自己改善するエージェントは何を改善しているのか
Reflexion、Voyager、ADAS、AFlow、DGM、SEALからAlphaEvolveまで、自己改善エージェントの技術マップ、主要論文、エンジニアリング実践、リスク境界を整理します。
現在、自己改善エージェントを体系的に理解しようとする場合、まず漠然とした言葉を追いかけるのではなく、次の4つのことを明確にすることが真のニーズだと私は考えます。
- それは一体何を「自己改善」しているのか?
- この改善は推論時、タスク間、それとも再トレーニング時に行われるのか?
- 自分が本当に良くなったと、何に基づいて判断するのか?
- どの方向がすでに実用化されており、どの方向がまだ研究プロトタイプの段階にあるのか?
まず結論から述べます。今日の自己改善エージェントは、SFに出てくるような「モデルが自ら覚醒し、無限に再帰的にアップグレードする」ものではありません。より正確に言えば、エージェントシステムが自身の失敗、軌跡、フィードバック、評価結果を、次により良い行動のための閉ループに変換するものです。
この閉ループは、非常に軽いものから非常に重いものまであります。
軽いものはReflexionやSelf-Refineのようなもので、モデルのパラメータを変更せず、反省をコンテキストや記憶に書き込むだけです。重いものはSEALのようなもので、モデルが自身のトレーニングデータと更新指示を生成し、実際に重みを変更します。その中間で今日最も注目すべき層は、プロンプト、ツール、ワークフロー、コードを変更し、実行可能な評価で検証するものです。
したがって、自己改善エージェントにとって最も重要なのは「自己(self)」ではなく「改善(improving)」です。評価も、回帰も、対照実験もなければ、モデルがなぜうまくできたのかを繰り返し説明させるだけになってしまいます。
まず定義:それは一つのものではない
多くの記事では、自己改善(self-improving)、自己進化(self-evolving)、自己適応(self-adapting)、再帰的自己改善(recursive self-improvement)を混同して説明しています。これでは問題が曖昧になってしまいます。
私はこれをエンジニアリングの問題として分解したいと考えています。
エージェントはタスク完了後、フィードバックを利用して自身の構成要素の一部を修正し、その後のタスクで安定して改善できるか?
ここには3つのキーワードがあります。
第一に、フィードバック。フィードバックは、テスト、コンパイラ、環境報酬、人間のコメント、LLM-as-judge、生産ログ、あるいはエージェント自身による失敗軌跡の反省から得られます。
第二に、修正対象。コンテキスト、記憶、プロンプト、ツール記述、ワークフロー、コード、トレーニングデータ、報酬モデル、さらにはモデルの重みまで変更できます。
第三に、安定した改善。これが最も難しい点です。一度のタスクで改善するだけでは不十分で、それが過学習ではないこと、偶然ではないこと、コストが急増していないこと、安全境界が損なわれていないことを証明する必要があります。
この表を使って、まずメンタルモデルを構築できます。
| 改善対象 | 典型的な形式 | 利点 | 最大のリスク |
|---|---|---|---|
| コンテキスト | 反省、経験、few-shotの例 | 最も実装が容易で、トレーニング不要 | 記憶汚染、コンテキスト膨張 |
| プロンプト | 指示の自動検索、例の生成 | 低コストで、生産システムに適している | 評価の過学習、汎用性の説明が難しい |
| ツールとワークフロー | エージェントのプロセス、ツール呼び出し順序の自動設計 | エージェントの能力上限に直接影響 | 検索空間が大きく、回帰が難しい |
| コード | エージェントが自身のツール、足場、実行ロジックを修正 | 「自分自身を修正する」に最も近い | 信頼できないコードの実行、高いセキュリティ要件 |
| トレーニングデータ | 自己生成データ、自己評価報酬 | モデル能力として蓄積可能 | データ崩壊、報酬の欺瞞 |
| モデルの重み | SFT、DPO、RL、テスト時更新 | 持続的な能力向上をもたらす可能性 | 忘却、コスト、オンラインの安全性とロールバック |
これが、自己改善エージェントを「モデルが使えば使うほど賢くなる」と単純に理解しない方が良い理由です。本当に議論すべきは、どの層を修正しているのか、フィードバックはどこから来るのか、修正後にどう検証するのかです。
第一段階:反省、重みは変更しない
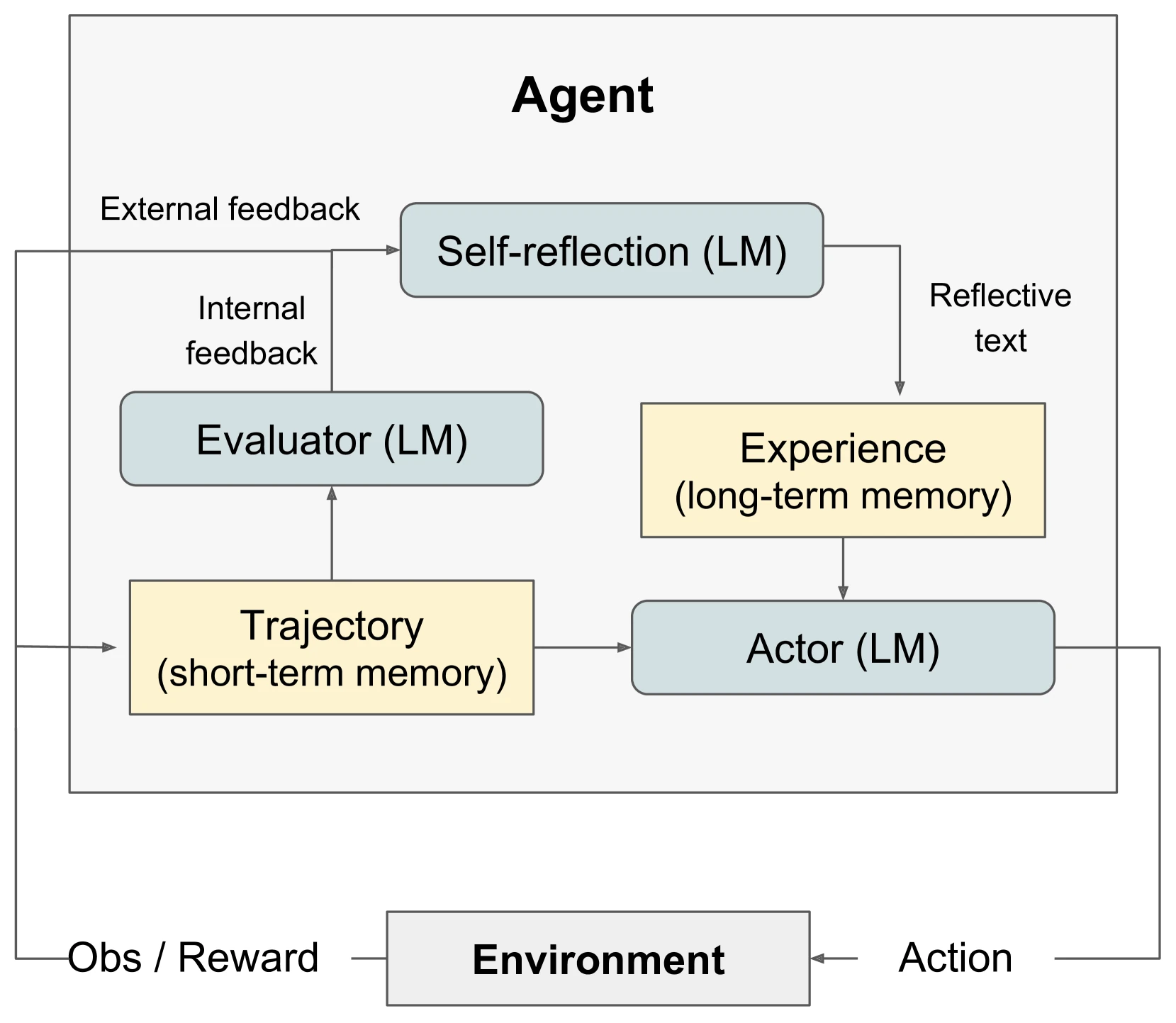
初期の最も代表的なアプローチは、モデルが失敗した後に反省を書き出し、その反省をコンテキストに戻すというものでした。
Reflexion の核心的な考え方は、エージェントが勾配更新によって学習するのではなく、タスクのフィードバックを言語的な反省に変換し、エピソード記憶に保存し、次回類似のタスクに遭遇した際にそれを利用するというものです。その意義は、特定のベンチマークスコアではなく、「試行錯誤学習」を従来のRLのパラメータ更新から、エージェントがすぐに利用できる言語記憶へと変えた点にあります。
Self-Refine はさらに直接的で、モデルがまず回答を生成し、次に自身の回答にフィードバックを与え、そのフィードバックに基づいて書き直します。このパターンは現在、多くのエージェントフレームワークの基本的なモジュールとなっています。まず実行し、次にレビューし、次に修正する、という流れです。
STaR はトレーニングデータのアプローチを取ります。モデルがまず推論プロセスを生成し、誤った回答をフィルタリングし、正しい回答につながる根拠(rationale)を保持し、これらの根拠を使ってモデルをトレーニングします。これは完全なエージェントではありませんが、後の多くの自己改善手法に重要なヒントを与えました。それは、モデルが自身の成功軌跡からトレーニング信号を抽出できるということです。
これらの方法の利点はシンプルさですが、欠点も明らかです。反省は改善を意味しません。モデルはもっともらしい振り返りを書くのが得意ですが、外部からの検証がなければ、単に自分の間違いをよりうまく説明できるようになっただけかもしれません。
したがって、反省型エージェントの境界は明確です。短期間の行動修正には適していますが、長期的な能力向上を証明するものとしては適していません。
第二段階:経験をスキルライブラリに変える
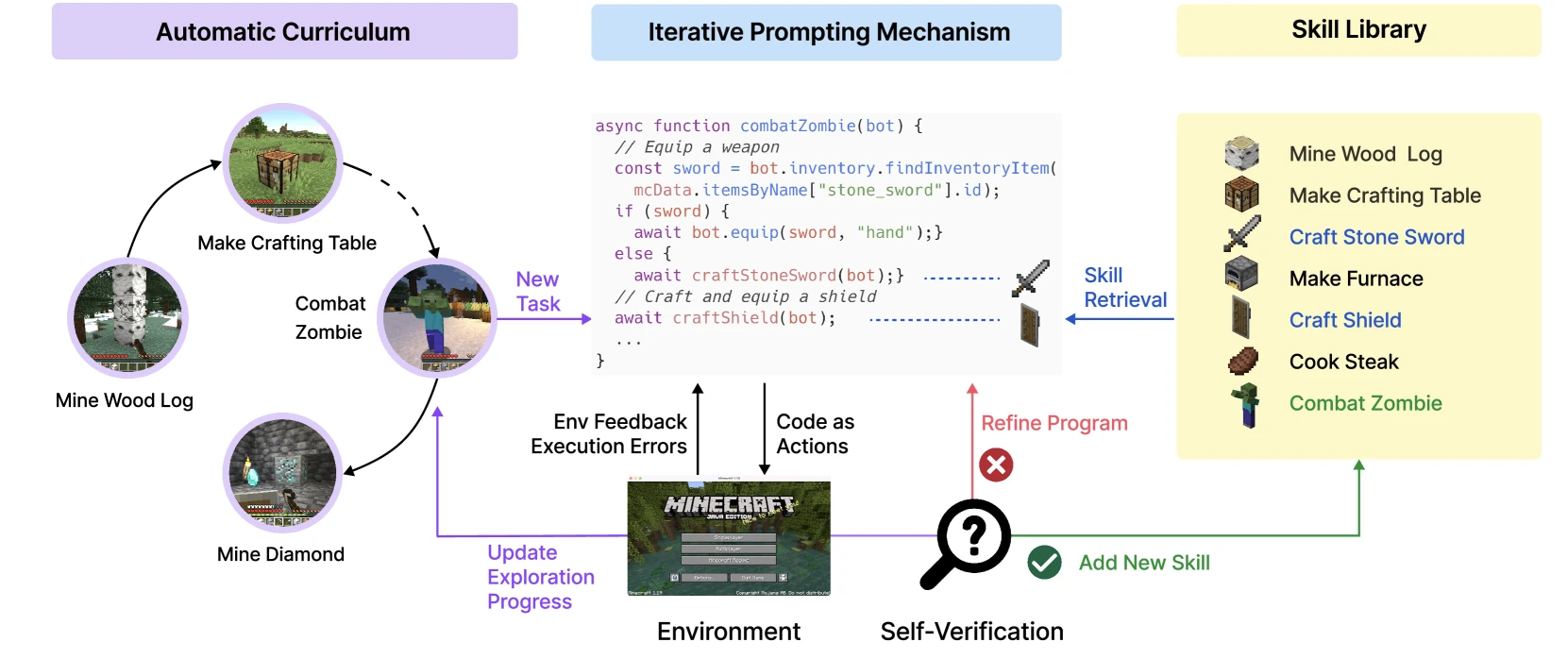
Voyager は、私が必読と考える論文の一つです。これは自己改善エージェントを「回答の書き換え」から「スキルの蓄積」へと進めました。
VoyagerはMinecraft環境で3つのことを行います。
- 自動的に探索カリキュラムを生成する。
- 成功した行動を実行可能なコードスキルとして保存する。
- 環境フィードバック、実行エラー、自己検証に基づいてプログラムを繰り返し改善する。
ここで最も重要なのはMinecraftではなく、「スキルライブラリ」という構造です。これにより、エージェントの改善は単に次のプロンプトが長くなるだけでなく、検索可能で、組み合わせ可能で、再利用可能なプログラム資産として蓄積されます。
これは実際の製品にとって非常に示唆に富んでいます。多くのチームが自己進化エージェントを作ると言いますが、実際の第一歩はモデルをトレーニングすることではなく、エージェントがタスクを完了するたびにその軌跡を次の3種類の資産に整理することです。
| 資産 | 例 | 再利用方法 |
|---|---|---|
| 成功パス | ある種の問題に対する安定した手順 | ワークフローテンプレートとして |
| 失敗の教訓 | どのツール順序がエラーを引き起こすか | ガードレールまたは反例として |
| 実行可能なスキル | スクリプト、関数、コマンド、操作説明 | ツールライブラリまたはスキルライブラリに組み込む |
つまり、実用的な自己改善エージェントは、まず毎晩こっそり自分自身をトレーニングするモデルというよりも、作業日誌を書くエンジニアのようであるべきです。
第三段階:プロンプトとワークフローの自動最適化
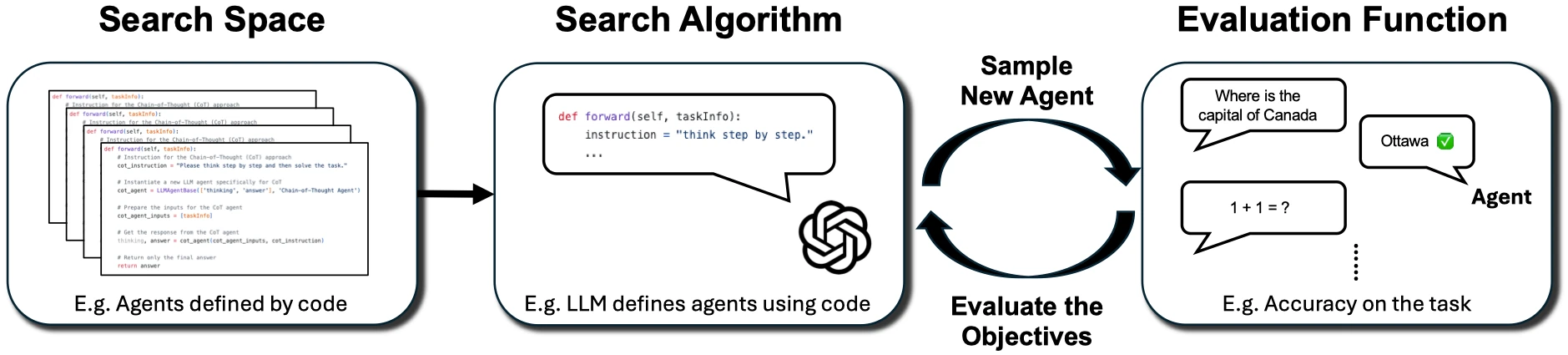
2024年から2025年にかけて、重要な変化が現れました。人々はエージェントに「反省」させるだけでは満足せず、エージェントにエージェントを自動設計させるようになりました。
OPRO はLLMを最適化器として利用し、モデルが過去の候補解とスコアに基づいて次の候補群を提案するようにします。この考え方は、後に多くのプロンプト最適化器に受け継がれました。手動でプロンプトを調整するのではなく、タスク、データセット、指標を定義し、システムに最適な指示を検索させるのです。
DSPyのMIPROv2 と GEPA は、このことをよりエンジニアリング的に進めました。特にGEPAは、単一のスカラー値のスコアを見るだけでなく、モデルに完全な実行トレースを読み取らせ、自然言語で失敗原因を診断し、プロンプトを進化させることを強調しています。この方向は実際のエージェントに非常に適しています。なぜなら、エージェントの失敗は「最終的な回答が間違っていた」という単純なものではなく、ツールの選択ミス、検索ミス、ルーティングミス、フォーマットミス、中間状態のミスなど、多岐にわたるからです。
ADASはAutomated Design of Agentic Systemsを提案しました。これは、メタエージェントがコード空間で新しいエージェント設計(プロンプト、ツール使用、制御フロー、組み合わせ方法を含む)を発明するというものです。AFlowは、エージェントのワークフローをコード内のノードとエッジとして表現し、検索手法を用いてワークフローを自動的に修正・評価します。
この方向の鍵は「モデルが美しいプロンプトを書けるかどうか」ではなく、エージェントの構造自体が検索可能、評価可能、反復可能なオブジェクトになったことです。
これはエンジニアリングの実践にとって非常に重要です。なぜなら、実際のエージェントのボトルネックは、単一の回答ではなく、システム構造にあることが多いからです。
- まず検索してから計画すべきか?
- ツールが失敗した場合、再試行するか、ツールを切り替えるか、ユーザーに尋ねるか?
- 複数のエージェントは直列に連携するか、それともコーディネーターが割り当てるか?
- どの情報を短期コンテキストに入れるべきで、どの情報を長期記憶に入れるべきか?
- いつ停止し、いつ探索を続けるべきか?
これまでこれらの問題は人間が設計していました。自己改善エージェントの研究は、これらの問題を検索問題に変えつつあります。
第四段階:自身のコードを修正する
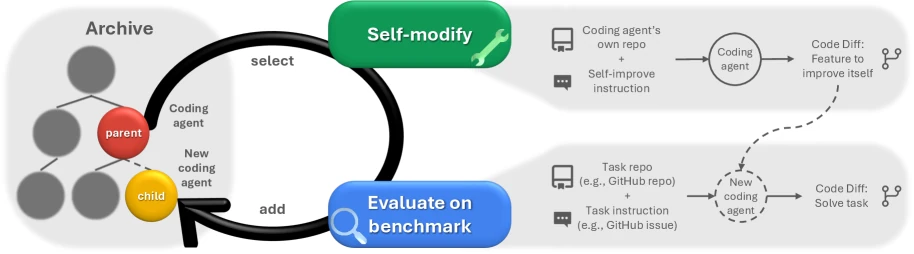
ADASがメタエージェントにエージェントを設計させるものだとすれば、A Self-Improving Coding Agent と Darwin Godel Machine は、文字通りの意味での「エージェントが自分自身を修正する」にさらに近いものです。
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
A self-improving coding agent that iteratively modifies its own code and validates changes on coding benchmarks.
A Self-Improving Coding Agent は、コーディングエージェントが自身の実装を編集し、SWE-bench Verified、LiveCodeBenchなどのタスクで改善を達成する方法を示しています。DGMはさらに進んで、エージェントのアーカイブを維持し、既存のエージェントからサンプリングし、ファウンデーションモデルに新しいバリアントを生成させ、ベンチマークで検証後に高品質なブランチを保持します。
DGMで最も注目すべき点は2つあります。
第一に、単一パスの山登りではなく、複数の進化ブランチを保持していることです。これにより、ある変更が短期的には有効でも、長期的には方向性を固定してしまうことを避けることができます。
第二に、改善しているのは基盤となるファウンデーションモデルではなく、エージェントの外部構造です。具体的には、編集ツール、コンテキスト管理、ピアレビューメカニズム、パッチ検証などです。言い換えれば、これは「モデルが自らより賢い脳を訓練する」ことを証明しているのではなく、「凍結されたモデルの上に、エージェントの足場にはまだ大きな最適化の余地がある」ことを証明しています。
これは今日の製品チームができることにもっと近いものです。新しいモデルを訓練することはできないかもしれませんが、エージェントにサンドボックス内でPRを生成させ、テストを実行させ、指標を比較させ、有効な変更を保持させ、その後人間がレビューしてマージすることができます。
ただし、このアプローチはセキュリティのハードルが非常に高いです。DGMのリポジトリでも明確に警告されていますが、モデルが生成したコードを実行することにはリスクがあります。実際のシステムでは、サンドボックス、権限境界、リソース制限、テストセットの隔離、ロールバックメカニズム、および手動承認が必須です。
第五段階:モデルに自身のトレーニング信号を生成させる
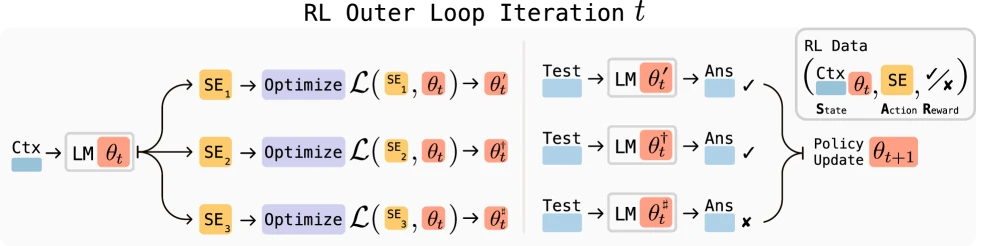
モデルトレーニングにさらに近いもう一つのアプローチは、モデルに自身のデータ、報酬、または更新指示の生成に参加させることです。
Self-Rewarding Language Models は、LLM-as-a-judge を使用して、モデルが自身の出力に報酬信号を提供し、Iterative DPO を介してトレーニングします。その核心的な問題は非常に野心的です。将来、モデルが人間レベルを超えるフィードバックを必要とする場合、モデル自身がフィードバックの品質を段階的に向上させることはできないでしょうか?
SEAL: Self-Adapting Language Models はさらに進んで、モデルにself-editを生成させます。これらのself-editは、合成トレーニングデータ、情報の書き換え方法、ハイパーパラメータの最適化、さらにはデータ拡張や勾配更新ツールの呼び出しなど、多岐にわたります。モデルは下流タスクのパフォーマンスを報酬として、より効果的なself-editを生成する方法を学習します。
Self-Adapting Language Models
A framework where language models generate their own finetuning data and update directives in response to new tasks or knowledge.
また、Self-Improving LLM Agents at Test-Time のようなテスト時自己改善もあります。モデルはまず自身が不確実なサンプルを識別し、これらのサンプルを中心に類似のトレーニング例を生成し、軽量で一時的なパラメータ更新を行い、最後に元のパラメータに戻します。この方向は、「学習」を推論現場にまで押し進めるため、非常に興味深いものです。
しかし、重み更新に近づくほど、より慎重になる必要があります。
なぜなら、モデルの重みが誤ったデータ、自己評価の偏り、または悪意のある入力によって汚染されると、問題は単に特定の回答が間違っていたというだけでなく、システム自体が変化してしまうからです。一般的な製品チームにとって、長期記憶、プロンプト最適化、ワークフロー検索、サンドボックスコードの改善は、オンラインでの自己重み変更よりも現実的です。
最も生産実践に近いのはAlphaEvolve
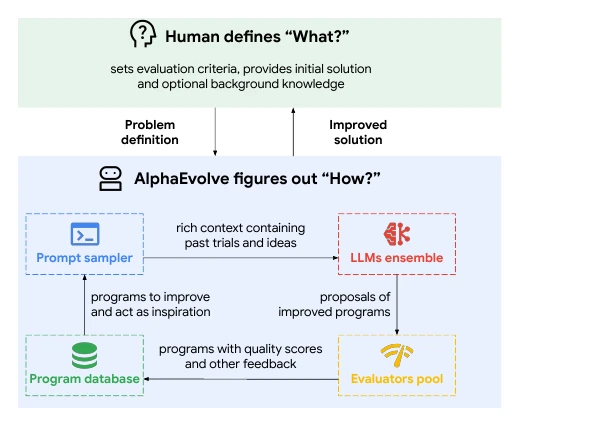
自己改善エージェントの生産形態を見るなら、AlphaEvolve は現在最も研究すべき事例の一つです。
AlphaEvolve: A coding agent for scientific and algorithmic discovery
An evolutionary coding agent that improves algorithms through code changes, automated evaluators, and an evolutionary program database.
AlphaEvolveの核心的な構造は非常にシンプルです。
候補プログラムを生成
実行とスコアリング
高スコアのプログラムをデータベースに格納
データベースに基づいてサンプリングと変異を継続
繰り返しその優れた点は「モデルに考えさせる」ことではなく、タスク選択が自動評価に非常に適していることです。アルゴリズム、スケジューリング、ハードウェア回路、行列乗算、GPUカーネルなど、候補プログラムが実行可能で、検証可能で、スコアリング可能であれば、エージェントは大規模な探索を行うことができます。
Google DeepMindが公開した実践例も非常に具体的です。AlphaEvolveが発見したスケジューリングヒューリスティックはすでにGoogleのデータセンターで使用されており、平均して世界の計算リソースの0.7%を継続的に回収しています。また、TPU回路の簡素化、Geminiトレーニング関連カーネルの最適化、数学的およびアルゴリズム的発見にも使用されています。
これは自己改善エージェントに非常に重要な現実的な判断を与えます。
最も早く実用化される自己改善は、「何でもできる」汎用アシスタントではなく、評価が明確で、フィードバックが安価で、エラーがロールバック可能な狭い分野で現れるでしょう。
コード、アルゴリズム、コンパイラ最適化、データ処理パイプライン、テスト生成、検索ランキング、カスタマーサービスルーティング、内部運用プロセスなどは、オープンなチャットよりも自己改善に適しています。
真の分水嶺は評価(eval)
自己改善エージェントの研究は、最終的に評価に戻ります。
OpenAIのエージェント評価ドキュメントは、このことを非常にエンジニアリング的に説明しています。エージェントワークフローの評価は、トレース、グレーダー、データセット、評価実行を見るべきだと述べています。つまり、最終的な回答だけでなく、完全な軌跡(モデル呼び出し、ツール呼び出し、ハンドオフ、ガードレール、ルーティング、失敗点)を見るべきだということです。
これは自己改善エージェントと完全に一致します。なぜなら、エージェントが自分自身を改善するためには、まずどこが悪いのかを知る必要があるからです。
最低限の自己改善閉ループは次のようになるはずです。
生産またはテストの軌跡
↓
失敗の原因特定:ツールミス、検索ミス、計画ミス、フォーマットミス、権限ミス、停止タイミングミス
↓
候補変更の生成:プロンプト / ワークフロー / ツールスキーマ / メモリルール / コードパッチ
↓
オフライン評価:固定データセット + 回帰セット + コストと遅延
↓
サンドボックス検証:実際のツールだが権限を制限
↓
手動レビューまたは自動カナリアリリース
↓
バージョン管理された資産として書き込みこの一連のプロセスがなければ、いわゆる自己改善は「失敗事例をプロンプトにフィードバックする」ことになりがちです。短期的には改善したように見えても、長期的には3つの問題が発生します。
- 最近の失敗への過学習:今日はAを修正したが、明日Bを破壊する。
- 報酬の欺瞞:エージェントが実際の問題を解決するのではなく、グレーダーに迎合することを学ぶ。
- 境界の漂流:タスクを完了するために、こっそり権限を拡大したり、確認をスキップしたり、不確実性を隠したりする。
したがって、私は評価を自己改善エージェントの基盤であり、付属ツールではないと考えています。
セキュリティ問題は後回しにできない
自己改善を強調すればするほど、セキュリティを後回しにすることはできません。
Anthropicが2026年2月に発表したMeasuring AI agent autonomy in practiceでは、注目すべき2つの傾向が述べられています。Claude Codeの自律作業時間の最長テールが数ヶ月で著しく増加したこと、そして経験豊富なユーザーは自動承認をより頻繁に利用するが、その過程で中断することも多いということです。これは、現実世界のエージェントが単純に「全自動」に向かうのではなく、「より長時間の自律作業 + 人間が重要な瞬間に介入する」方向に向かっていることを示唆しています。
自己改善エージェントにとって、この観察は非常に重要です。
自分自身を修正できるエージェントは、「成功率の向上」という目標だけでなく、以下の制約も同時に最適化する必要があります。
| 制約 | 回答すべき質問 |
|---|---|
| 権限 | どのファイルを変更できるか、どのツールを呼び出せるか、どのデータにアクセスできるか? |
| ロールバック可能 | 各自己変更にはバージョン、差分、テスト、ロールバックポイントがあるか? |
| 説明可能 | なぜこの変更が改善につながると考えたのか?その証拠は何か? |
| 不正防止 | 評価セットは隔離されているか?グレーダーはプロンプトインジェクションによって操作されやすいか? |
| 人間による介入 | どの変更は人間の確認を待つ必要があるか? |
| オンライン監視 | 変更がリリースされた後も品質、コスト、リスク、苦情を追跡しているか? |
私は、真に成熟した自己改善エージェント製品は、「完全な自律性」を宣伝することはないとさえ考えています。それは「監視可能な自律性」を宣伝するでしょう。システム自体が問題を発見し、改善を提案し、ほとんどの検証を完了しますが、重要な権限と長期的な状態は人間または組織のポリシーによって制御されます。
自分で作るなら、どこから始めるべきか
もし私が今日、実際の製品で自己改善エージェントを構築するとしたら、モデルのトレーニングから始めることはありません。私は5つの層で進めます。
第一層:軌跡を完全に記録する
まず、各エージェント実行の入力、コンテキストバージョン、プロンプトバージョン、ツールスキーマ、ツール呼び出し、返された結果、エラー、最終出力、ユーザーフィードバック、手動修正を記録します。軌跡がなければ、学習材料もありません。
第二層:固定評価セットを確立する
実際の失敗事例からサンプリングし、日常の開発によって簡単に汚染されない評価セットを作成します。少なくとも3つのカテゴリに分けます。
| タイプ | 用途 |
|---|---|
| ゴールデンタスク | コア能力が劣化してはならない |
| 失敗回帰 | 修正された問題が再発してはならない |
| 負荷タスク | 長いチェーン、複数のツール、高い権限、曖昧な要件 |
第三層:まずプロンプトとツール記述を最適化する
これは最もコストが低く、リスクも低い層です。GEPA、DSPy、OPROのようなアプローチを使用することもできますし、簡単な候補プロンプト検索から始めることもできます。重要なのは、各候補が同じ評価セットで実行されなければならず、肉眼での感覚に頼らないことです。
第四層:ワークフローを最適化する
プロンプトが一定のレベルまで最適化されると、問題は通常、プロセスに現れます。例えば、検索位置が間違っている、ツールが失敗した後に回復戦略がない、エージェントが早すぎるか遅すぎる停止をするなどです。このとき、AFlow/ADASのようなアプローチを導入し、ワークフローを修正可能なオブジェクトとして表現し、オフライン検索を行うことができます。
第五層:エージェントにコード変更を生成させるが、PRプロセスを経由させる
これはDGM/SICAに最も近い層です。エージェントはコードパッチを提案できますが、そのパッチは通常のエンジニアリング変更と同様に、テスト、レビュー、権限制限、カナリアリリースを経るべきです。本番システムを直接変更させてはなりません。
オンラインでの重み変更については、ほとんどのチームは現時点では手を出すべきではないと私は考えています。非常に成熟したデータガバナンス、評価システム、モデルトレーニング能力、ロールバックメカニズムがすでに整っていない限り、それによってもたらされる運用上の複雑さは、得られる利益をはるかに上回るでしょう。
論文読解ルート
自己改善エージェントを漠然と検索すると、専門用語に埋もれてしまいがちです。私はこのルートで読むことをお勧めします。
- Self-Refine と Reflexion:最も軽量な反省閉ループを理解する。
- STaR と Self-Rewarding Language Models:自己生成トレーニング信号を理解する。
- Voyager:スキルライブラリとオープンエンド環境における継続的な蓄積を理解する。
- OPRO、GEPA、TextGrad:自然言語フィードバックがプロンプト、コード、システムコンポーネントをどのように最適化するかを理解する。
- ADAS と AFlow:エージェントワークフローがどのように自動設計されるかを理解する。
- A Self-Improving Coding Agent と DGM:エージェントが自身の実装をどのように修正するかを理解する。
- SEAL と Self-Improving LLM Agents at Test-Time:重み更新とテスト時適応を理解する。
- AlphaEvolve:生産価値に最も近い進化型コーディングエージェントを理解する。
- A Survey of Self-Evolving Agents:最後にサーベイを読み、概念を完全な分類に戻す。
A Survey of Self-Evolving Agents
A survey organizing self-evolving agents around what, when, and how to evolve.
私の判断
自己改善エージェントは、AGIの物語、つまりモデルが自ら自分自身を修正し、能力が指数関数的に向上するという誤解を招きやすいものです。
しかし、現在の論文と実践から判断すると、より信頼できる判断は次のとおりです。
自己改善エージェントの短期的な価値は、モデルトレーニングを置き換えることではなく、エージェントエンジニアリングを手動調整から評価駆動型の自動最適化へと推進することにある。
その核心的な資産は「より賢いモデル」ではなく、閉ループを形成できるシステムです。
- 実際のタスク軌跡がある。
- 実行可能な評価がある。
- バージョン管理可能なプロンプト、ワークフロー、ツール、メモリ、コードがある。
- 候補変更を自動生成するメカニズムがある。
- 安全境界、回帰テスト、手動承認がある。
これは「再帰的自己進化」ほど刺激的ではないかもしれませんが、より重要です。なぜなら、これによりエージェントは一度限りのデモから、長期的に維持可能なシステムへと変わるからです。
もし将来エージェントが本当に継続的に強くなるのであれば、それはおそらく神秘的な瞬間から始まるのではなく、これらの非常にエンジニアリング的な閉ループから始まるでしょう。つまり、すべての失敗が記録され、すべての変更が評価され、すべての有効な経験が固定され、すべての逸脱した試みが阻止される、というプロセスです。
真の自己改善エージェントは、「私は反省しました」と言うエージェントではありません。
それは「今回の変更が実際にシステムを改善し、かつ境界を破壊しなかった」ことを証明できるエージェントであるべきです。
関連記事
Claude Code を監視する Raycast 拡張機能を作った
「欲しいものは自分で作る」から Claude Code Monitor へ。AI 時代の個人開発者によるツール開発記録。Raycast 拡張機能でセッション監視・トークン使用量・拡張管理を一元化した開発プロセスを紹介します。
Eclipse から Zed へ:ある開発者のエディタ進化史
バックエンド開発からフルスタック開発へ、200以上のプラグインを持つ VS Code からターミナルファーストのワークフローへ。AI時代とともに変わってきた私のエディタ選びの記録
私の Claude Code ベストプラクティス
Claude Code でコードを書く際の知見を共有します。10の核心テクニック、スラッシュコマンド詳解、カスタムコマンド設定で、AIプログラミングの効率を向上させましょう