Self-improving agent 到底在改进什么
从 Reflexion、Voyager、ADAS、AFlow、DGM、SEAL 到 AlphaEvolve,梳理 self-improving agent 的技术地图、关键论文、工程实践和风险边界。
如果现在要系统理解 self-improving agent,我觉得真正的需求不是先追一个很玄的词,而是弄清楚四件事:
- 它到底在“自我改进”什么?
- 这个改进发生在推理时、任务之间,还是重新训练时?
- 它靠什么判断自己真的变好了?
- 哪些方向已经能落地,哪些还停留在研究原型?
我先给结论:今天的 self-improving agent 还不是科幻里的“模型自己觉醒,然后无限递归升级”。更准确的说法是:一个 agent 系统把自己的失败、轨迹、反馈和评测结果,转化成下一轮更好行为的闭环。
这个闭环可以很轻,也可以很重。
轻的是 Reflexion、Self-Refine 这种:不改模型参数,只把反思写进上下文或记忆。重的是 SEAL 这种:模型生成自己的训练数据和更新指令,真的去改权重。介于中间的是今天最值得关注的一层:改 prompt、改工具、改 workflow、改代码,再用可执行评测验证。
所以 self-improving agent 最重要的不是“self”,而是“improving”。没有评测,没有回归,没有对照实验,就只是让模型反复解释自己为什么做得好。
先定义:它不是一个东西
很多文章会把 self-improving、self-evolving、self-adapting、recursive self-improvement 混在一起说。这样会让问题变得很虚。
我更愿意把它拆成一个工程问题:
一个 agent 在完成任务后,能否利用反馈修改自己的某个组成部分,并在后续任务中稳定变好?
这里有三个关键词。
第一,反馈。反馈可以来自测试、编译器、环境奖励、人类评论、LLM-as-judge、生产日志,也可以来自 agent 自己对失败轨迹的反思。
第二,修改对象。它可以改上下文、记忆、prompt、工具描述、工作流、代码、训练数据、奖励模型,甚至模型权重。
第三,稳定变好。这才是最难的地方。一次任务上变好不够,必须证明它不是过拟合、不是碰巧、不是成本暴涨、不是把安全边界改没了。
可以用这张表先建立心智模型:
| 改进对象 | 典型形式 | 优点 | 最大风险 |
|---|---|---|---|
| 上下文 | 反思、经验、few-shot 示例 | 最容易落地,不需要训练 | 记忆污染、上下文膨胀 |
| Prompt | 自动搜索指令、生成示例 | 成本低,适合生产系统 | 评测过拟合,难解释迁移性 |
| 工具和工作流 | 自动设计 agent 流程、工具调用顺序 | 直接影响 agent 能力上限 | 搜索空间大,回归难 |
| 代码 | agent 修改自己的工具、脚手架、执行逻辑 | 最接近“改自己” | 运行不可信代码,安全要求高 |
| 训练数据 | 自生成数据、自评奖励 | 可积累成模型能力 | 数据坍缩、奖励欺骗 |
| 模型权重 | SFT、DPO、RL、test-time update | 可能带来持久能力提升 | 遗忘、成本、线上安全和回滚 |
这也是为什么我不建议把 self-improving agent 简单理解成“模型越用越聪明”。真正可讨论的是:它改的是哪一层,反馈从哪里来,改完怎么验证。
第一阶段:反思,不改权重
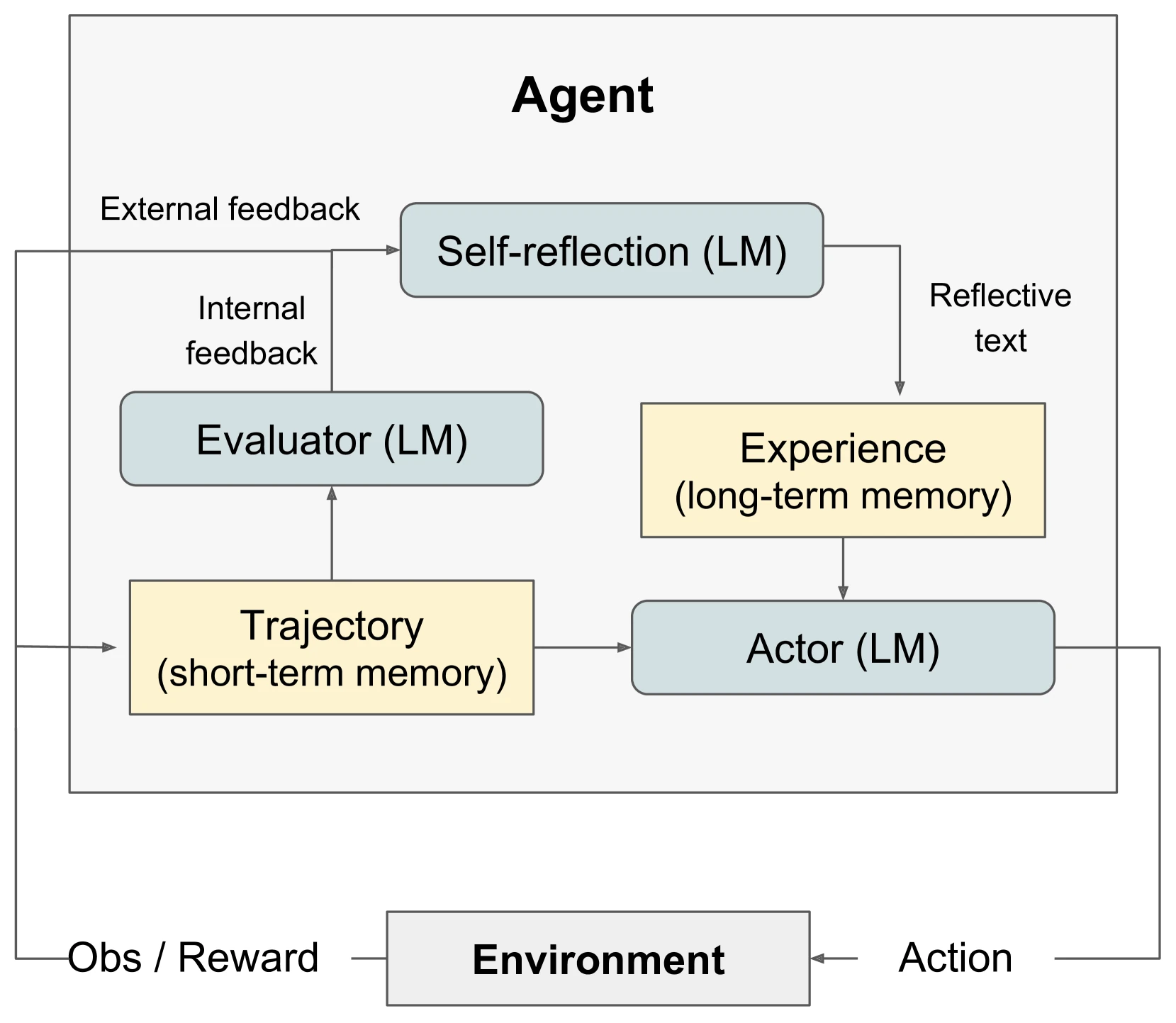
早期最有代表性的路线,是让模型在失败后写下反思,再把反思放回上下文。
Reflexion 的核心思想就是:agent 不通过梯度更新学习,而是把任务反馈转成语言反思,存进 episodic memory,下次遇到类似任务时再利用。它的意义不是某个具体 benchmark 分数,而是把“试错学习”从传统 RL 的参数更新,变成了 agent 可以马上使用的语言记忆。
Self-Refine 更直接:模型先生成答案,再给自己的答案提反馈,再基于反馈改写。这个模式现在已经变成很多 agent 框架里的基础模块:先做、再审、再改。
STaR 则走训练数据路线:模型先生成推理过程,筛掉错误答案,保留能导向正确答案的 rationale,再用这些 rationale 去训练模型。它不是完整 agent,但它给了后面很多 self-improvement 方法一个关键启发:模型可以从自己的成功轨迹中蒸馏训练信号。
这类方法的优点是简单,缺点也明显:反思不等于改进。模型很擅长写一段看起来合理的复盘,但如果没有外部验证,它可能只是更会解释自己的错误。
所以反思型 agent 的边界很清楚:它适合做短周期的行为修正,不适合被当成长期能力增长的证明。
第二阶段:把经验变成技能库
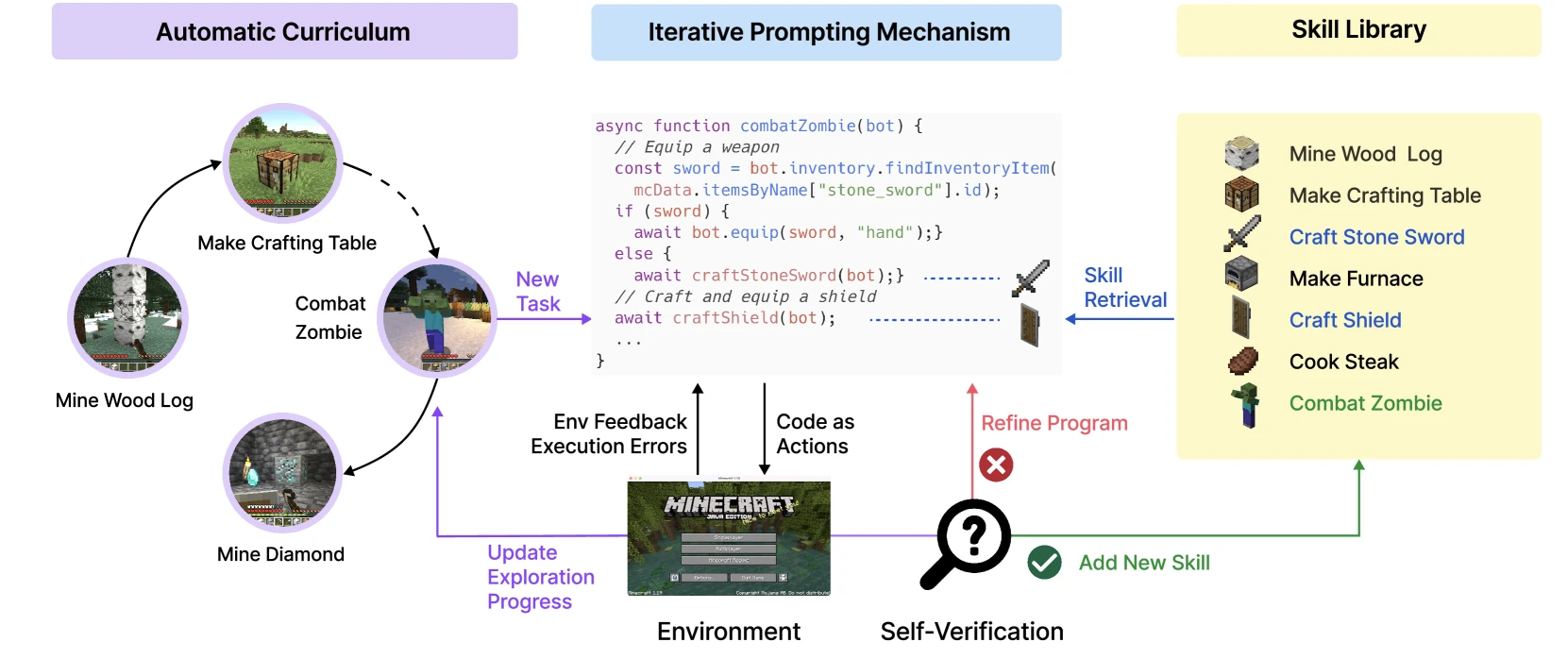
Voyager 是我认为必须读的一篇。它把 self-improving agent 从“答案改写”推进到“技能积累”。
Voyager 在 Minecraft 环境中做三件事:
- 自动生成探索 curriculum。
- 把成功行为保存成可执行代码技能。
- 根据环境反馈、执行错误和自我验证迭代改进程序。
这里最重要的不是 Minecraft,而是“技能库”这个结构。它让 agent 的改进不只是下一次 prompt 变长,而是沉淀成可检索、可组合、可复用的程序资产。
这对真实产品很有启发。很多团队说要做自进化 agent,实际第一步不应该是训练模型,而是把 agent 每次完成任务的轨迹整理成三类资产:
| 资产 | 例子 | 复用方式 |
|---|---|---|
| 成功路径 | 某类问题的稳定步骤 | 作为 workflow 模板 |
| 失败教训 | 哪些工具顺序会出错 | 作为 guardrail 或反例 |
| 可执行技能 | 脚本、函数、命令、操作说明 | 进入工具库或 skill library |
也就是说,一个实用的 self-improving agent,首先应该像一个会写工作日志的工程师,而不是像一个每晚偷偷训练自己的模型。
第三阶段:自动优化 prompt 和 workflow
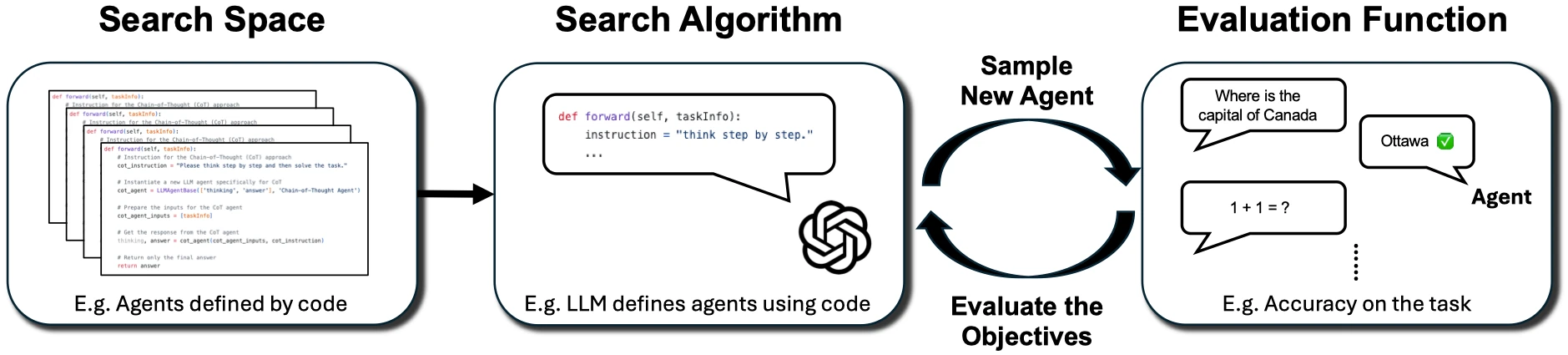
到了 2024 到 2025 年,一个重要变化出现了:大家开始不满足于让 agent “反思”,而是让 agent 自动设计 agent。
OPRO 把 LLM 当优化器,让模型根据历史候选解和分数提出下一批候选。这个思想后来被很多 prompt optimizer 继承:不要手调 prompt,而是定义任务、数据集和指标,让系统搜索更好的指令。
DSPy 的 MIPROv2 和 GEPA 把这件事做得更工程化。尤其是 GEPA,它强调不要只看一个标量分数,而要让模型读取完整 execution trace,用自然语言诊断失败原因,再演化 prompt。这个方向很适合真实 agent,因为 agent 的失败往往不是“最终答案错了”这么简单,而是工具选错、检索错、路由错、格式错、中间状态错。
ADAS 提出 Automated Design of Agentic Systems:让一个 meta agent 在代码空间里发明新的 agent 设计,包括 prompt、工具使用、控制流和组合方式。AFlow 则把 agent workflow 表示成代码里的节点和边,用搜索方法自动修改和评估 workflow。
这个方向的关键不是“模型会不会写漂亮 prompt”,而是:agent 的结构本身变成了可搜索、可评测、可迭代的对象。
这对工程实践很重要。因为真实 agent 的瓶颈经常不在单次回答,而在系统结构:
- 要不要先检索再规划?
- 工具失败后是重试、换工具,还是问用户?
- 多 agent 是串行协作,还是由一个 coordinator 分配?
- 哪些信息应该进短期上下文,哪些应该进入长期记忆?
- 什么时候停止,什么时候继续探索?
过去这些问题靠人设计。self-improving agent 的研究正在把这些问题变成搜索问题。
第四阶段:改自己的代码
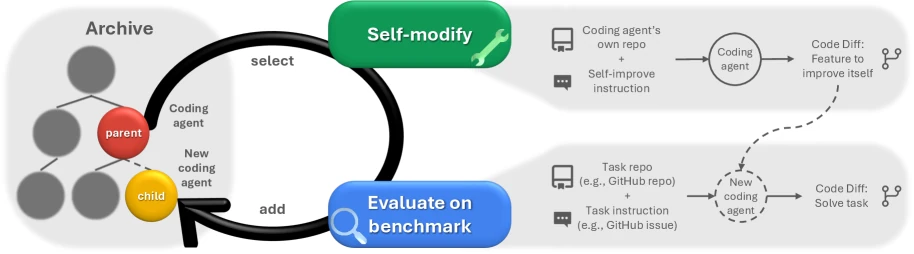
如果说 ADAS 是让 meta agent 设计 agent,那么 A Self-Improving Coding Agent 和 Darwin Godel Machine 就更接近字面意义上的“agent 改自己”。
Darwin Godel Machine:开放式演化的自改进 Agent
一个会迭代修改自身代码,并用 SWE-bench、Polyglot 等编程基准验证改进的自改进 coding agent。
A Self-Improving Coding Agent 展示了一个 coding agent 如何编辑自身实现,并在 SWE-bench Verified、LiveCodeBench 等任务上获得提升。DGM 更进一步:它维护一个 agent archive,从已有 agent 中采样,再让 foundation model 生成新变体,用 benchmark 验证后保留高质量分支。
DGM 最值得注意的地方有两个。
第一,它不是单一路径爬山,而是保留多条演化分支。这样可以避免某一次改动短期有效但长期锁死方向。
第二,它改进的不是底层 foundation model,而是 agent 的外部结构:编辑工具、上下文管理、peer review 机制、patch validation 等。换句话说,它证明的不是“模型会自己训练出更聪明的大脑”,而是“冻结模型之上,agent 脚手架仍然有很大可优化空间”。
这也更接近今天产品团队能做的事情。你不一定能训练一个新模型,但你可以让 agent 在沙箱里生成 PR,跑测试,比较指标,保留有效改动,再由人审查合并。
不过,这条路线的安全门槛很高。DGM 的仓库也明确提醒:运行模型生成代码有风险。真实系统必须有沙箱、权限边界、资源限制、测试集隔离、回滚机制和人工审批。
第五阶段:让模型生成自己的训练信号
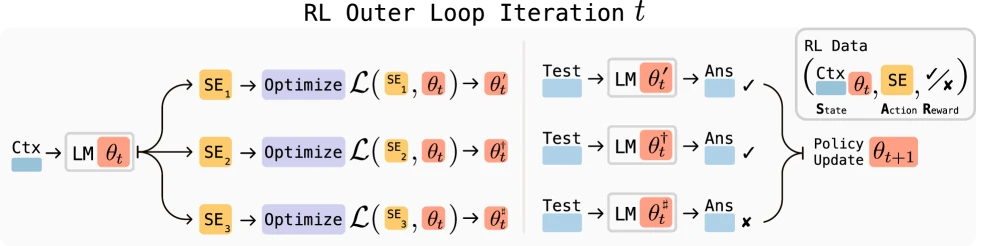
另一条更接近模型训练的路线,是让模型参与生成自己的数据、奖励或更新指令。
Self-Rewarding Language Models 用 LLM-as-a-judge 让模型给自己的输出提供奖励信号,再通过 Iterative DPO 训练。它的核心问题很有野心:如果未来模型需要超过人类水平的反馈,那能不能让模型自己逐步提升反馈质量?
SEAL: Self-Adapting Language Models 更进一步,让模型生成 self-edit:这些 self-edit 可以是合成训练数据、信息重写方式、优化超参数,甚至调用数据增强和梯度更新工具。模型通过下游任务表现作为 reward,学习怎样生成更有效的 self-edit。
SEAL:自适应语言模型
让语言模型根据新任务或新知识生成自己的微调数据和更新指令,从而产生持久权重更新。
还有 Self-Improving LLM Agents at Test-Time 这种 test-time self-improvement:模型先识别自己不确定的样本,再围绕这些样本生成相似训练例,做轻量的临时参数更新,最后恢复原始参数。这个方向很有意思,因为它把“学习”推到了推理现场。
但越接近权重更新,越要谨慎。
因为模型权重一旦被错误数据、自评偏差或恶意输入污染,问题就不再是某次回答错了,而是系统本身变了。对普通产品团队来说,长期记忆、prompt 优化、workflow 搜索和沙箱代码改进,比在线自改权重更现实。
最接近生产实践的是 AlphaEvolve
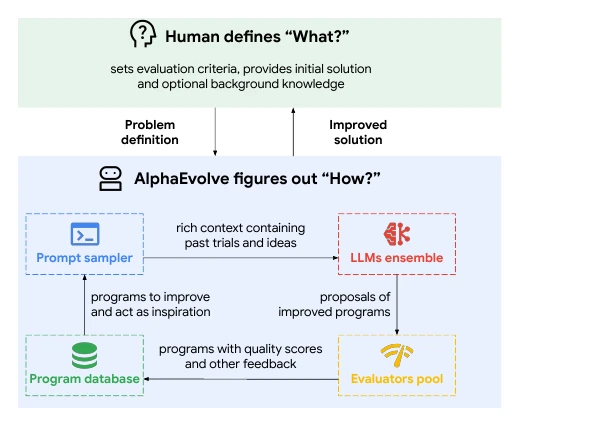
如果要看 self-improving agent 的生产形态,AlphaEvolve 是目前最值得研究的案例之一。
AlphaEvolve:用于科学和算法发现的 coding agent
一个通过代码修改、自动评估器和演化式程序数据库来改进算法的 coding agent。
AlphaEvolve 的核心结构很朴素:
生成候选程序
运行和评分
把高分程序放入数据库
根据数据库继续采样和变异
重复它厉害的地方不在“让模型想一想”,而在任务选择非常适合自动评测:算法、调度、硬件电路、矩阵乘法、GPU kernel。只要候选程序能运行、能验证、能打分,agent 就可以大规模探索。
Google DeepMind 披露的实践也很具体:AlphaEvolve 发现的调度启发式已经在 Google 数据中心使用,平均持续回收 0.7% 的全球计算资源;它还用于 TPU 电路简化、Gemini 训练相关 kernel 优化,以及数学和算法发现。
这给 self-improving agent 一个非常重要的现实判断:
最先落地的自改进,不会出现在“什么都能做”的通用助手里,而会出现在评测清晰、反馈便宜、错误可回滚的窄领域。
代码、算法、编译器优化、数据处理 pipeline、测试生成、检索排序、客服路由、内部运营流程,都比开放式聊天更适合自改进。
真正的分水岭是 eval
研究 self-improving agent,最后都会回到评测。
OpenAI 的 agent eval 文档把这件事说得很工程化:agent workflow 的评测应该看 traces、graders、datasets 和 eval runs。也就是说,不只是看最终回答,而是看完整轨迹:模型调用、工具调用、handoff、guardrail、路由、失败点。
这和 self-improving agent 完全一致。因为 agent 要改进自己,必须先知道自己哪里坏了。
一个最低限度的自改进闭环应该长这样:
生产或测试轨迹
↓
失败归因:工具错、检索错、计划错、格式错、权限错、停止时机错
↓
生成候选改动:prompt / workflow / tool schema / memory rule / code patch
↓
离线评测:固定数据集 + 回归集 + 成本和延迟
↓
沙箱验证:真实工具但限制权限
↓
人工审查或自动灰度
↓
写入版本化资产如果没有这套东西,所谓自改进就容易变成“把失败案例喂回 prompt”。短期看似变好,长期会产生三个问题:
- 过拟合最近的失败:今天修了 A,明天破坏 B。
- 奖励欺骗:agent 学会迎合 grader,而不是解决真实问题。
- 边界漂移:为了完成任务,悄悄扩大权限、跳过确认、隐藏不确定性。
所以我会把 eval 看成 self-improving agent 的地基,而不是附属工具。
安全问题不是以后才需要
越是强调自改进,越不能把安全放到最后。
Anthropic 在 2026 年 2 月发布的 Measuring AI agent autonomy in practice 里提到两个值得注意的趋势:Claude Code 最长尾的自主工作时长在几个月内显著增长;有经验的用户更常开启自动批准,但也更常在过程中打断。这说明真实世界里的 agent 不是简单走向“全自动”,而是走向“更长时间自主工作 + 人类在关键时刻介入”。
对 self-improving agent 来说,这个观察很关键。
一个会改自己的 agent,不能只有“提高成功率”的目标,还要同时优化这些约束:
| 约束 | 需要回答的问题 |
|---|---|
| 权限 | 它能改哪些文件、调用哪些工具、访问哪些数据? |
| 可回滚 | 每次自改动是否有版本、diff、测试和回滚点? |
| 可解释 | 它为什么认为这个改动会变好?证据是什么? |
| 反作弊 | 评测集是否隔离?grader 是否容易被 prompt injection 操纵? |
| 人类介入 | 哪些改动必须停下来等人确认? |
| 线上监控 | 改动上线后是否继续跟踪质量、成本、风险和投诉? |
我甚至觉得,真正成熟的 self-improving agent 产品,不会宣传“完全自治”。它会宣传“可监督的自治”:系统自己发现问题、提出改进、完成大部分验证,但关键权限和长期状态由人类或组织策略控制。
如果要自己做,应该从哪里开始
如果我今天要在一个真实产品里做 self-improving agent,我不会从训练模型开始。我会按五层推进。
第一层:把轨迹记录完整
先记录每次 agent run 的输入、上下文版本、prompt 版本、工具 schema、工具调用、返回结果、错误、最终输出、用户反馈和人工修改。没有轨迹,就没有学习材料。
第二层:建立固定 eval 集
从真实失败案例里抽样,做一个不会被日常开发随便污染的 eval set。至少分三类:
| 类型 | 用途 |
|---|---|
| 黄金任务 | 核心能力不能退化 |
| 失败回归 | 修过的问题不能复发 |
| 压力任务 | 长链路、多工具、高权限、模糊需求 |
第三层:先优化 prompt 和工具描述
这是成本最低、风险最低的一层。可以用 GEPA、DSPy、OPRO 类思路,也可以先做简单的候选 prompt 搜索。关键是每个候选都必须跑同一套 eval,不要靠肉眼感觉。
第四层:优化 workflow
当 prompt 优化到一定程度,问题通常会暴露在流程上。比如检索位置不对、工具失败后没有恢复策略、agent 太早停止或太晚停止。这时可以引入 AFlow/ADAS 类思路,把 workflow 表示成可修改对象,再做离线搜索。
第五层:让 agent 生成代码改动,但必须走 PR 流程
这是最接近 DGM/SICA 的层。agent 可以提出代码 patch,但 patch 应该像普通工程改动一样经过测试、review、权限限制和灰度。不要让它直接改生产系统。
至于在线改权重,我认为大多数团队现在不应该碰。除非你已经有很成熟的数据治理、评测体系、模型训练能力和回滚机制,否则它带来的运维复杂度会远高于收益。
论文阅读路线
如果只是泛泛搜 self-improving agent,很容易被术语淹没。我建议按这条路线读:
- Self-Refine 和 Reflexion:理解最轻量的反思闭环。
- STaR 和 Self-Rewarding Language Models:理解自生成训练信号。
- Voyager:理解技能库和开放式环境里的持续积累。
- OPRO、GEPA、TextGrad:理解自然语言反馈如何优化 prompt、代码和系统组件。
- ADAS 和 AFlow:理解 agent workflow 如何被自动设计。
- A Self-Improving Coding Agent 和 DGM:理解 agent 如何修改自己的实现。
- SEAL 和 Self-Improving LLM Agents at Test-Time:理解权重更新和 test-time adaptation。
- AlphaEvolve:理解最接近生产价值的演化式 coding agent。
- A Survey of Self-Evolving Agents:最后再读综述,把概念放回完整分类。
Self-Evolving Agents 综述
一篇按“改什么、什么时候改、怎么改”梳理 self-evolving agent 的系统综述。
我的判断
Self-improving agent 最容易被误读成一个 AGI 叙事:模型自己改自己,然后能力指数上升。
但从现在的论文和实践看,更可靠的判断是:
self-improving agent 的近期价值,不是替代模型训练,而是把 agent 工程从手工调参推进到评测驱动的自动优化。
它的核心资产不是“更聪明的模型”,而是一个能闭环的系统:
- 有真实任务轨迹。
- 有可执行评测。
- 有可版本化的 prompt、workflow、tool、memory 和 code。
- 有自动生成候选改动的机制。
- 有安全边界、回归测试和人工审批。
这件事听起来没有“递归自我进化”那么刺激,但更重要。因为它把 agent 从一次性 demo 变成一个可以长期维护的系统。
如果未来 agent 真的会持续变强,大概率也不是从一个神秘瞬间开始,而是从这些看起来很工程化的闭环开始:每次失败都被记录,每次改动都被评测,每次有效经验都被固化,每次越界尝试都被拦住。
真正的 self-improving agent,不是一个会说“我已经反思了”的 agent。
它应该是一个能证明“我这次改动确实让系统变好了,而且没有破坏边界”的 agent。