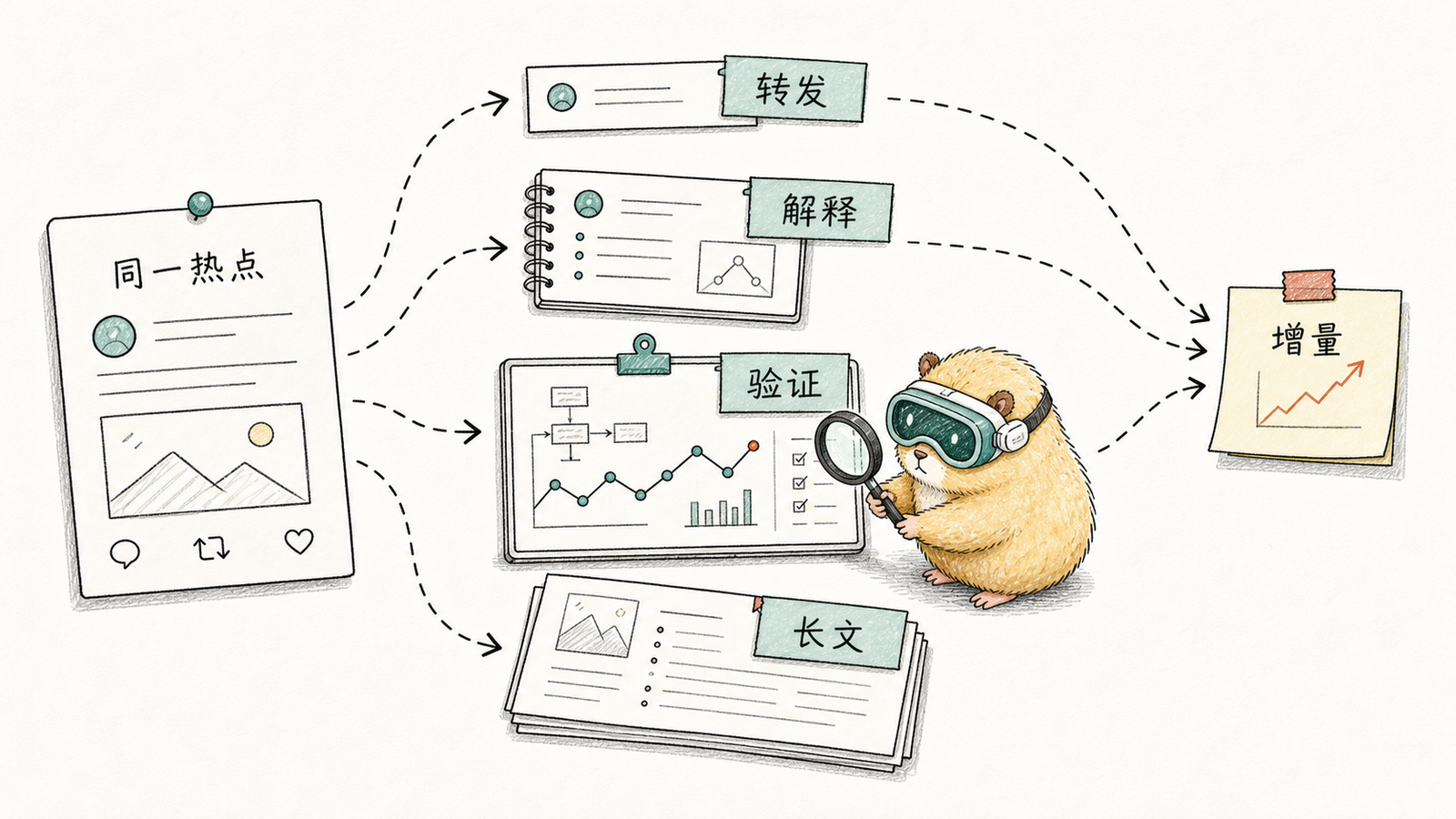
如果只看中文 AI 资讯号,最后很容易学成“热点搬运”。但如果要长期增长,就要先判断自己能在这条链上提供什么增量。
别学最大号
下面这张表看起来很诱人,但也最容易误导人。
| 类别 | 账号数 | 原创样本数 | 最高浏览 | 中位浏览 |
|---|---|---|---|---|
| 英文源头 | 30 | 314 | 7279 万 | 3.8 万 |
| 产品/公司号 | 11 | 106 | 1061 万 | 1.5 万 |
| AI 编程/Agent | 17 | 191 | 790 万 | 5587 |
| 中文 AI 核心 | 25 | 272 | 76 万 | 4641 |
| AI 创业/产品 | 8 | 156 | 96 万 | 3948 |
| 出海/SaaS | 13 | 255 | 48 万 | 2088 |
| 独立开发/Build in Public | 8 | 156 | 19 万 | 2182 |
| 设计增长 | 8 | 84 | 2871 万 | 4101 |
第一眼看,英文源头、官方号、设计增长账号的最高浏览非常夸张。但这里面有大量“位置红利”:产品发布、模型更新、加入大公司、官方声明、招聘、融资、重大安全事件。
比如 xAI 发 Grok Build,是事件源头;OpenAI 发一句极短的发布预告,是品牌源头;Karpathy 更新加入 Anthropic,是身份事件;Benji Taylor 加入 X 负责设计,也是身份事件。
这些内容的流量很高,但普通创作者不能直接复制。你不能通过模仿 OpenAI 的语气变成 OpenAI,也不能通过模仿 Karpathy 的个人更新获得 Karpathy 的身份信用。
真正值得复制的是另一层东西:源头事件出现之后,谁能最快解释它,谁能真的试用它,谁能把它和普通人的工作、产品、代码、增长联系起来。
所以这张表真正告诉我的不是“去学最大号”,而是:源头账号提供事件原料,中文账号争夺解释权,实践者争夺验证权。长期增长来自你能反复占据哪一种权利。
爆款先给承诺
我把 1926 条原创样本按主题粗分,结果是这样:
| 主题 | 样本数 | 最高浏览 | 中位浏览 |
|---|---|---|---|
| AI 编程/Agent | 585 | 7279 万 | 6365 |
| AIGC/设计 | 388 | 3196 万 | 5846 |
| 模型/产品发布 | 171 | 2749 万 | 8303 |
| 观点/日常/转发 | 625 | 1494 万 | 4831 |
| 教程/方法论 | 34 | 76 万 | 5545 |
| 创业/增长 | 90 | 45 万 | 3651 |
| 研究/论文 | 14 | 17 万 | 4355 |
如果只看最高浏览,AI 编程、AIGC、模型发布最容易爆。但如果看中位数,它们并没有高到离谱。大多数内容仍然是几千浏览,真正爆的是少数承诺特别清楚的内容。
我看到的高流量内容,大概有六种结构。
源头发布:给入口
典型是 xAI 的 Grok Build,样本最高 7279 万浏览。
这类内容的结构很直接:某能力开放了,谁可以用,能做什么,入口在哪里,最好再配一张图或一段视频证明。
普通个人账号不能复制“官方发布”这个位置,但可以复制它的二次内容形式:第一时间试用,给出截图、失败点、适用场景和本地化解释。
对我来说,这类内容不是“我要转发”,而是“我要抢二次解释权”。
强判断:改框架
@steipete 有一条 790 万浏览的短帖,大意是:不要再只 prompt coding agents,而要设计能反过来 prompt agents 的 loops。
它不是教程,也不是资讯。它高流量的原因是把很多人模糊感受到的变化压缩成一句判断。
这类内容通常满足三个条件:
- 说的是一个正在发生的变化。
- 句子短,容易被转述。
- 不是空洞口号,而是能立刻引出一套方法论。
这对中文创作者很重要。很多中文 AI 内容太像“工具说明书”,有用,但没有记忆点。工具说明书能收藏,却不一定让人记住你。
技术长文:造概念
@trq212 的 Claude Code 动态工作流文章样本有 290 万浏览。它不是简单说“Claude Code 更新了”,而是给了一个新概念:为每个任务生成自己的 harness。

这类长文的结构通常是:
先给一个新概念
解释它解决什么旧问题
展示机制或例子
说明为什么这会改变工作流
最后给读者一个可以复用的说法高流量技术长文不是越长越好,而是要让读者读完之后多一个概念工具。比如“prompt agents”变成“design loops”,“写代码”变成“为任务生成 harness”。
身份事件:自带流量
Karpathy 加入 Anthropic 的个人更新样本有 2749 万浏览。Benji Taylor 加入 X 负责设计的置顶帖有 2871 万浏览。
这类内容不是靠写作技巧,而是靠身份事件:
我加入了某个关键组织
我为什么相信这个方向
我接下来要做什么
我邀请谁一起参与普通人当然没有这种新闻性,但可以学它的“身份叙事”:我是谁,我正在转向什么,我为什么把时间押在这里。
如果我想在 X 上发展,不能只发工具笔记,也要持续建立一个别人能理解的身份:我到底是 AI 编程实践者、工具构建者、中文技术解释者,还是独立开发者。
资源清单:壁垒在筛选
样本里有一条被多个账号转发的中文帖子:推荐 10 个研究 AI 赚钱的 X 博主。它在三个样本账号里重复出现。
资源清单的优点是收藏动机强,缺点是同质化也快。真正有壁垒的不是列名字,而是解释“为什么看这批人、每个人适合学什么、不适合学什么,以及我自己的判断标准”。
作品展示:先给结果
设计增长类样本里,高流量经常来自作品、界面、动效、招聘或产品愿景。比如设计负责人加入 X、AI 生成界面、产品交互演示、工具更新视频。
这类内容有一个特点:首屏不需要读者相信你,先让读者看到东西。纯文字解释“AI 很强”已经很难打动人,真正有传播力的是结果、耗时对比、失败细节和可复现的一小段过程。
热点可以重合
我把重复出现的 status URL 单独拉出来看,重合主要来自三类:英文源头大事件、中文圈互推清单、开发者工具生态里的互相引用。
这种重合本身很正常。大家都盯着同一批英文源头,也都在追 Claude Code、OpenAI、xAI、LlamaIndex、Agent 工作流这些高关注主题。问题不是“能不能写同一个热点”,而是你写完之后有没有增量。
我的判断是:热点可以重合,结论不能重合。同一条新闻,资讯号会说“发布了什么”;解释者会说“这说明什么”;验证者会说“我试了,实际是这样”;应用者会说“我把它用在了这个具体工作里”。
如果只是转发,读者记住的是源头。如果你能给出自己的判断、实验或场景,读者才会开始记住你。
低频很难被记住
这次抓取里,有 134 个账号拿到了带时间戳的帖子。用可见样本粗略估算,发帖频次差异很大:
| 类型 | 例子 | 可见频次特征 |
|---|---|---|
| 高频资讯/转发 | @xiaohu、@Gorden_Sun、@TheRundownAI | 一天多条,跟热点走 |
| 高频讨论型 | @oran_ge、@vista8、@AlchainHust | 多条短观点 + 引用 + 互动 |
| 稳定实践型 | @lxfater、@servasyy_ai、@realcoreychiu | 每天或隔天多条,混合项目进展和观点 |
| 低频高权重 | @karpathy、@simonw、@emollick | 不靠频率,靠身份和判断质量 |
| 产品官方号 | @OpenAI、@xai、@vercel | 围绕发布节奏,不需要日更 |
对普通创作者来说,低频高权重很难一开始就做到。没有足够身份信用之前,低频通常等于消失。
但高频也不能理解成灌水。比较可行的节奏应该是:
每天 3-5 条短内容维持存在感
每周 1-2 条可收藏内容建立价值
每月 1-2 篇长文或 thread 建立认知资产
遇到大事件时快速做二次解释这里的关键不是“每天必须发几条”,而是不要把 X 当成只发成品的地方。X 更像一个公开思考流:短帖负责让别人持续看见你,长文负责让别人重新理解你。
长文要给框架

我原本以为 X 上所谓高流量长文,关键是“写得长”。抓完样本后发现不是。高流量长文的关键是给读者一个新的解释框架。
我看到的长文和 thread,大致有三种有效结构。这里不能只放一张表,否则会丢掉真正可操作的写法。
反常识 + 证据
适合技术观点、趋势判断和方法论文章。它的核心不是“我有一个想法”,而是“读者原本以为 X,但我用证据说明 Y 更接近事实”。
大家以为 X
我观察到 Y
为什么这个差异重要
证据 1、2、3
这个判断适用于什么场景
它不适用于什么场景这类文章的标题不能太温和。比如不是“Claude Code 的一些使用心得”,而是“你不应该再 prompt coding agents,你应该设计 loops”。强标题不是标题党,前提是正文能给证据和边界。
结果 + 拆解
适合 AI 编程、独立开发、出海产品和 Build in Public。读者先看到结果,才会愿意看过程。
我做出了什么结果
以前怎么做
现在用 AI 怎么做
具体流程是什么
哪里失败了
哪些经验可以复用
下一步要验证什么这类内容的第一屏最好有截图、数据、视频、仓库、用户反馈、收入或耗时对比。没有结果,文章很容易变成方法论自嗨。
信息源 + 策略
也就是我现在这篇文章。它适合把一个模糊目标变成可执行地图。
我为什么要研究这个问题
我怎么采样
我看到了什么结构
哪些结论和直觉不同
这些结论如何改变我的行动这种文章的价值不在于“我发现了某个大 V 很厉害”,而在于把样本、判断和行动策略连起来。读者看完之后,不只是知道几个账号,而是知道自己应该怎么观察、怎么选择位置、怎么开始做。
简单压缩成表格,是这样:
| 结构 | 适合写什么 | 第一屏要给什么 |
|---|---|---|
| 反常识判断 + 证据 | 技术观点、趋势判断 | 一个足够锋利但能被证明的判断 |
| 项目结果 + 系统拆解 | AI 编程、独立开发、出海产品 | 截图、数据、视频、用户反馈或耗时对比 |
| 信息源研究 + 个人策略 | 账号研究、行业观察、方法复盘 | 研究动机、样本规模和一个反直觉结论 |
我的定位
看完这批样本,我不想把自己定位成“AI 资讯号”。
资讯号很累,而且中文 AI 圈已经有很多人做得很好。我的优势不在于第一时间知道所有新闻,而在于我能把 AI 编程、工具链、Agent 工作流、产品构建和真实项目经验连起来。
更适合我的定位可能是:
AI 编程和 Agent 工作流的中文实践者。
用真实项目验证工具,用长文沉淀方法,用短帖记录过程。对应到内容栏目,我会这样拆:
| 内容层 | 写法 | 目的 |
|---|---|---|
| 每日短帖 | 今天我用 X 做了 Y,结果发现 Z | 让别人知道我每天都在真实使用 |
| 工具验证 | 拿自己的项目试 Claude、Codex、Cursor、OpenClaw 等工具 | 从转述者变成测试者 |
| 长文/thread | 把一次经验提炼成别人可以引用的概念 | 建立长期心智 |
| 数据研究 | 复盘中文 AI 圈高流量内容、AI 编程账号结构、出海 SaaS 流量来源 | 形成可收藏的公开样本 |
这套定位的重点不是“我知道所有 AI 新闻”,而是“我能用真实项目验证这些工具,并把经验讲清楚”。
关键结论
如果只记三件事,我会记这三件。
第一,X 增长不是只靠热点,而是靠你在信息链里的位置。普通人最可行的位置通常不是源头,而是解释者、验证者和应用者。
第二,中文 AI 圈内容重合是正常的。真正的差异来自:你有没有自己的实验、自己的判断、自己的使用场景。
第三,短帖负责进入信息流,长文负责建立心智。只写长文很慢,只写短帖很散。更合理的是短帖记录过程,长文沉淀框架。
下一步怎么做
我准备先用 30 天验证一个简单节奏:
每天 3 条短帖:
1 条工具/模型更新的个人判断
1 条真实项目里的 AI 工作流记录
1 条引用或回复别人的高质量讨论
每周 1 篇长帖:
围绕一个具体问题,给出实验、截图、结论和边界。
每月 1 篇博客:
把 X 上跑出来的内容沉淀成系统文章。如果这个节奏有效,X 不再只是信息消费平台,而会变成我的公开实验室:我在那里验证想法,在博客里沉淀方法,在项目里证明结果。
这次研究只是第一版地图。真正的增长,还是要回到每天具体发什么、怎么回复、怎么验证、怎么复盘。
但至少现在我知道,自己不应该盲目模仿某个“大 V”。我应该先选定自己在这条信息链里的位置。